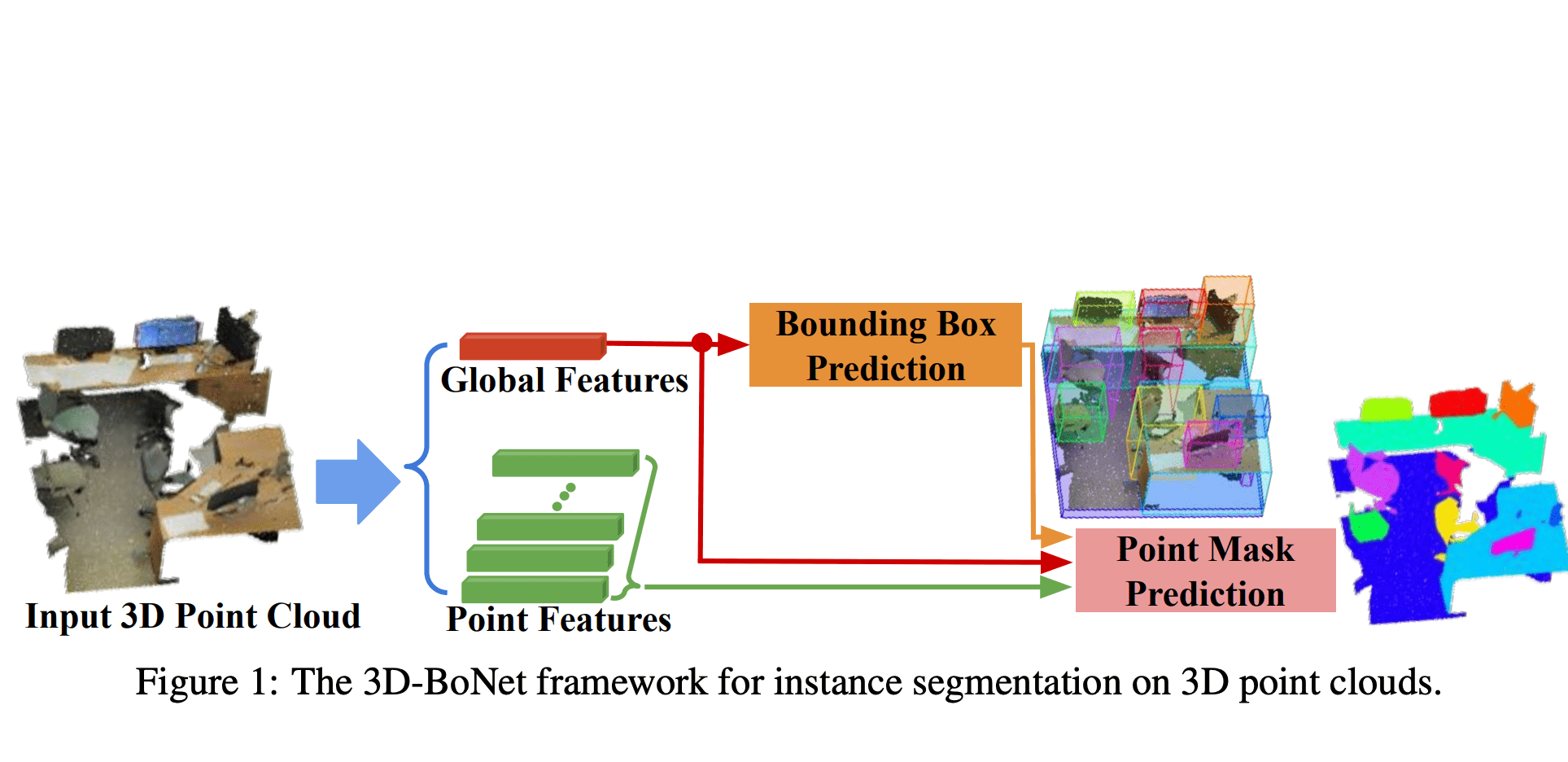
3D-BoNet — это нейросетевая модель, которая распознает объекты на 3D изображениях и решает задачу instance сегментации в 10 раз более вычислительно эффективно по сравнению с существующими подходами.
Под 3D изображением здесь для простоты понимается облако точек, воссоздающее пространство изображения в 3D. Это термин из 3D моделирования. Instance сегментация — это задача распознавания отдельных объектов на изображении.
Что внутри нейросети
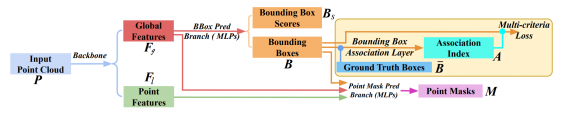
3D-BoNet — это end-to-end нейросеть. Она принимает на вход 3D изображение, а на выходе отдает границы распознанных объектов. Дизайн модели основан на поточечных многослойных перцептронах. Чтобы выучивать локальные и глобальные характеристики объектов, исследователи адаптировали существующую архитектуру PointNet++.
Сначала нейросеть извлекает характеристики для каждой точки входного изображения. Затем модель предсказывает для каждого объекта его грубые границы (bounding box). Другой блок, который отвечает за instance сегментацию, на основании результата прошлого блока предсказывает точные границы объекта.
Оценка работы модели
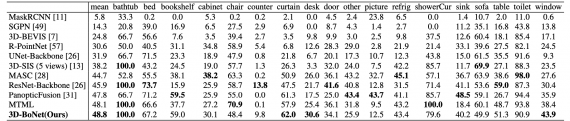
Исследователи провели два эксперимента: на данных ScanNet и S3DIS. Нейросети в обоих случаях решали задачу instance сегментации на 3D изображениях. В качестве метрики для первого эксперимента была Average Precision (AP) в процентах. Во втором эксперименте метрики были Mean Precision и Mean Recall.
Можно видеть, что точность 3D-BoNet сравнима с точностью state-of-the-art подходов.


Детали сравнения времени работы алгоритма с конкурирующими подходами описаны в оригинальной статье в разделе Computation Analysis.
Ограничения модели
Исследователи выделяют три ограничения у 3D-BoNet:
- Вместо не взвешенной комбинации критериев, обучать веса, чтобы адаптировать модель под разные типы входных изображений;
- Обучать семантическую сегментацию вместе с instance сегментацией, а не в отдельных блоках;
- Обучить модель не на разделенных маленьких изображения, а на широкомасштабных







