Что же такое определение позы (pose estimation)? Определение позы — это метод компьютерного зрения, который оценивает фигуры людей на изображениях и видео и определяет, где находятся основные суставы. Технология не распознает, кто конкретно представлен на изображении — нет идентифицирующей личность информации.
У pose estimation много областей применения, например, дополненная реальность, дорисованная анимация, фитнес-приложения. Создатели TensorFlow надеются, что доступность этой модели вдохновит разработчиков экспериментировать и применять оценку позы в собственных проектах. Альтернативные системы детекции позы требуют специализированного оборудования или камер, а также сложной настройки. С PoseNet, работающим на TensorFlow.js, разработчику будет достаточно настольного компьютера или телефона с веб-камерой, чтобы испытать эту технологию непосредственно в веб-браузере. Исходная модель лежит в открытом доступе, поэтому разработчики Javascript получают доступ к этой технологии посредством нескольких строк кода. Ко всему прочему, технология помогает сохранить конфиденциальность пользователей: поскольку TensorFlow.js работает в браузере, информация о позе не покидают компьютер пользователя.
Начало работы с PoseNet
PoseNet может использоваться для оценки поз одного или нескольких человек. Это означает, что есть версия алгоритма для обнаружения только одного человека на изображении/видео и еще одна версия, которая выделяет нескольких людей на изображении/видео. Зачем нужно две версии? Модель для определения одной позы работает быстрее и проще, но требуется присутствие только одного субъекта на изображении (подробнее об этом позже). Сначала рассмотрим алгоритм для определения одной позы, так как он более понятен.
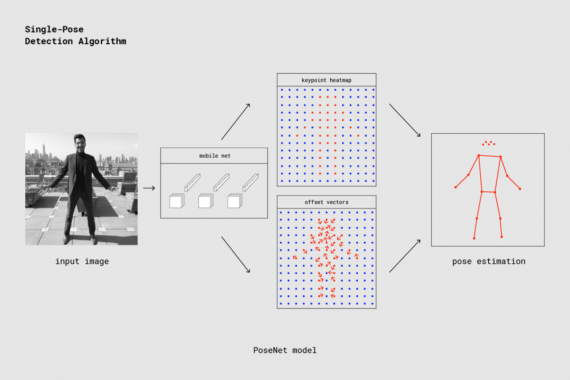
На высоком уровне определение позы происходит в два этапа:
- Входное RGB изображение подается через сверточную нейронную сеть;
- Применяется алгоритм декодирования. Происходит оценка поз и уверенности в позах, оценивается положение и уверенность в ключевых точках из выходных данных модели.
Но что означают все эти определения? Рассмотрим наиболее важные из них:
- Поза — на самом верхнем уровне PoseNet возвращает объект позы, который содержит список ключевых точек и уровень доверия для каждого обнаруженного человека.

- Оценка уверенности в позе определяет общую уверенность в правильном распознавании позы. Она находится в диапазоне от 0 до 1. Может быть использована, чтобы скрыть позы, которые не считаются достаточно надежными.
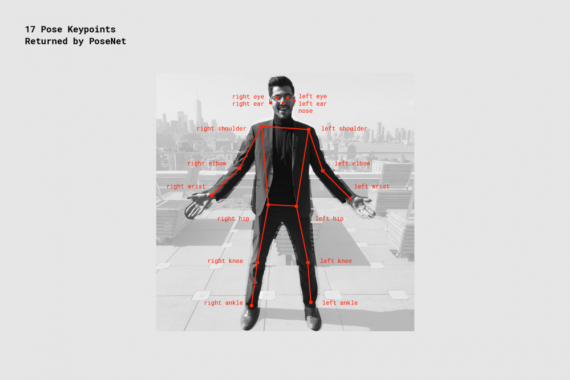
- Ключевая точка — часть позы человека, например, нос, правое ухо, левое колено, правая нога и т. д. Она содержит как саму позицию, так и оценку уверенности. На текущий момент PoseNet распознает 17 ключевых точек, показанных на картинке:
- Оценка уверенности для ключевой точки отражает точность распознанной позиции ключевой точки. Она находится в диапазоне от 0 до 1. Может использоваться для скрытия недостаточно точно определенных ключевых точек.
