Microsoft представила модель Phi-4-reasoning с 14 миллиардами параметров, которая демонстрирует исключительную производительность на сложных задачах рассуждения, превосходя модели, превышающие её по размеру в 5-47 раз, и требуя значительно меньше вычислительных ресурсов. Разработчики могут получить доступ к модели напрямую через репозиторий Microsoft на Hugging Face и GitHub Models, где можно протестировать модель в playground или интегрировать через GitHub API.
Технические инновации Phi-4
Phi-4-reasoning сохраняет ту же архитектуру, что и базовая модель Phi-4, с двумя ключевыми модификациями. Команда переназначила плейсхолдер-токены в качестве специальных маркеров (<think> и </think>) для разграничения секций рассуждения, позволяя модели явно отделять процесс мышления от финального ответа. Также они расширили длину контекстного окна с 16K до 32K токенов, предоставляя модели больше пространства для развёрнутых цепочек рассуждений. Эти архитектурные решения в сочетании с тщательно отобранными данными для обучения раскрыли новые возможности рассуждения.
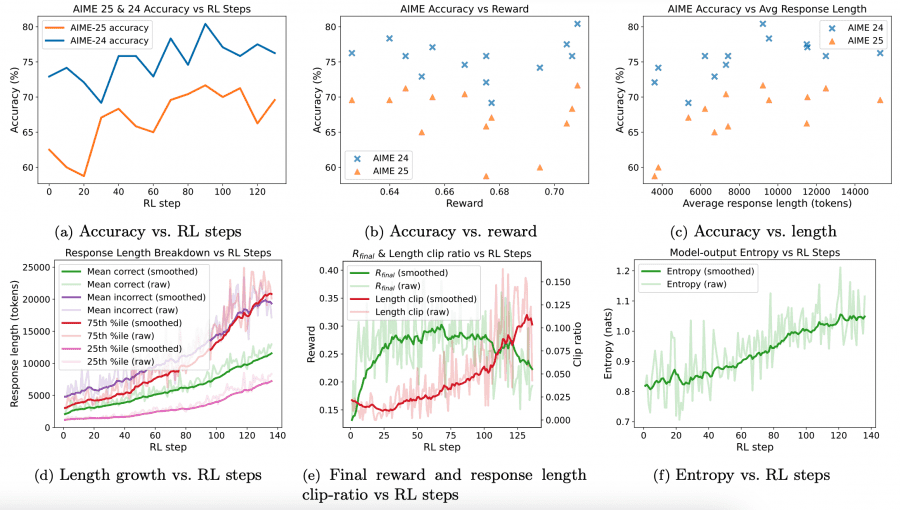
Развитие на этом не остановилось. Microsoft также создала Phi-4-reasoning-plus, которая прошла дополнительное обучение с подкреплением на математических задачах. Эта улучшенная версия генерирует более длинные и тщательные цепочки рассуждений, что приводит к повышению точности на 15% на бенчмарке AIME 2025 и на 5% на OmniMath поскольку она использует больше вычислительных ресурсов во время инференса, генерируя в 1,5 раза больше токенов, чем Phi-4-reasoning.
Впечатляющие метрики производительности
Улучшения производительности по сравнению с базовой моделью Phi-4:
- Математические рассуждения: +50 процентных пунктов на AIME 2025 (с 12,9% до 78,0%);
- Кодинг: +25 пунктов на LiveCodeBench (с 28,0% до 53,8%);
- Алгоритмическое решение задач: +30-60 пунктов на таких задачах как TSP, 3SAT и Calendar Planning;
- Общие задачи: +22 пункта в следовании инструкциям, +16 пунктов в ответах на вопросы с длинным контекстом, +10 пунктов в чат-взаимодействиях.
