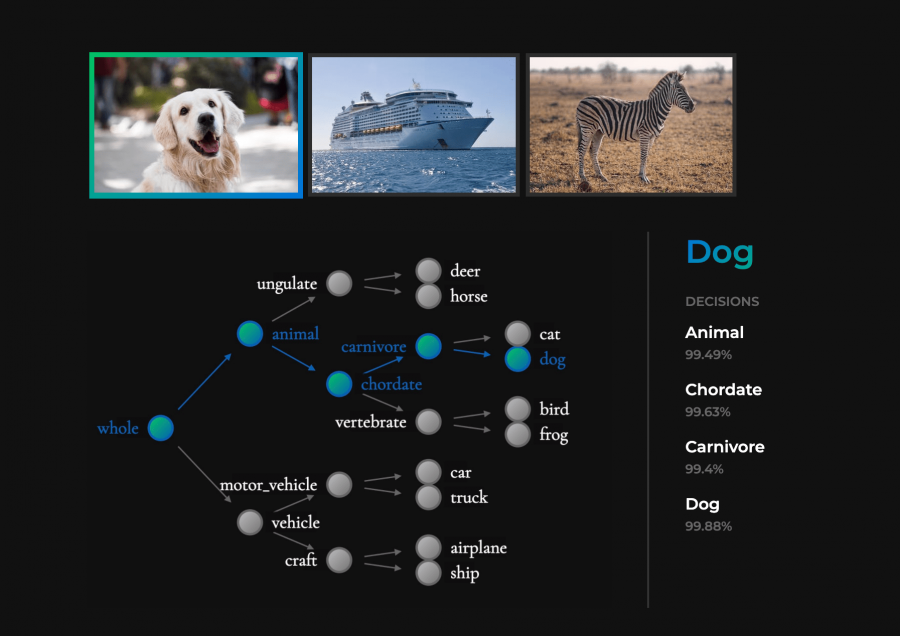
Исследователи из UC Berkley предлагают интерпретируемую нейросеть, которая основана на архитектуре решающих деревьев и выдает сравнимые с state-of-the-art предсказания. Код проекта и предобученные модели доступны в открытом репозитории на GitHub.
Глубокое обучение применяется в сферах, которые требуют обоснованности предсказаний. Такими сферами являются финансовое моделирование или диагностирование болезней. Существующие исследования фокусируются на интерпретируемости обученных state-of-the-art нейросетей постфактум. До популяризации нейросетей решающие деревья являлись золотым стандартом как баланс между интерпретируемостью и точностью модели.
Предыдущие попытки скомбинировать решающие деревья и нейросети результировали в модели, которые:
- Менее точны, чем современные нейросети, даже на сравнительно маленьких датасетах (MNIST);
- Требует значительных изменений в архитектурах
Neural-Backed Decision Trees (NBDTs) выдают state-of-the-art результаты. При этом они не требуют изменений в архитектуре нейросети. NBDTs по точности отличаются от базовой нейросети не более чем на 1% на дататасетах CIFAR10, CIFAR100 и TinyImageNet. На ImageNet предложенная архитектура по точности отстает от EfficientNet на 2%.
Как это работает
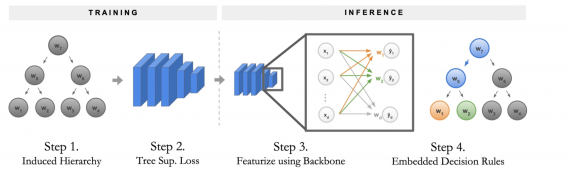
Процесс обучения и инференса Neural-Backed Decision Tree состоит из четырех этапов:
- Сначала выстраивается иерархия для решающего дерева, которую называют Induced Hierarchy;
- Эта иерархия использует специальную функцию потерь Tree Supervision Loss;
- На инференсе данные сначала проходят через базовый блок нейросети (backbone), который идет до финального полносвязного слоя;
- Финальный полносвязный слой прогоняется как последовательность решающих правил, которые называют Embedded Decision Rules