- Позиция ключевой точки — двумерные координаты x и y в исходном входном изображении, где была обнаружена ключевая точка.
Часть 1: импорт библиотек TensorFlow.js и PoseNet
Большая часть работа заключалась в том, чтобы абстрагироваться от сложности модели и реализовать функциональность в простых в использовании методах. Давайте рассмотрим основы создания PoseNet проекта.
Библиотека может быть установлена с npm:
npm install @tensorflow-models/posenet
и импортируется с использованием модулей es6:
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
или через связку на странице:
<html>
<body>
<!-- Load TensorFlow.js -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<!-- Load Posenet -->
<script src="https://unpkg.com/@tensorflow-models/posenet">
</script>
<script type="text/javascript">
posenet.load().then(function(net) {
// posenet model loaded
});
</script>
</body>
</html>
Часть 2a: оценка позы для одного человека

Алгоритм оценки одной позы используют, когда на входном изображении или видео есть только один человек, желательно находящийся в центре. Если на изображении представлено несколько людей, ключевые точки от обоих, скорее всего, будут оцениваться как часть одной и той же одной позы. Это означает, например, что левое плечо одного человека и правое колено другого человека могут быть объединены алгоритмом, как принадлежащие одной позе. Если есть хоть какая-то вероятность того, что на входных изображениях будет несколько людей, лучше использовать алгоритм для определения нескольких поз.
Рассмотрим входные данные для алгоритма оценки одной позы:
- Элемент входного изображения — html объект, содержащий изображение для предсказания позы, например, видео или тег изображения. Важно отметить, что элемент изображения или видео должен быть квадратным;
- Отразить по горизонтали. По умолчанию используется значение false. Необходим, если позы должны быть перевернуты/зеркально отображены по горизонтали. Установите значение true для видеороликов, где видео по умолчанию переворачивается горизонтально (например, веб-камера), если вы хотите, чтобы позы возвращались в правильной ориентации;
- Шаг выхода– должен быть 32, 16 или 8. Значение по умолчанию 16. Во внутреннем представлении этот параметр влияет на высоту и ширину слоев в нейронной сети. На высоком уровне он влияет на точность и скорость pose estimation. Чем ниже значение выходного шага, тем выше точность и тем меньше скорость, чем выше значение, тем быстрее скорость, но и снижается точность. Лучший способ узнать влияние выходного шага на качество вывода — поиграть с демо версией алгоритма оценки одной позой.
На выходе алгоритма получаем:
- Позу, содержащую оценку уверенности и массив из 17 ключевых точек;
- Позицию и оценку уверенности для каждой ключевой точки. Опять же, все позиции ключевых точек имеют координаты x и y во входном пространстве и могут отображаться прямо на изображении.
Короткий блок кода показывает, как использовать алгоритм определения одной позы
const imageScaleFactor = 0.50; const flipHorizontal = false; const outputStride = 16;
const imageElement = document.getElementById('cat');
// load the posenet model const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
Пример вывода массива поз
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
Часть 2b: Оценка поз для нескольких людей

Алгоритм определения нескольких поз способен выделить более одной позы на изображении. Он немного медленнее и сложнее, чем алгоритм определения одной позы, но имеет преимущество: если на изображении несколько людей, обнаруженные для них ключевые точки с меньшей вероятностью связаны с неправильной позой. По этой причине, даже если необходимо обнаружить позу только одного человека, этот алгоритм может быть более подходящим.
Более того, привлекательным свойством алгоритма является то, что количество людей на входном изображении не влияет не производительность. Время вычисления будет одинаковым независимо от того, будет ли обнаружено 15 человек или 5.
Рассмотрим входные данные:
- Элемент входного изображения — как и в алгоритме определения одной позы.
- Коэффициент масштабирования изображения — как и в алгоритме определения одной позы.
