
NVIDIA опубликовала код предобученной модели StyleGAN для генерации лиц, которые никогда не существовали. StyleGAN является state-of-the-art моделью с лучшими свойствами интерполяции и распутывания, способностью находить скрытые факторы вариации (определять положение лица и идентичность).
Мы писали об анонсе StyleGAN 18 декабря прошлого года, но тогда NVIDIA не показала готовую реализацию этой сети. Теперь код находится в открытом доступе и лежит в репозитории на GitHub и мы можем более подробно проанализировать метод и его результаты.
UPD: актуальная версия (StyleGAN3) опубликована в репозитории на Github.
Идея
Улучшения GAN чаще всего измеряются разрешением и качеством сгенерированных изображений. Несмотря на прогресс в достижении этой цели, генеративные сети всё еще остаются черными ящиками. Не считая единичных попыток понять внутреннюю структуру генеративно-состязательных сетей, большинство исследователей всё еще занимаются оптимизацией для получения изображений более высокого качества, используя GAN. Но скрытые свойства и представления таких сетей до сих пор плохо изучены.
Недавно была опубликована работа, в которой авторы попытались вскрыть генеративно-состязательные сети и выяснить их внутренние представления.
В новом методе, предложенном NVIDIA, архитектура генератора переделывается так, что открываются новые способы контролировать процесс генерации изображения. Фактически генератор StyleGAN начинает с изученного постоянного входа, а дальше регулирует “стиль” изображения на каждом сверточном слое. Таким образом генератор способен напрямую контролировать значимость признака изображения в различных масштабах. Цель этой архитектуры — определить скрытые факторы вариации и тем самым увеличить уровень контроля.
Архитектура StyleGAN
Говоря простым языком, архитектура StyleGAN пытается отделить высокоуровневые атрибуты изображения (положения лица, личность человека) от случайных вариационных факторов, таких как прическа, веснушки и тому подобное. Отмечу, что когда я говорил об архитектура генератора, я имел ввиду сеть генератора (как одну из частей GAN). Это различие очень важно понимать, так как исследователи из NVIDIA модифицировали только процесс синтеза изображения (генератор), а не дискриминатор.
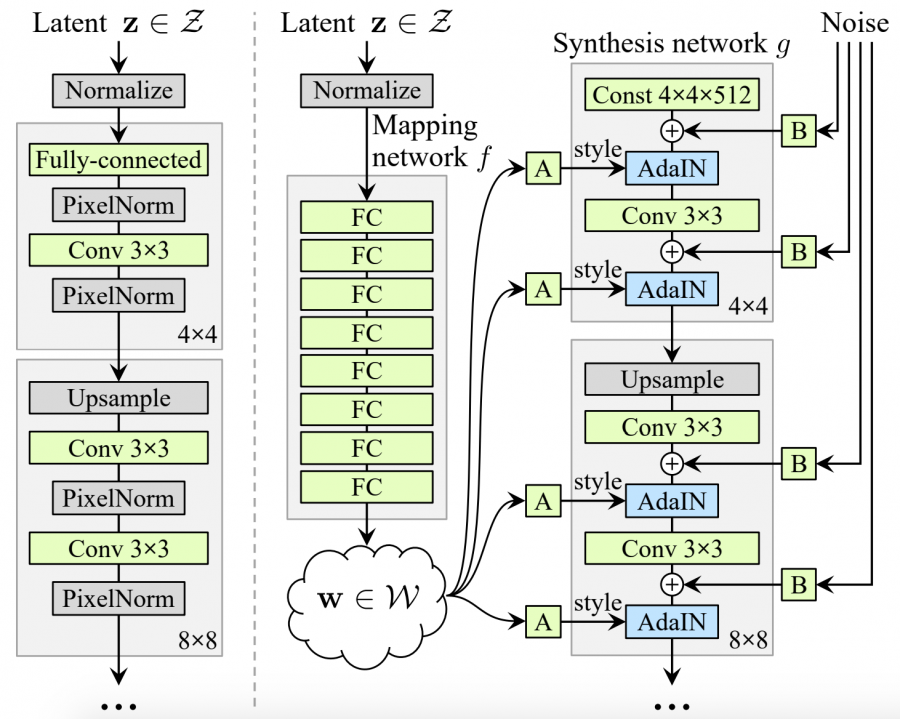
В основе архитектуры лежит идея о встраивании входного скрытого кода в промежуточное скрытое представление, которое, предположительно, имеет сильное влияние на то, как в сети представлены факторы вариации. Исследователи утверждают, что промежуточное скрытое пространство свободно от таких ограничений, следовательно, может быть распутано.
Эта операция выполняется с использованием изученного нелинейного преобразования, которое производит модифицированный скрытый вектор. Модифицированный вектор далее адаптируется к различным стилям при помощи аффинных преобразований. Cтили представляют из себя модификации вложения скрытого вектора, которые в каждом сверточном слое будет использоваться для контроля операции нормализации.
Нормализация входов на сверточных слоях
Каждый вход сверточного слоя нормализуется с помощью операции AdaIN (adaptive instance normalization) с использованием вложений “стиля” скрытого вектора. Наконец, в сеть встраивается дополнительный шум для генерации случайных элементов на изображениях. Этот шум — просто одноканальное изображение, состоящее из некоррелированного гауссова шума. Шум подается перед каждой операцией AdaIN на каждый сверточный слой. Более того, существует фактор масштаба для шума, который обучается для каждого признака.

