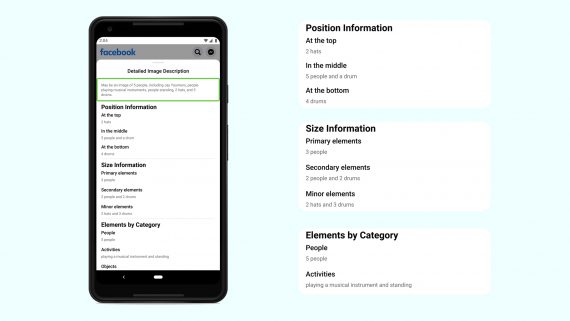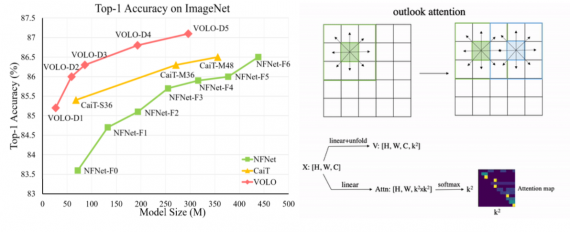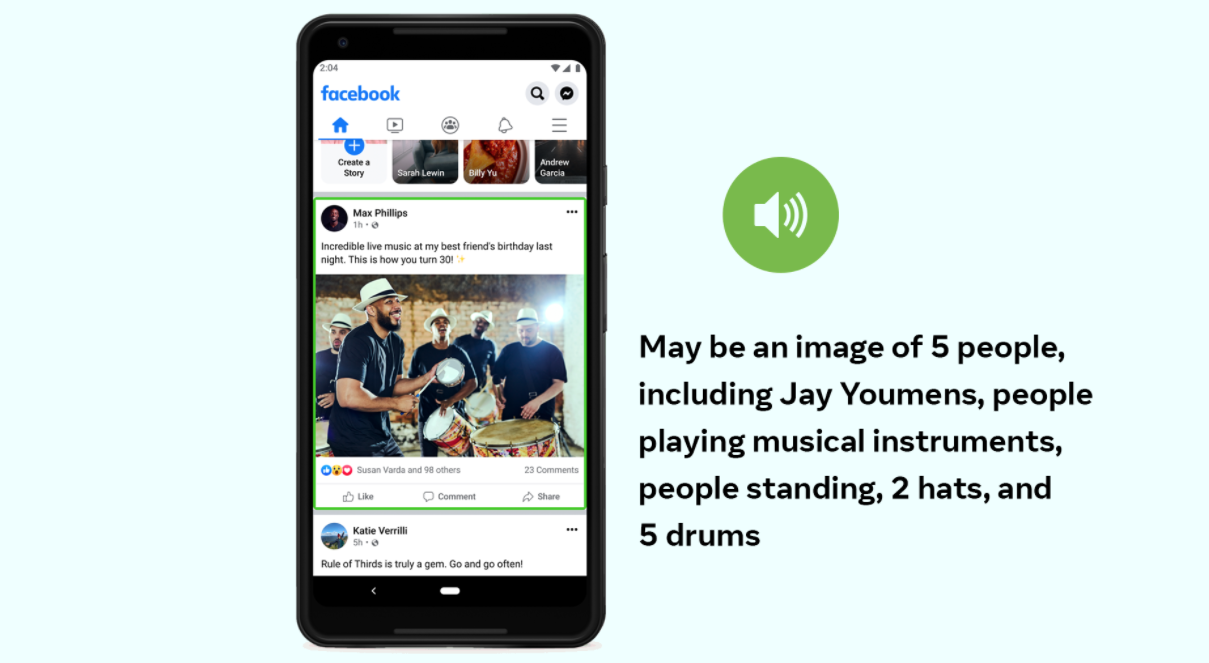
A neural network from Facebook AI generates descriptions for photos for users with vision problems. The app uses object recognition to generate textual descriptions of the image. It makes the Facebook app easier to use for visually impaired users. The Faster R-CNN from Detectron is used as the architecture of the model. The resulting neural network recognizes 1200 classes of objects.
When users scroll through the news feed, they come across photos. Some users cannot immediately recognize the content of the image. Visually impaired users can perceive the content of an image using textual descriptions of the scene (alternative text). However, most of the images do not have a textual description. For such cases, FAIR has developed an Automatic Alternative Text (AAT) system.
Updates in the AAT
In the updated version, the AAT system recognizes 10 times more object classes. Besides, the descriptions themselves are more detailed and include actions, signs, animal species, and more. Example description: “Selfie of two people on the street opposite the Leaning Tower of Pisa”.
Developers have moved away from supervised learning to increase the number of object classes the model can recognize and reduce markup costs. Initially, the AAT model recognized only 100 objects. The updated model was trained on billions of open Instagram images and their hashtags. Then the model was re-trained on data collected from different countries with the translation of hashtags into different languages. Also, the neural network was tested for hidden biases in relation to gender, complexion, and age.