- Отразить по горизонтали. Как и в алгоритме определения одной позы.
- Шаг выхода — как и в алгоритме определения одной позы.
- Максимальное число поз для обнаружения — целое число. По умолчанию равно 5. Максимальное количество поз, которые нужно определить.
- Порог для оценки уверенности в позе — от 0 до 1. По умолчанию 0.5. На верхнем уровне параметр контролирует минимальный показатель уверенности в возвращаемых позах.
- Радиус подавления не-максимумов (NMS) — число в пикселях. На верхнем уровне он контролирует минимальное расстояние между возвращаемыми позами. По умолчанию это значение равно 20. Его следует увеличивать/уменьшать, для того чтобы отфильтровывать менее точные позы, но только если настройка уверенности в оценки позе недостаточно хорошая.
Лучший способ узнать, какой эффект имеют эти параметры, — поиграть с демо-версией алгоритма определения нескольких поз.
На выходе алгоритм выдает массив поз, каждая из которых содержит ту же информацию, что и в случае алгоритма для определения одной позы.
Этот короткий блок кода демонстрирует, как использовать алгоритм определения нескольких поз:
const imageScaleFactor = 0.50; const flipHorizontal = false; const outputStride = 16; // get up to 5 poses const maxPoseDetections = 5; // minimum confidence of the root part of a pose const scoreThreshold = 0.5; // minimum distance in pixels between the root parts of poses const nmsRadius = 20;
const imageElement = document.getElementById('cat');
// load posenet const net = await posenet.load();
const poses = await net.estimateMultiplePoses( imageElement, imageScaleFactor, flipHorizontal, outputStride, maxPoseDetections, scoreThreshold, nmsRadius);
Пример результирующего массива поз выглядит следующим образом:
// array of poses/persons
[
{ // pose #1
"score": 0.42985695206067,
"keypoints": [
{ // nose
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"score": 0.99710708856583
},
...
]
},
{ // pose #2
"score": 0.13461434583673,
"keypositions": [
{ // nose
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"score": 0.9978438615799
},
...
]
},
...
]
Если вы дочитали до этого места, вы уже знаете достаточно, чтобы начать работу с демо-версиями PoseNet.
Для самых любопытных — погружение в технические детали
На верхнем уровне процесс выглядит следующим образом:
Важно отметить, что исследователи подготовили как ResNet, так и модель для мобильных приложений MobileNet. Хотя модель ResNet имеет более высокую точность, ее большой размер и множество слоев делают время загрузки страницы и время вывода отнюдь не идеальными для любых приложений реального времени. Мы разработали модель MobileNet для реализации на мобильных устройствах.
Обработка результатов модели: пояснение выходных шагов
Для начала разберем, как получить результаты модели PoseNet (в основном, тепловые карты и векторы смещения), уделяя при этом внимание параметру шаг выхода.
Удобно, что модель PoseNet инвариантна относительно размера изображения, это означает, что она может прогнозировать позы в масштабе исходного изображения, независимо от того, уменьшалось ли изображение. Таким образом, PoseNet можно настроить на более высокую точность за счет производительности, установив шаг выхода во время выполнения, о чем уже упоминалось выше.
Шаг выхода определяет, насколько на сколько нужно уменьшить результат относительно размера входного изображения. Он влияет на размер слоев и выходных данных модели. Чем выше шаг выходы, тем меньше разрешение слоев в сети и выходных данных, и соответственно ниже их точность. В этой реализации выходной шаг может иметь значения 8, 16 или 32. Другими словами, с шагом выхода равным 32 результат будет получен быстрее всего, но с наименьшей точностью, а маг 8 приведет к максимальной точности, но и к самой низкой производительности. Рекомендуется начинать с 16.
