VFusion3D — метод генерации 3D-модели из одного изображения, который использует модели диффузии видео, чтобы избежать нехватки данных для обучения. Благодаря дообучению предобученной модели видео-диффузии, VFusion3D генерирует масштабные синтетические наборы данных с несколькими ракурсами, что значительно повышает качество 3D моделей. На входе подается одно изображение, на выходе через 17 секунд модель генерирует меш в формате .obj и видео-демонстрацию весом до 100кб. Протестировать работу модели можно на Huggingface. Код опубликован на Github.

Метод
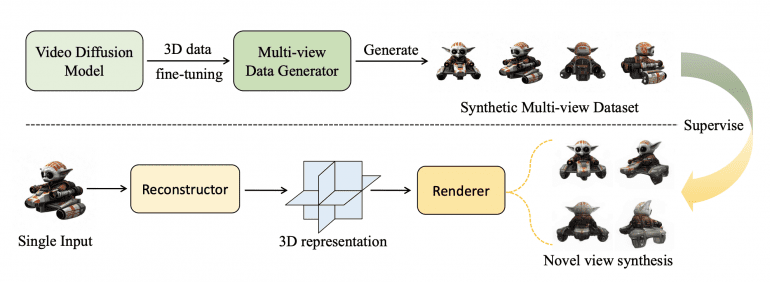
VFusion3D преобразует модель видео-диффузии в генератор 3D данных с несколькими ракурсами. Модель EMU Video, дообученная на 100K 3D объектов, генерирует 3 миллиона синтетических видео с несколькими ракурсами. Эти видео используются для обучения генеративной 3D модели, создающей стабильные 3D объекты из отдельных изображений.
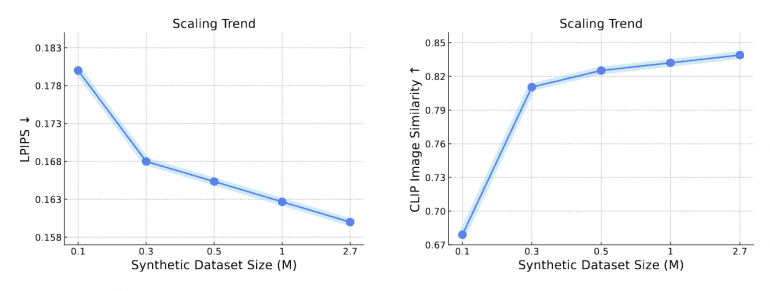
Авторы доказали, что синтетические данные заметно улучшают результаты модели:
Результаты
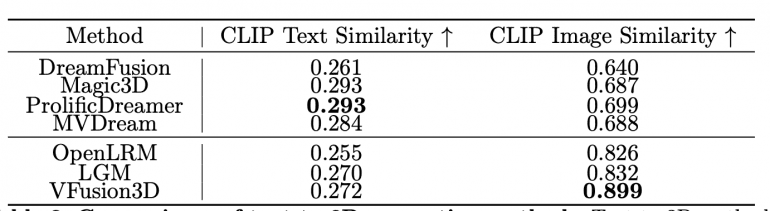
VFusion3D превосходит существующие модели, такие как OpenLRM и LGM, как по 3D согласованности, так и по визуальной точности. Модель достигает более высоких значений CLIP Image и Text Similarity, что свидетельствует о лучшем соответствии входным данным. 90% людей предпочитают результаты VFusion3D другим моделям.
Производительность и скорость
VFusion3D не только создает высококачественные 3D модели, но и делает это эффективно. Она может сгенерировать 3D объект из одного изображения за 17 секунд, что значительно быстрее традиционных методов, которые часто работают медленнее и менее стабильно.
Входные данные:

Результат (видео +мэш в формате obj):
Масштабируемость
Метод позволяет масштабируемо создавать 3D объекты, что идеально подходит для таких отраслей, как игры и AR/VR. Способность быстро генерировать довольно качественные 3D объекты из минимальных входных данных устанавливает новый стандарт в 3D генеративном моделировании.
VFusion3D решает проблему нехватки 3D данных, используя модели видео-диффузии для создания масштабируемых, высококачественных 3D объектов. По мере развития VFusion3D ее способность быстро генерировать согласованные 3D модели из одного изображения, вероятно, станет драйвером дальнейших инноваций в создании 3D контента.