
Оценка позы в 3D — фундаментальная задача компьютерного зрения. Способность компьютера распознавать людей на изображениях и видео применяется в беспилотном вождении, распознавании действий, взаимодействии человека с компьютером, дополненной реальности и робототехнике.
В последние годы ученые добились прогресса в оценке позы в 2D. Важный фактор успеха — наличие больших размеченных датасетов поз человека, которые позволяют обучать сети распознавать позы в 2D. В то же время, успехи в оценке позы в 3D остаются ограниченными, поскольку сложно получить точную информацию о глубине, движении, сегментации частей тела и окклюзии.
В этой статье мы представляем три недавно созданных датасета, которые пытаются решить проблему нехватки аннотированных наборов данных для оценки позы в 3D.
DensePose
Количество изображений: 50 000
Количество меток: 5 000 000
Год выпуска: 2018
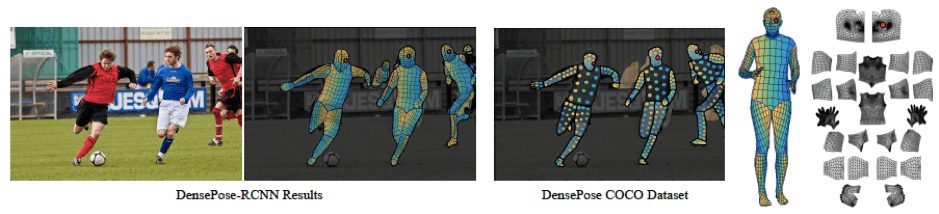
DensePose — это крупный датасет с метками соответствия изображение-поверхность, вручную помеченный на 50000 изображениях COCO. Датасет создан FAIR. Команда привлекла сотрудников, которые вручную задавали соответствие глубины на 2D изображениях и поверхностей, отвечающих телам людей, с помощью специально разработанного ПО для аннотирования.
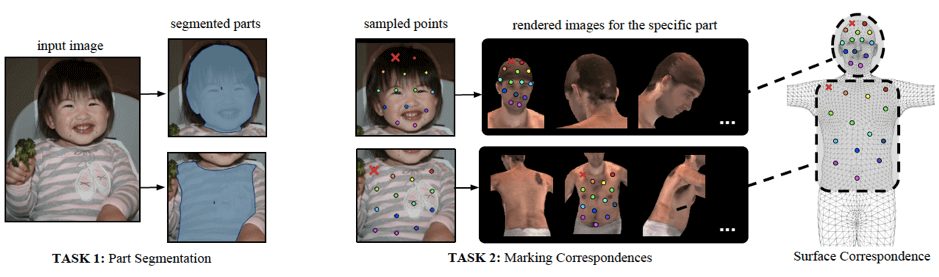
Как показано ниже, на первом этапе сотрудники определяют области, соответствующие видимым, семантически определенным частям тела. На втором этапе каждая часть области разбивается на подобласти с помощью набора точек, и аннотаторы приводят эти точки в соответствие с поверхностью. Исследователи хотели избежать вращения поверхности вручную для этой цели и предоставили сотрудникам 6 изображений с разных точек зрения, чтобы позволить им ставить метки с любого ракурса.
Ниже представлены визуализации аннотаций на изображениях из набора для проверки: изображения (слева), U (посередине) и V (справа) для собранных точек.