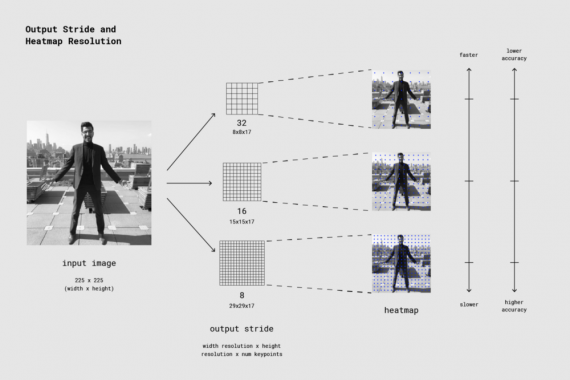
Под капотом, когда шаг выхода установлен на 8 или 16, количество шагов ввода в слоях уменьшается для создания большего разрешения вывода. Затем используется свертка atrous, позволяющая фильтрам свертки в последующих слоях иметь более широкое поле (эта свертка не применяется при шаге выхода 32). В то время как Tensorflow поддерживал свертку atrous, в TensorFlow.js ее нет, поэтому мы добавили PR, чтобы использовать ее.
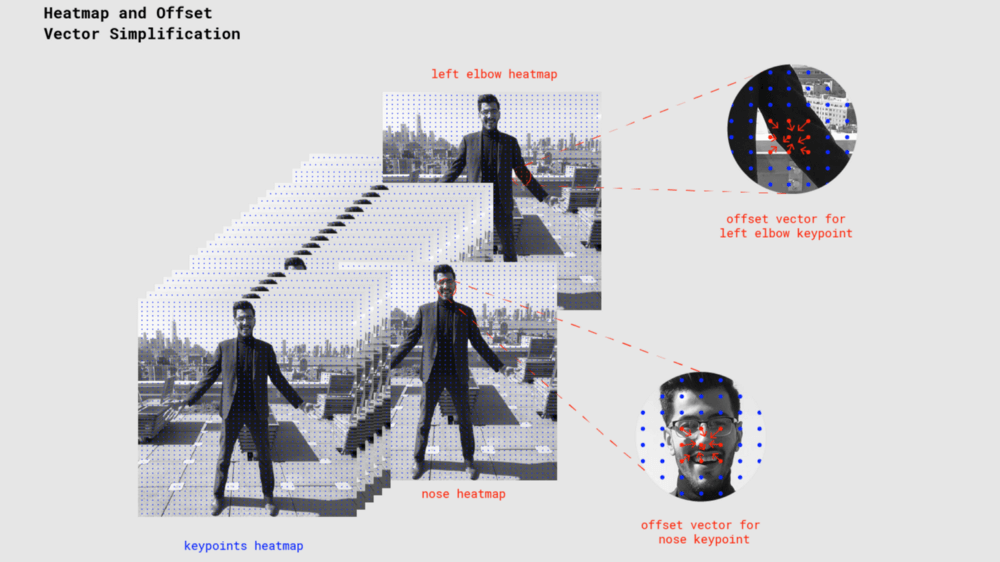
Тепловые карты и векторы смещения
Когда PoseNet обрабатывает изображение, возвращается тепловая карта вместе с векторами смещения, которые можно декодировать так, чтобы находить в изображении области с высоким показателем уверенности для ключевых точек позы. Скоро станет понятно, что все это означает, но пока приведенная ниже иллюстрация демонстрирует на высоком уровне, как каждая ключевая точка позы связана с одним тензором тепловой карты и тензором вектора смещения:
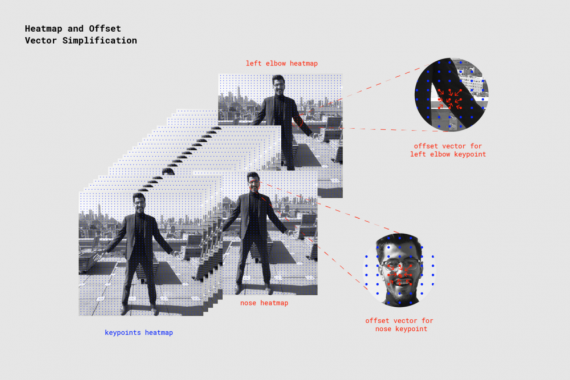
Оба результата представляют собой трехмерные тензоры с высотой и шириной, которые будем называть разрешением. Разрешение определяется размером входного изображения и шагом выхода в соответствии с формулой:
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output // stride of 16 results in an output resolution of 15 // 15 = ((225 - 1) / 16) + 1
Тепловые карты
Каждая тепловая карта представляет собой трехмерный тензор размера Resolution x Resolution x 17, где Resolution — разрешение, 17 — это число определяемых PoseNet ключевых точек. Например, с размером изображения 225 и шагом выхода 16, тепловая карта будет размера 15x15x17. Каждая компонента в третьем измерении (из 17) соответствует тепловой карте для конкретной ключевой точки. Каждая позиция в этой тепловой карте имеет оценку уверенности, которая является вероятностью того, что часть этой ключевой точки присутствует в позе. Можно представлять это так: исходное изображение разбивается на сетку 15×15, где оценки тепловой карты классифицируют, насколько вероятна каждая ключевая точка в каждом квадрате сетки.
