Статья основана на реальном опыте участия в соревнованиях на Kaggle, автор — Abhay Pawar. Ссылка на оригинал в подвале статьи.
Участвовать в соревнованиях Kaggle весело и захватывающе! За последние пару лет я разработал несколько простых способов создания более совершенных моделей машинного обучения. Эти простые, но мощные методы помогли мне попасть в топ 2% соревнования Instacart Market Basket Analysis, и я также использую их вне Kaggle. Давайте рассмотрим методы поближе.
Один из наиболее важных аспектов построения любой контролируемой модели обучения для численных данных — хорошее понимание векторов признаков. Глядя на графики работы вашей модели, можно понять, как ее выходной результат зависит от различных признаков.
Но проблема с этими графиками заключается в том, что они создаются с использованием обученной модели. Если бы мы могли напрямую создавать эти графики прямо по данным для обучения, это могло бы помочь нам лучше понять принципы работы нашей сети. Фактически, графики могут помочь вам в следующем:
- Понимание признаков;
- Поиск признаков с большими шумами (самая интересная часть!);
- Разработка признаков;
- Важность признаков;
- Отладка признаков;
- Обнаружение утечек;
- Мониторинг модели.
Чтобы вы легко могли попробовать сами, я решил включить эти методы в пакет featexp на Python, и в этой статье мы увидим, как их можно использовать для исследования признаков. Мы будем использовать датасет из соревнования Kaggle Home Credit Default Risk. Задача конкурса — предсказать неплательщиков по известным данным о клиентах.
Понимание признаков

Если зависимая переменная (цель) является двоичной, строить графики бессмысленно, потому что все точки имеют значение либо 0, либо 1. Для цели с непрерывной областью значений большое количество точек затрудняет понимание взаимосвязи цели и признаки. Featexp создает более полезные графики. Посмотрим на них:
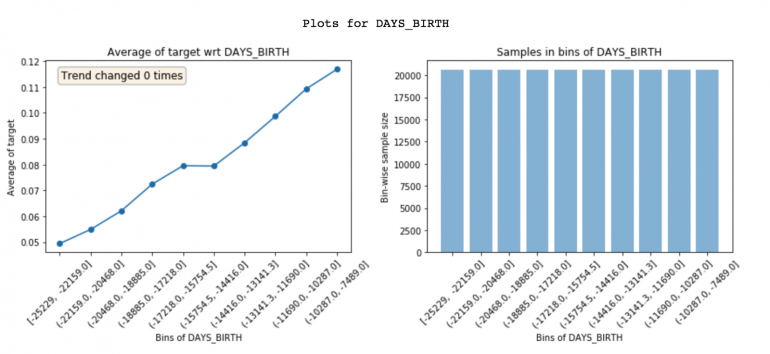
Featexp создает бины (ось X) признака. Затем он вычисляет среднее значение цели в каждом бине и отображает его на рисунке слева. Из графика следует, что у клиентов с высокими отрицательными значениями для DAYS_BIRTH (с большим возрастом) более низкие ставки. Это имеет смысл, поскольку молодые люди обычно чаще просрочивают платежи. Эти графики помогают нам понять, что свойство может сказать о клиентах и как это повлияет на модель. Участок справа показывает количество клиентов в каждом бине.
Поиск признаков с большим шумом
Функции с большим шумом приводят к переобучению, и определить их нелегко. В featexp специальный набор тестов позволяет идентифицировать признаки с большим шумом. Этот набор тестов на самом деле ненастоящий: для него вы заранее знаете цель.