Результаты
Так как основная задача метода — возможность распутывания (disentanglement) и интерполяции генеративной модели, возникает вопрос: “Что происходит с качеством и разрешением изображения?”.
Исследователи показали, что радикальная перестройка архитектуры генератора не ухудшает качество сгенерированного изображения, а наоборот существенно его улучшает. Поэтому не нужно было искать компромисс между качеством и интерполяционными возможностями.

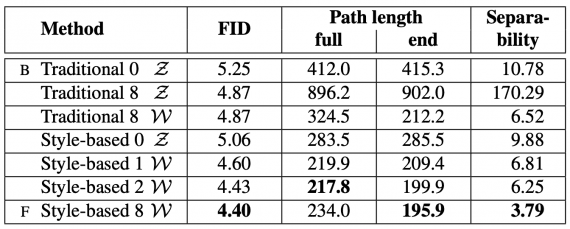
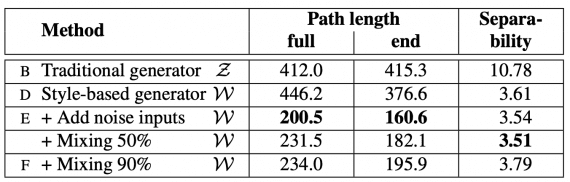
Помимо архитектуры исследователи показали два новых автоматических метода для количественной оценки качества интерполяции и распутывания, а также представили новый датасет с человеческими лицами. Эксперименты проводились сразу на CelebA-HQ и новом датасете FFHQ. Было показано, что StyleGAN превосходит традиционные генеративно-состязательные сети и достигает state-of-the-art результата в традиционных метриках. В таблице представлено сравнение StyleGAN с традиционной GAN в качестве бэйзлайна.

- Эксперименты по генерации других несуществующих объектов показали неплохие рельзультаты:

Новые объекты, сгенерированные StyleGAN

Код StyleGAN
На текущий момент StyleGAN является наиболее мощной моделью генеративно-состязательной нейронной сети, которая показывает впечатляющие видимые результаты. Исследователи из NVIDIA смогли достигнуть этого при помощи нескольких простых модификаций архитектуры. Они улучшили качество распутывания и интерполяции, сохранив при этом качество и разрешение изображения. Представленный компанией код сети StyleGAN можно найти здесь вместе с предварительно обученной моделью. Новый датасет FFHQ также находится открытом доступе.