Векторы смещения
Каждый вектор смещения — это трехмерный тензор размера Resolution x Resolution x 34, где 34 — количество ключевых точек * 2. При размере изображения 225 и шаге выхода 16 они будут иметь размер 15x15x34. В то время как тепловые карты приблизительно определяют, где находятся ключевые точки, векторы смещения соответствуют точкам тепловой карты и используются для прогнозирования точного расположения ключевых точек путем перемещения вдоль вектора из соответствующей точки тепловой карты. Первые 17 компонент вектора смещения содержат координату x вектора, а последние 17 — координату y. Размеры вектора смещения представлены в том же масштабе, что и исходное изображение.
Оценка поз из результатов модели
После того как изображение подается модели, выполняются расчеты для оценки определенных поз из выходных данных. Алгоритм определения одной позы, например, возвращает оценку уверенности в позе, которая содержит массив ключевых точек (индексированных part ID), каждый из которых имеет свою оценку уверенности и координаты x, y.
Для получения ключевых точек позы:
- Примените сигмоид к тепловой карте, чтобы получить оценки.
scores = heatmap.sigmoid()
2. Примените argmax2d к оценкам уверенности в ключевых точках, чтобы получить координаты x и y в тепловой карте с наивысшим показателем для каждой части. По существу, это то место, где данная часть будет присутствовать с наибольшей вероятностью. Создается тензор размера 17×2, каждая строка которого является координатами y и x в тепловой карте с наилучшей метрикой для каждой части.
heatmapPositions = scores.argmax(y, x)
3. Вектор смещения для каждой части извлекается путем получения координат x и y из смещений, соответствующих координатам x и y в тепловой карте для этой части. Получается тензор размера 17×2, причем каждая строка является вектором смещения для соответствующей ключевой точки. Например, для части с индексом k, и позиции тепловой карты с координатами y и x, вектор смещения считается:
offsetVector = [offsets.get(y, x, k), offsets.get(y, x, 17 + k)]
4. Чтобы получить ключевую точку, координаты x и y каждой части тепловой карты умножаются на шаг выхода, а затем полученное число добавляется к соответствующему вектору смещения, который рассчитан в том же масштабе, что и исходное изображение.
keypointPositions = heatmapPositions * outputStride + offsetVectors
5. Наконец, оценка уверенности для каждой ключевой точки — это оценка уверенности ее позиции на тепловой карте. Оценка уверенности в позе — это среднее значение метрик для ключевых точек.
Определение нескольких поз
Подробности алгоритма определения нескольких поз выходят за рамки данного поста. Главным образом, этот алгоритм отличается тем, что он использует метод для группировки ключевых точек в позы посредством перемещения векторов вдоль графа. В частности, он использует алгоритм fast greedy decoding из статьи PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. Для получения дополнительной информации об алгоритме определения нескольких поз почитайте эту публикацию или взгляните на код.
Перевод — Кристина Беликова, оригинал — официальный блог Tensorflow