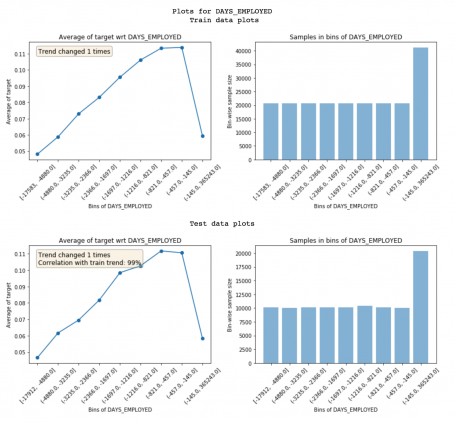
Featexp рассчитывает две метрики для отображения на этих графиках, которые помогают оценить шум:
- Корреляция тренда (показана на графике проверки): если признак ведет себя по-разному при обучении и при проверке, это может приводить к перегрузке модели. Так происходит, потому что модель обучается тому, что не применимо на тестовых данных. Коррекция тренда помогает понять, насколько схоже поведение признака при обучении и при проверке. Признак на графике выше имеет корреляцию 99%. Это не «шумящее» свойство!
- Изменения тренда: внезапные и повторяющиеся изменения тренда могут означать наличие шумов. Но такое изменение тренда может произойти, потому что у данного бина совсем другое количество значений в других признаках и, следовательно, его частота не может сравниваться с другими бинами.
Приведенная ниже функция имеет различный тренд и, следовательно, низкую корреляцию: 85%. Эти две метрики можно использовать для отключения признаков с большими шумами.

Отключение хорошо работает, если есть много связанных друг с другом признаков. Это приводит к меньшей перегрузке, а другие признаки позволяют избежать потери информации. Также важно не отключать слишком много важных признаков, поскольку это может привести к снижению производительности. То, что признак является важным, не значит, что он не может быть «шумным» — и в этом случае его нельзя отключать!
Используйте тестовые данные на другом интервале времени. Тогда вы будете уверены, что тренд не меняется со временем.
Функция get_trend_stats() в featexp возвращает таблицу с корреляцией тренда и изменением каждого признака.
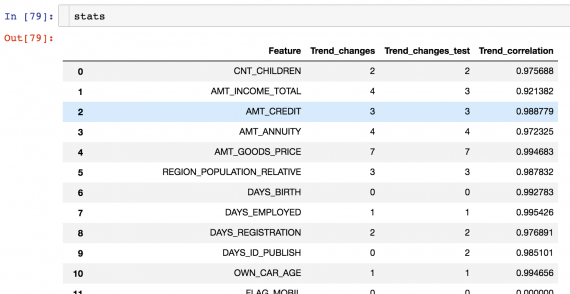
Давайте попробуем отключить признаки с низкой корреляцией тренда в наших данных и посмотреть, как улучшаются результаты.
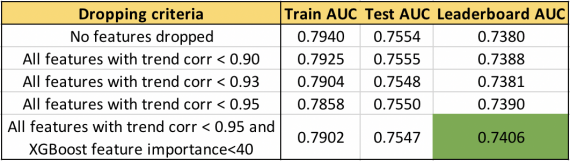
Можно видеть: чем выше порог корреляции тренда, тем выше AUC. Не отключая важные признаки, можно добиться увеличения LB AUC до 0,74. Интересно, что AUC не меняется так сильно, как LB AUC. Важно правильно выбрать стратегию проверки: так, чтобы локальный тест AUC совпадал с LB AUC. Весь код можно найти в featexp_demo.
Разработка признаков
Проанализировав эти графики, вы поймете, как создавать лучшие признаки. Простое понимание данных может привести к разработке лучших признаков. Но в дополнение к этому графики также может помочь вам улучшить существующие признаки. Давайте рассмотрим еще один признак EXT_SOURCE_1:
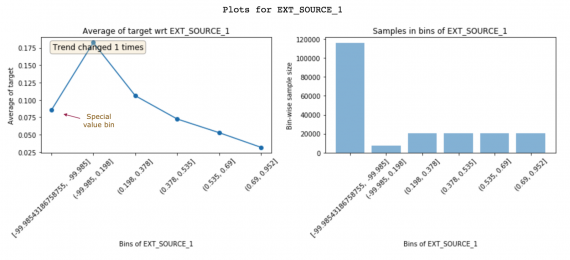
Клиенты с высоким значением EXT_SOURCE_1 имеют низкие ставки. Но первый бин (ставка ~ 8%) не соответствует тренду признака (идет вверх, а затем вниз). Он имеет только отрицательные значения вблизи -99.985 и большое количество единиц в бине. Это, вероятно, подразумевает, что это специальные значения. К счастью, нелинейные модели не будут испытывать проблемы с обучением этим связям. Но для линейных моделей, таких как логистическая регрессия, такие специальные значения и нули (которые будут показаны как отдельный бин) должны быть поданы в значение из бина с аналогичной ставкой вместо простой подачи со средним значением признака.