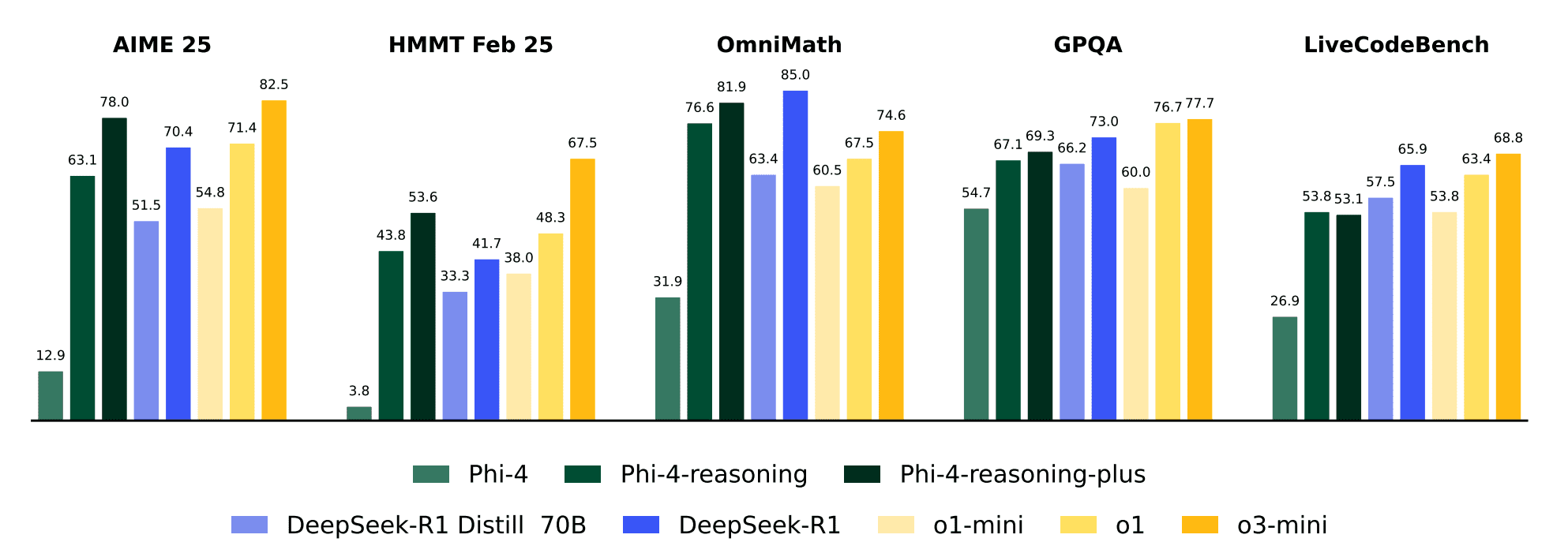
Несмотря на свой относительно скромный размер в 14 миллиардов параметров, Phi-4-reasoning-plus эффективно конкурирует с отраслевыми гигантами, такими как DeepSeek-R1 (671 миллиард параметров), и превосходит o1-mini и DeepSeek-R1-Distill-Llama-70B по большинству бенчмарков приближаясь к производительности полной модели DeepSeek R1.
Датацентричный подход
Секрет этих впечатляющих результатов заключается в датацентричном подходе Microsoft. Вместо простого увеличения размера модели команда тщательно отобрала более 1,4 миллиона пар «запрос-ответ», которые раздвигают границы возможностей Phi-4. Они сосредоточились на задачах, требующих многоэтапного рассуждения, а не простого воспроизведения фактов, создавая тренировочный датасет, специально нацеленный на развитие навыков рассуждения.
Для Phi-4-reasoning-plus они применили обучение с подкреплением на 6400 тщательно отобранных математических задачах, используя алгоритм Group Relative Policy Optimization (GRPO). Этот дополнительный этап научил модель исследовать множественные пути решения перед принятием окончательного ответа, дополнительно улучшив её способности к рассуждению.
За пределами специализированных задач
Возможно, наиболее примечательно то, что улучшения в способностях к рассуждению распространились за пределы специализированных задач и усилили общий интеллект модели. Следование инструкциям, ответы на вопросы с длинным контекстом, чат-взаимодействия и даже обнаружение токсичного контента — всё это показало существенные улучшения. Это свидетельствует о том, что обучение модели более тщательному рассуждению улучшает её общие способности, а не только производительность в узких областях.
