Исследователи из NVIDIA и лаборатории Computer Science & AI из MIT представили новый метод синтеза video-to-video, который показывает впечатляющие результаты. Предложенный метод — Vid2Vid — позволяет синтезировать высококачественные, фотореалистичные, плавные видео из различных входных данных, включая маски сегментации, скетчи и образы.
Предыдущие работы
Утверждая, что универсальное решение для video-to-video генерации еще не изучено (в отличие от соответствующей задачи в image-to-image генерации), исследователи установили сильный baseline для данного алгоритма, который комбинирует новейшие алгоритмы передачи видеопотока image-to-image преобразования.
Идея
Главная идея состоит в том, чтобы обучить функцию переноса, которая смогла бы конвертировать входящий видеопоток в реалистичный выходной. Они переформулировали задачу, как задачу сопоставления распределений. Они используют GAN, чтобы получить метод, который сможет создавать фотореалистичные видео на основе входного видео.

Метод Vid2Vid
Авторы смогли решить сложную проблему video-to-video преобразования (или video-to-video генерации) путем аккуратной настройки генеративно-состязательной сети.
Их целью было получить такую функцию преобразования, которая будет преобразовывать входящий поток изображений в серию фотореалистичных изображений. Условное распределение сгенерированной последовательности при данной исходной последовательности совпадает с условным распределением исходной последовательности при данной исходной последовательности:
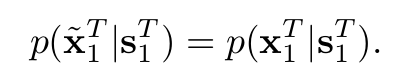
Совпадение распределений заставляет сеть выдавать реалистичные и согласованные во времени выходные видеокадры. В контексте GAN, фреймворк Генератор-Дискриминатор спроектирован для обучения функции преобразования. Генератор обучается решению оптимизационной задачей — минимизация расстояния Дженсона-Шеннона. Минимакс оптимизация применяется к заданной целевой функции:
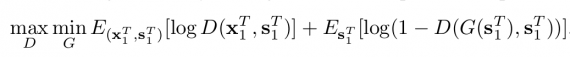
Как было сказано в работе, оптимизация такой целевой функции весьма нетривиальная задача. Часто обучение моделей генератора и дискриминатора получалось очень нестабильным или даже невозможным, в зависимости от решаемой задачи оптимизации. Поэтому в своих исследованиях они предлагают упрощенный генератор. Они делают предположения о марковском свойстве, чтобы факторизовать условное распределение и отделяют зависимости между кадрами в последовательностях.
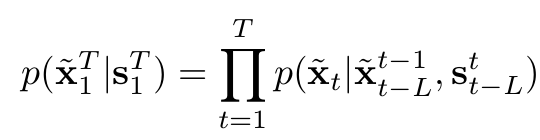
Проще говоря, они упрощают задачу , предполагая, что видеокадры могут быть сгенерированы последовательно и генерация t кадра зависит только от 3-х вещей:
- Текущее исходное изображение;
- Предыдущие L исходных изображений;
- Последние L сгенерированных изображений.
