Würstchen — открытая text-to-image модель, которая генерирует изображения быстрее, чем диффузные модели, такие как Stable Diffusion, и при этом потребляет гораздо меньше памяти, достигая сравнимых результатов. Подход основан на пайплайне из трех моделей: text-conditional диффузная модель, энкодер/декодер изображения и VQGAN. Затраты на обучение модели снизились в 16 раз по сравнению со Stable Diffusion 1.4. Такого результата удалось добиться путем добавления этапа сжатия изображений 512×512 в 42 раза до разрешения 12×12. Демо модели доступно на Huggingface, открытый код выложен на Github.
Подробнее о методе
Метод включает в себя три этапа:
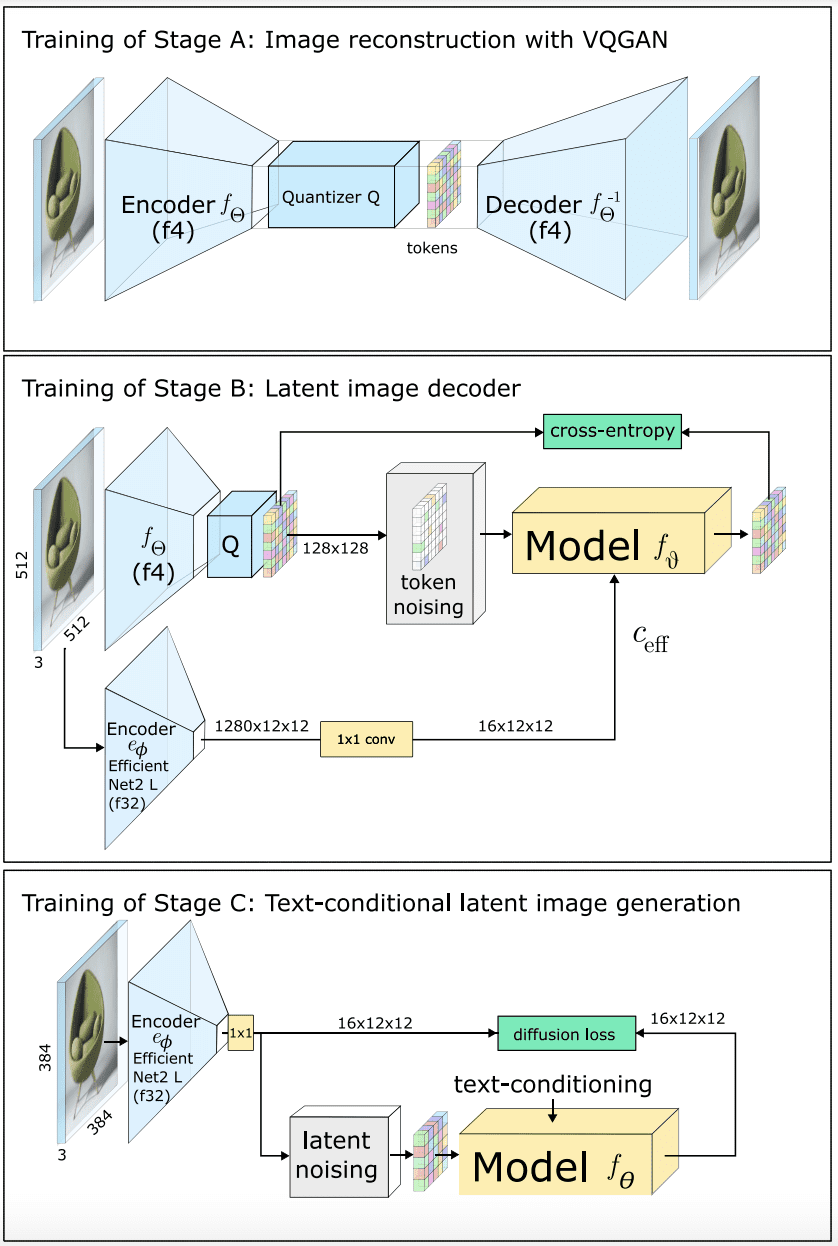
На первом этапе для генерации изображения модель EfficientNet создает изображение с высокой степенью сжатия с использованием текстово-условной модели латентной диффузии (Stage C). Затем эта репрезентация преобразуется в увеличенное и квантованное латентное пространство с помощью вторичной модели, которая отвечает за эту реконструкцию (Stage B). На третьем этапе с помощью VQGAN токены, составляющие латентное изображение на этом промежуточном разрешении, декодируются, чтобы получить выходное изображение (Stage A). Обучение этой архитектуры выполняется в обратном порядке, начиная с Этапа A, затем переходя к Этапу B и Этапу C.
Результаты Würstchen
Сравнение метрики zero-shot Fréchet Inception Distance (FID) с другими state-of-the-art методами генерации текста в изображение на разрешениях изображений 256×256 и 512×512:
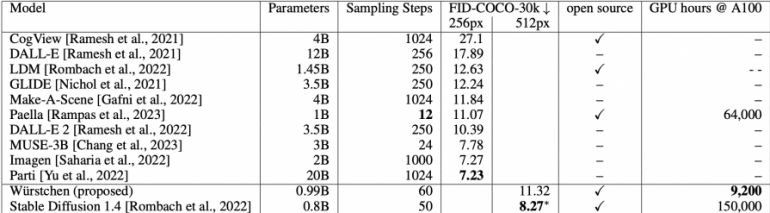
Cамый затратный этапом для обучения (этап C), потребовал всего 9200 часов работы GPU, в сравнении с 150000 часами работы GPU для Stable Diffusion 1.4.