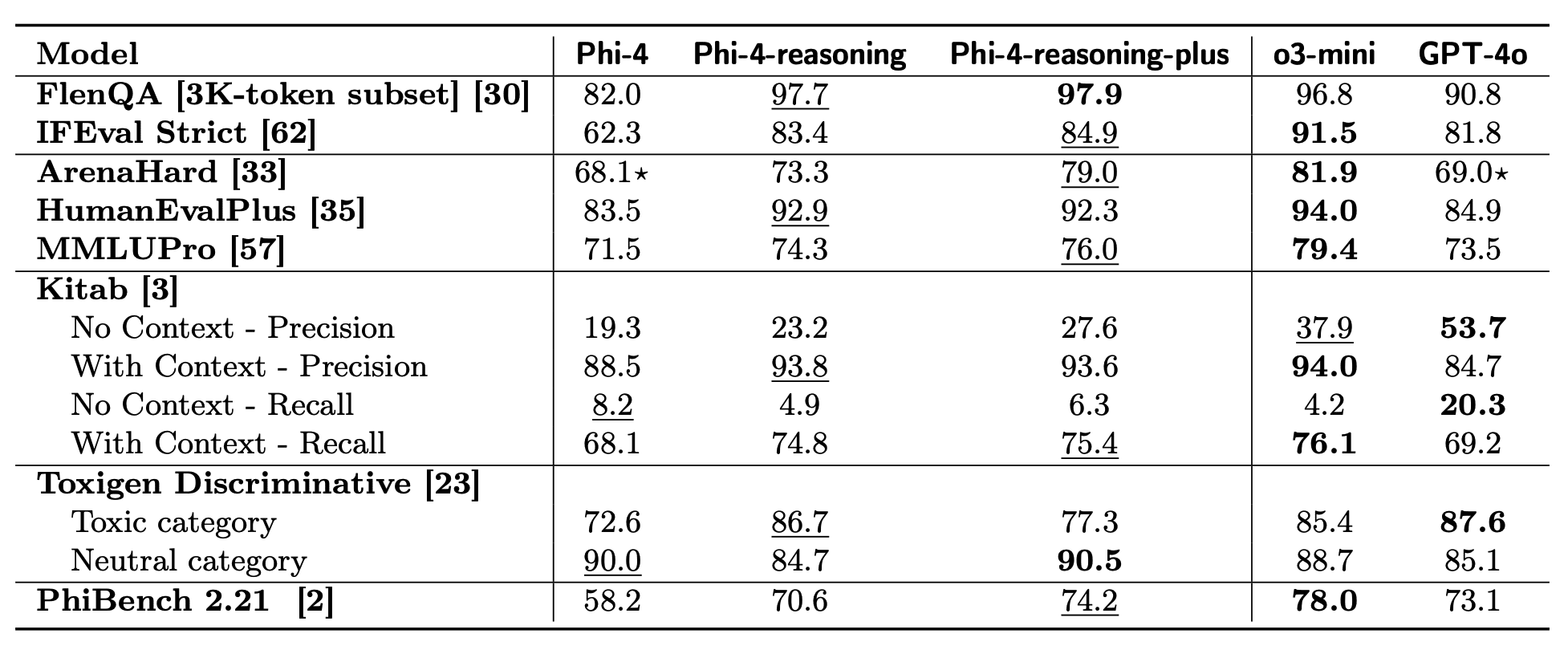
Модель выпущена под permissive MIT-лицензией, что позволяет использовать её для коммерческих и корпоративных приложений, fine-tuning или дистилляции без ограничений. Эта открытая доступность способствует демократизации доступа к продвинутому AI с возможностями рассуждения для разработчиков по всему миру. Модель совместима с фреймворками vLLM, llama.cpp и Ollama, что делает её разносторонне доступной.
Модели Phi-4-reasoning от Microsoft демонстрируют, что будущее развития искусственного интеллекта может заключаться не только в построении всё более крупных нейронных сетей, но и в обучении более компактных моделей эффективнее мыслить — подобно тому, как люди развивают экспертизу через целенаправленную практику, а не просто увеличивая объем прочитанной литературы. Это убедительный аргумент в пользу работы более специализированным, а не просто более масштабным образом в стремлении к созданию более совершенных систем искусственного интеллекта.