На конференции Biodiversity Next Google AI представили окружение для исследователей биоразнообразия. Окружение позволяет использовать стандартизованные данные и внедрять ML алгоритмы в исследования. Разработка велась совместно с Global Biodiversity Information Facility (GBIF), iNaturalist и Visipedia.
ML находит применение в исследованиях биоразнообразия. Такие воркшопы, как FGVC и LifeCLEF, запускают соревнования по разработке алгоритмов классификации видов животных и растений. Результаты этих соревнований спровоцировали разработчиков в Google расширить датасеты по биоразнообразию и базовые модели для этих датасетов.
GBIF отвечает за процесс сбора данных, взаимодействие между исследовательскими командами и стандартизацию цитирования. Вмешательство организации необходимо для верного лицензирования и стандартизации данных.
Окружение состоит из двух компонентов:
- GBIF формирует датасеты, лицензирует их и присваивает DOI;
- Google и Visipedia обучают и публикуют модели с документацией на TensorFlow Hub. Модели могут затем применяться для исследования биоразнообразия
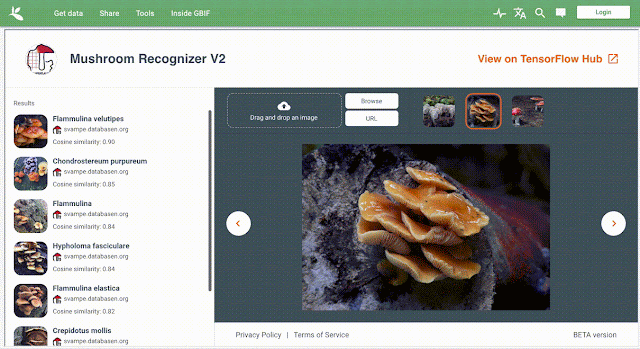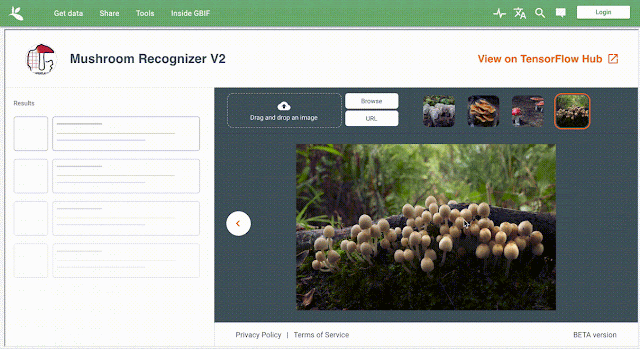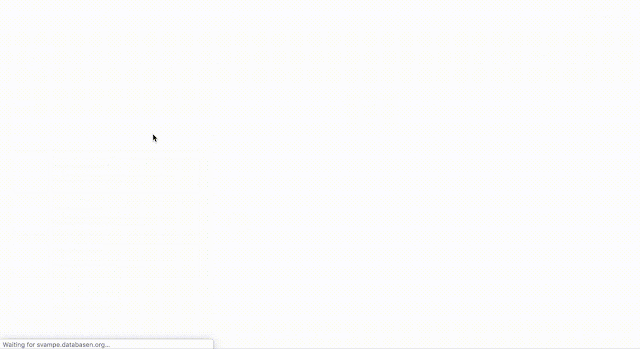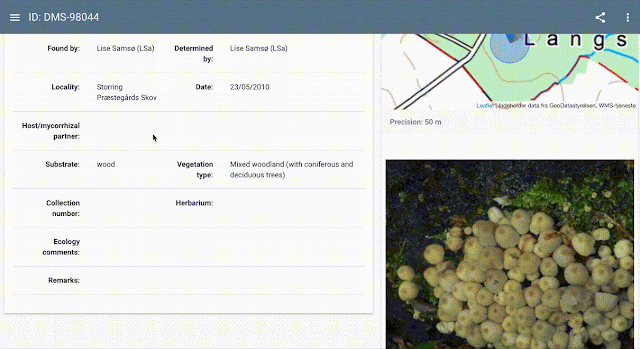
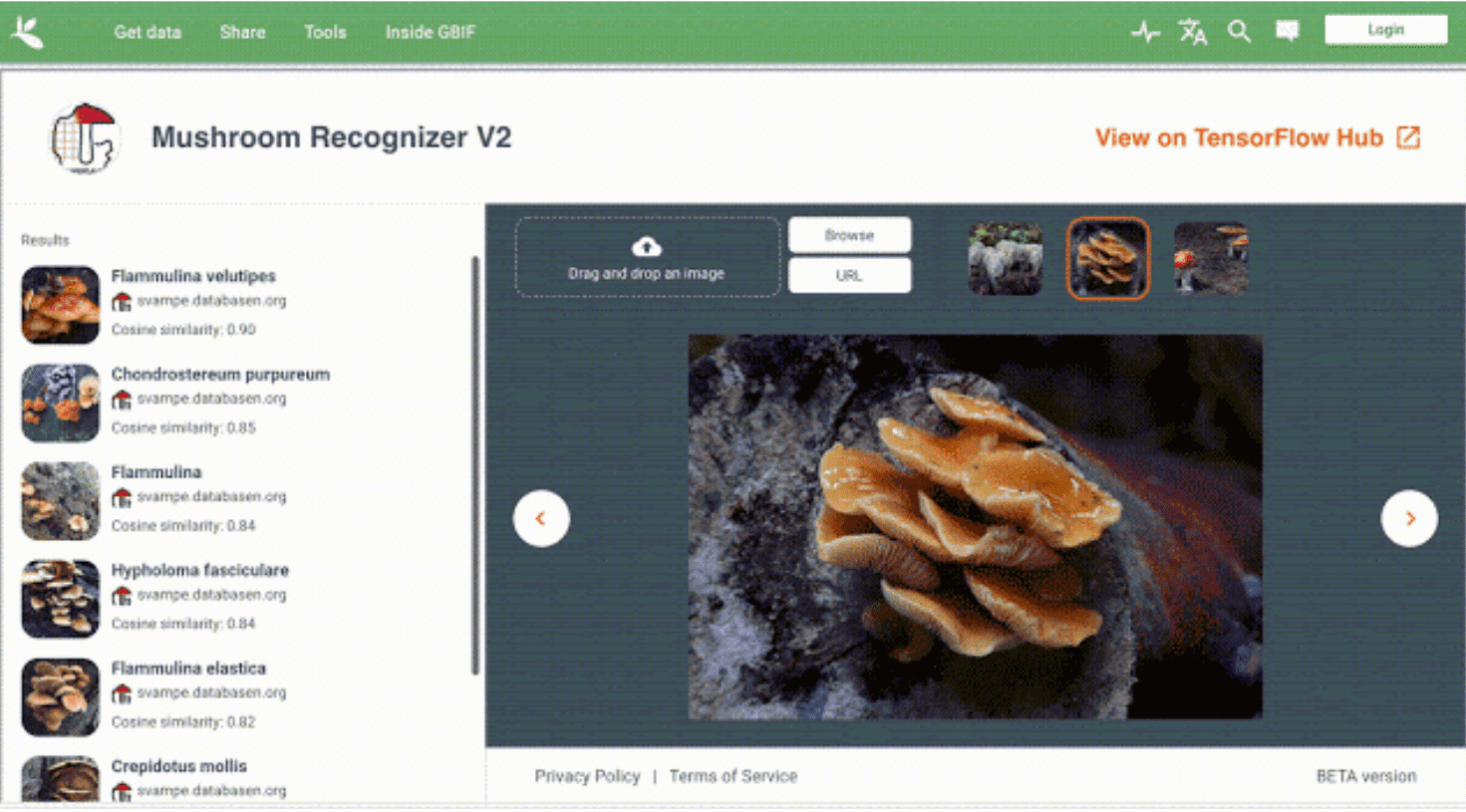
Кейс: распознавание видов грибов по изображению
Иллюстрацией работы окружения является задача классификации изображений грибов. Датасет курируется Danish Mycological Society. Он был отформатирован и опубликован GBIF. Датасет, архитектура модели, которая использовалась для предсказания, и данные по лицензии находятся на TF Hub.