DensePose — это первый собранный вручную истинный датасет для оценки позы по глубине.
SURREAL
Количество кадров: 6 500 000
Количество объектов: 145
Год выпуска: 2017
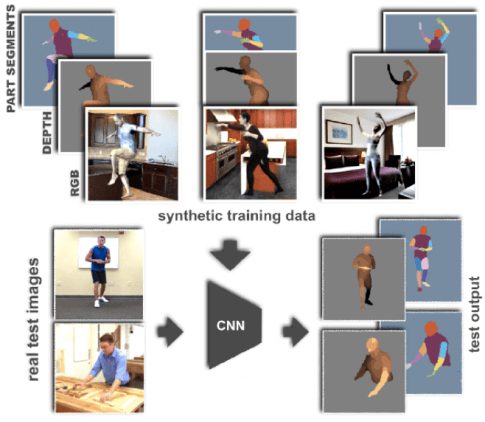
SURREAL (Synthetic hUmans foR REAL tasks) — это новый большой датасет с искусственными, но реалистичными изображениями людей, получаемыми из трехмерных последовательностей данных захвата человеческого движения. Он включает 6 миллионов кадров с аннотациями, такими как поза, карты глубины и маски сегментации.
Как описано в статье, изображения в SURREAL получаются из трехмерных последовательностей данных MoCap. Степень реалистичности искусственных изображений обычно ограничена. Чтобы обеспечить реалистичность человеческих тел в этом датасете, исследователи решили создать искусственные тела с использованием модели SMPL, параметры которой подбирались с помощью MoSh по необработанному массиву 3D-маркеров MoCap. Более того, авторы датасета SURREAL обеспечили большое разнообразие углов зрения, одежды и освещения.
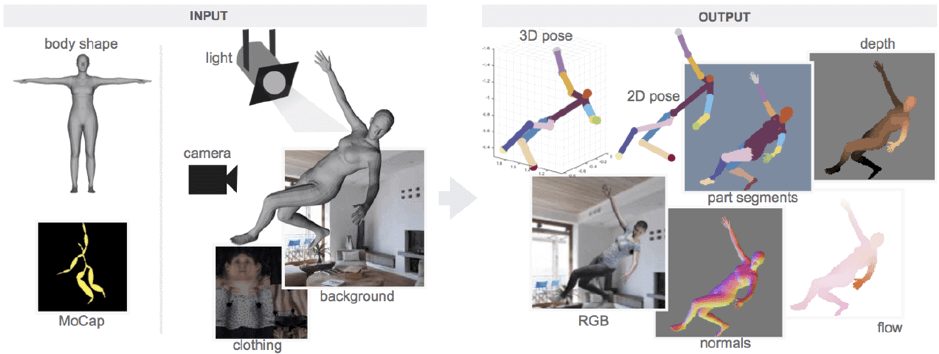
Ниже приведена схема создания искусственной модели человеческого тела:
- человек фотографируется для получения 3D модели тела;
- происходит рендеринг кадра с использованием фонового изображения, карты текстуры тела, освещения и положения камеры;
- все «ингредиенты» генерируются случайным образом для увеличения разнообразия данных;
- сгенерированные RGB изображения сопровождаются 2D/3D позами, нормалями к поверхности, потоком света, картами глубины и картами сегментации частей тела.
Получившийся датасет содержит 145 объектов, >67.5 тыс видео и >6.5 млн кадров:
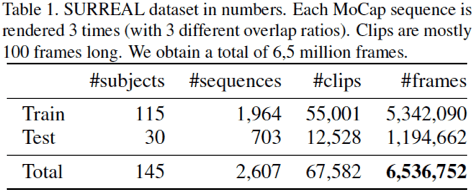
Несмотря на то, что SURREAL содержит искусственные изображения, исследователи, создавшие этот датасет, демонстрируют, что CNN-сети, прошедшие обучение в SURREAL, позволяют получать точную оценку карты глубины и сегментацию частей тела в реальных RGB изображениях. Как следствие, этот датасет предоставляет новые возможности для улучшения методов 3D-оценки позы с использованием большого количества искусственных данных.
UP-3D
Количество объектов: 5 569
Количество изображений: 5 569 изображений для обучения и 1208 тестовых изображений
Год выпуска: 2017

UP-3D — это датасет, который «объединяет людей» из различных датасетов для решения множества задач. В частности, используя недавно введенный метод SMPLify, исследователи получили высококачественную трехмерную модель тела человека. Аннотаторы вручную сортировали модели на хорошие и плохие.
Этот датасет объединяет два датасета LSP (11 000 изображений для обучения и 1000 тестовых изображений) и часть датасета MPII-HumanPose (13 030 изображений для обучения и 2622 тестовых изображения). Хотя можно было использовать метод автоматической сегментации для генерации силуэтов переднего плана, исследователи решили для надежности привлечь сотрудников для аннотирования. Ученые создали интерактивный инструмент аннотации поверх пакета Opensurfaces для работы с Amazon Mechanical Turk (AMT) и использовали интерактивных алгоритм Grabcut для получения изображений границ силуэтов.
Таким образом, задача аннотаторов состояла в том, чтобы определить силуэты на переднем плане и выполнить сегментацию 6 частей тела.
В то время как в среднем задача маркировки переднего плана занимает 108 сек в LSP и 168 сек в MPII, сегментация занимает вдвое больше времени: 236 с.
Аннотаторы сортировали модели на хорошие и плохие. Ниже приведен процент принятых моделей в каждом датасете:

Таким образом, принятые модели сформировали датасет UP-3D с 5569 изображениями для обучения и 1208 тестовыми изображениями. После экспериментов по семантической сегментации частей тела, оценке позы и 3D-подбору улучшенные 3D-модели расширили исходный набор данных.

Датасет устанавливает новую планку уровня детализации — 31 метка для семантической сегментации частей тела с высокой точностью и 91 метка для оценки человеческой позы. Кроме того, обучение с использованием 91 метки улучшает качество оценки трехмерной человеческой позы на двух популярных датасетах HumanEva и Human3.6M.
Заключение
Существуют разные подходы к построению набора данных для оценки трехмерной человеческой позы. Представленные в статье датасеты сосредоточены на различных аспектах распознавания людей на изображениях. Тем не менее, все они могут быть полезны для оценки позы человека в реальных приложениях.
Интересные статьи:
- Новые датасеты для распознавания объектов в 3D
- Новые датасеты для распознавания действий на видео
- Fluid Annotation — инструмент для разметки изображений от Google AI