Важность признаков
Featexp также помогает определить относительную важность того или иного признака. DAYS_BIRTH и EXT_SOURCE_1 имеют хорошую линию тренда. Но большинство единиц EXT_SOURCE_1 сосредоточено в специальном бине значений, что означает, что признак почти одинаков для большинства клиентов и, следовательно, не может хорошо их дифференцировать. Это говорит о том, что признак может быть не так важен, как DAYS_BIRTH. Основываясь на модели важности признаков XGBoost, DAYS_BIRTH на самом деле важнее EXT_SOURCE_1.
Отладка признаков
Глядя на графики Featexp, можно находить ошибки в сложных кодах, делая следующие две вещи:
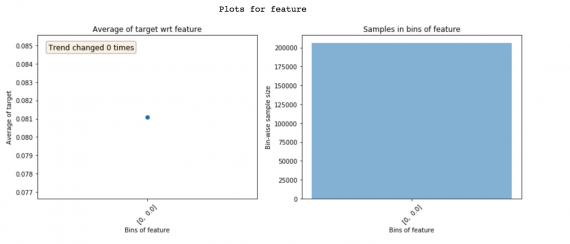
- Проверьте, что распределение клиентов для признака по бинам выглядит нормально. Я лично много раз сталкивался с такими случаями, как выше, из-за незначительных ошибок.
- Всегда выдвигайте гипотезу о том, как будет выглядеть тренд признака, прежде чем смотреть на графики. То, что тренд выглядит не так, как вы ожидали, может означать некоторые проблемы. И, откровенно говоря, этот процесс предсказания трендов делает создание моделей машинного обучения намного более захватывающим!
Обнаружение утечек
Утечка данных от цели к признакам приводит к перегрузке модели. Признаки с утечкой имеют большую важность. Но понять, почему утечка происходит в том или ином признаке, сложно. Глядя на графики featexp, можно разобраться в этом.
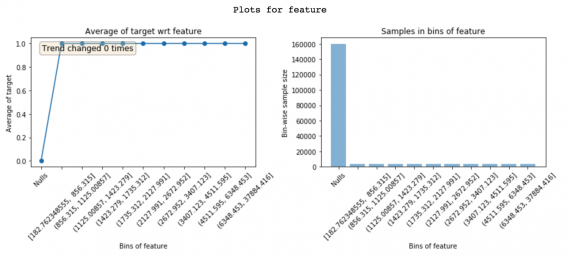
Приведенный выше признак имеет частоту 0% в бине нулей и 100% во всех других бинах. Ясно, что это предельный случай утечки. Этот признак имеет значение только тогда, когда клиент неплатежеспособен. Нужно выяснить, почему так происходит: либо есть ошибка, либо признак действительно реагирует только на неплатежеспособных клиентов (и тогда его нужно отключить). Разобравшись, почему признак приводит к утечке, можно быстрее исправить проблему.
Мониторинг модели
Поскольку featexp вычисляет корреляцию трендов между двумя датасетами, ее можно легко использовать для мониторинга модели. Каждый раз, когда модель переобучается, новые данные для обучения могут быть сравнены с хорошо проверенными данными (обычно это данные, которые использовались при первой сборке модели). Корреляция тренда может помочь вам отследить, изменилась ли как-то зависимость признака от цели.
Эти простые проверки часто помогали мне в создании лучших моделей в реальных задачах и в Kaggle. С featexp требуется 15 минут, чтобы посмотреть на графики, и это определенно стоит того.