In a joint project, researchers from several universities in China and UK have proposed a new powerful neural network which has a VGG-like plain and simple architecture using only a stack of convolutions.
Over the course of past decade, deep neural networks have evolved a lot and current state-of-the-art architectures have rather complex architecture that involves multiple branches for subtasks, and very heavy design. On the contrary, the networks that were initially successful such as VGG, were far more simple than the current models and they mostly consisted of few building blocks (convolutional layers, activation layers etc.). The specific VGG model had actually even simpler architecture having only one layer stack that contains 3×3 convolutions followed by ReLU non-linearities and nothing else.
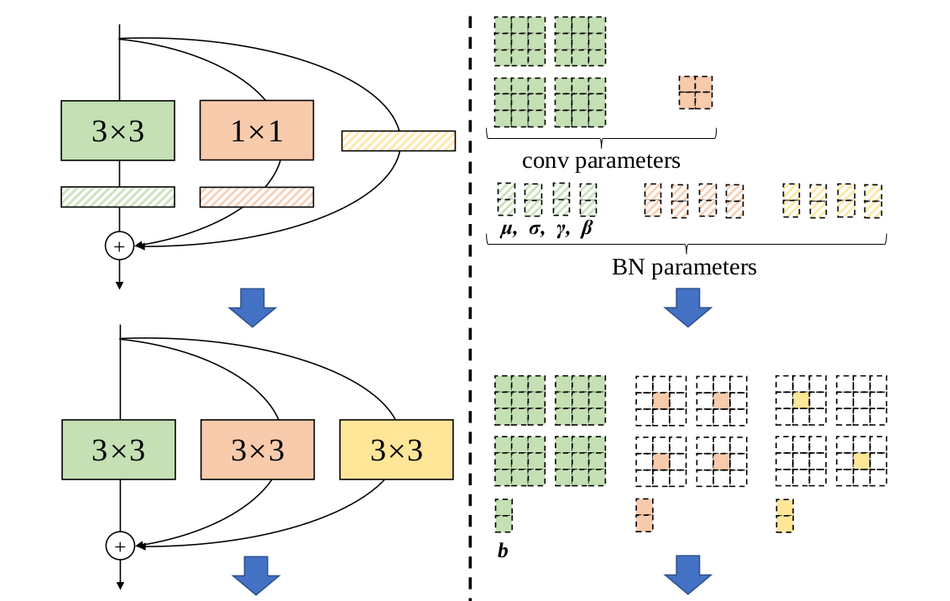
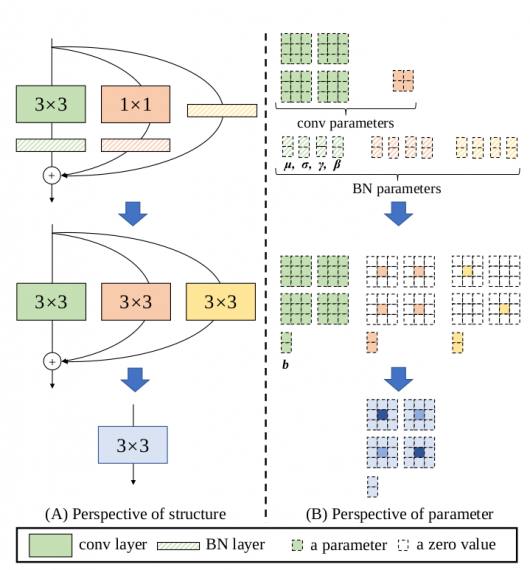
In recent paper, researchers proposed a way to decouple training and inference, such that a simple plain model (like the above-mentioned VGG) achieves great performance. They observed that a trained block can be converted to 3×3 convolutional layer for inference. Researchers call that a structural re-parametrization technique and consequently the proposed model was named RepVGG. In more detail, the idea is that every batch normalization layer and its preceding conv layer can be converted easily to a 3×3 conv layer with a bias vector. The re-parametrization technique is shown in the image below.
To evaluate the performance of the newly proposed model, researchers conducted several experiments and did several ablation studies to justify the significance of this technique. They compared the RepVGG model to existing baselines on ImageNet. Results showed that the model achieves over 80% accuracy after 200 epochs. According to researchers it is the first plain model to achieve this high accuracy on ImageNet. They also mention that RepVGG runs 80-100% faster than ResNet-50 and ResNet101 architectures while maintaining higher accuracy.
The implementation of the model was open-sourced and it is available on Github. The paper was published on arxiv.