Основываясь на этом, они спроектировали сеть прямого распространения F для обучения функции преобразования, которая из предыдущих L исходных и L-1 сгенерированных кадров создает новый кадр.
Для моделирования такой сети исследователи делают еще одно предположение, основанное на том факте, что если оптический поток от текущего кадра к следующему кадру известен, его можно использовать для деформации текущего кадра и получения оценки для следующего кадра. Считая, что это будет в значительной степени верно, за исключением окклюдированных областей (где неизвестно, что происходит), они рассматривают конкретную модель.
Оценочная сеть проектируется таким образом, чтобы учитывать маску окклюзии, оцененный оптический поток между предыдущим и текущим изображением (который задается функцией оценки оптического потока) и галлюцинированное изображение (генерируемое с нуля). Галлюцинированное изображение необходимо для заполнения областей с окклюзией.
Подобно тому, как в изображениях в контексте генеративного состязательного обучения многие методы используют локальные дискриминаторы помимо глобального, авторы предлагают интересный подход, использующий условный дискриминатор изображения и условный дискриминатор видео.
Кроме того, чтобы сделать метод еще лучше, исследователи расширяют свой подход к мультимодальному синтезу. Они предлагают генеративный метод, основанный на схеме внедрения объектов и использующий Gaussian Mixture Models для получения нескольких видеороликов с различными визуальными проявлениями в зависимости от выборки различных векторов признаков.
Результаты
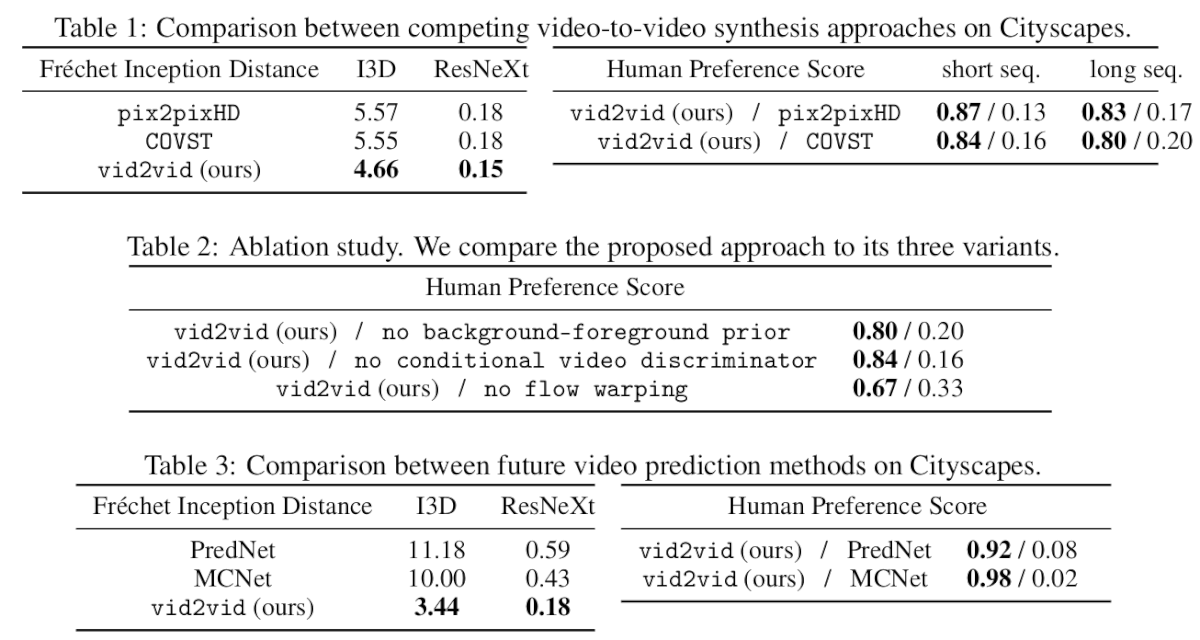
Предлагаемый метод дает впечатляющие результаты. Он был протестирован на нескольких наборах данных, таких как Cityscapes, Apolloscape, Face video dataset, Dance video dataset. Кроме того, для сравнения использовались два сильных baseline: метод pix2pix и модифицированный способ передачи стиля видео (CONVST), где они изменили сеть стилизации на pix2pix.



Сравнение с другими state-of-art
Авторы использовали как субъективные, так и объективные оценочные показатели для оценки метода: Human preference score, Fréchet Inception Distance (FID). Сравнение данных и других методов приведено в таблицах.
-

Будущие результаты видео-прогноза. Вверху слева: истина. Вверху справа: PredNet. Внизу слева: MCNet. Внизу справа: Vid2Vid.

-
Пример вывода из мультимодального видеосинтеза

Вывод
Условный подход на основе GAN показывает впечатляющие результаты в нескольких различных задачах в рамках переноса свойств из видео в видео. Существует множество применений такого рода методов в компьютерном зрении, робототехнике и компьютерной графике. Используя изученную модель синтеза видео, можно создавать реалистичные видеоролики для самых разных целей и приложений.