Microsoft has released the DragNUWA weights – a cross-domain video generation model that offers more precise control over the resulting output compared to similar models. Control is achieved by simultaneously using text queries, images, and object trajectories as input data.
In previous video generation models, only a text query served as input data, and in some cases, an image that needed to be animated was also included. This approach fails to fully achieve desired results due to the challenges of describing camera movements and object trajectories in text.
To address this issue, Microsoft developed DragNUWA, a diffusion model that combines three domains – images, text, and trajectories – to provide complete control over the semantics, scene, and dynamics of the video. The key advantage of the model lies in its ability to flexibly define the viewing angle of the scene, camera movement, and trajectories of moving objects.
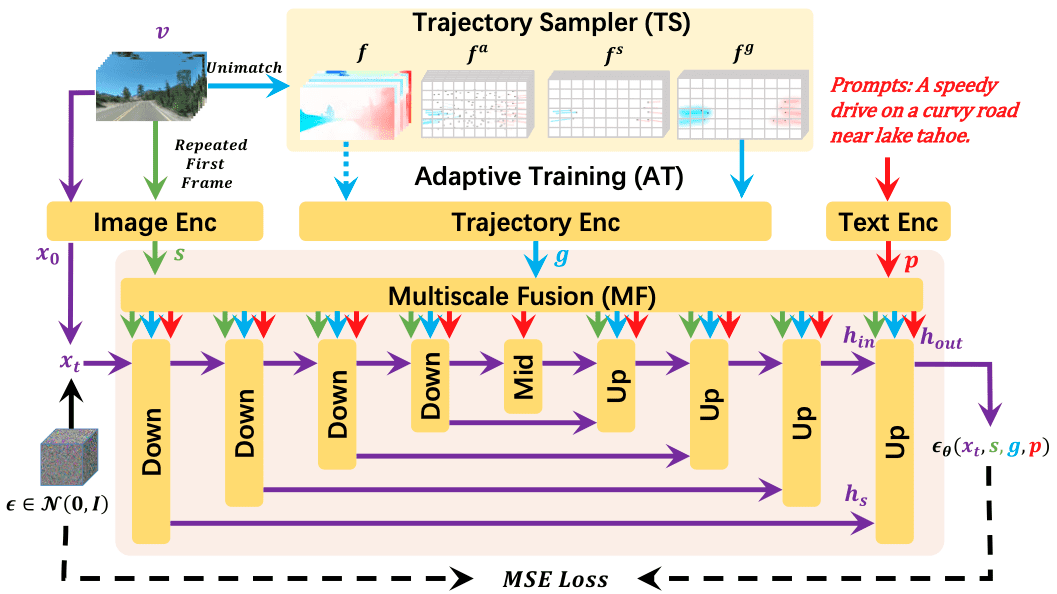
For example, you can upload an image of a boat in a body of water and add a textual cue “the boat is sailing on the lake,” along with indications marking the boat’s trajectory and the flow of water. The trajectory provides detailed movement, the text describes the details of future objects, and the images help the model understand how objects should be depicted. The model enables the implementation of complex trajectories, such as a player’s movement in soccer.
Microsoft has made the model weights and demo version of the project publicly available.