ACT — это Transformer-модель для задачи end-to-end распознавания объектов на изображении. Она основана на DETR архитектуре, которая требует значительных вычислительных ресурсов для обучения. Результаты DETR по качеству сравнимы с двухступенчатыми архитектурами, как Faster-RCNN. ACT сохраняет качество предсказаний DETR и при этом сокращает количество требуемых ресурсов на обучение и инференс. Исследователи опубликовали код для воспроизведения экспериментов.
Подробнее про подход
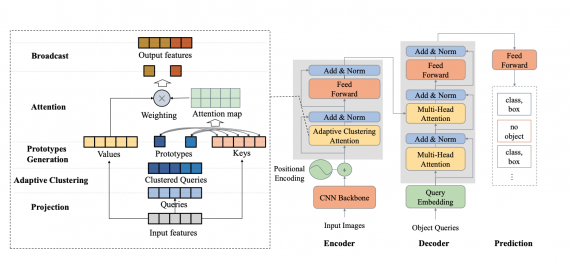
Adaptive Clustering Transformer (ACT) сокращает траты на обработку изображений в высоком разрешении. ACT кластеризует query-признаки адаптивно с помощью метода Locality Sensitive Hashing (LSH) и аппроксимирует взаимодействие query-key с помощью prototype-key взаимодействия. ACT может сократить квадратичную сложность O(N^2) внутри механизма внимания до O(NK), где K — это количество прототипов на каждом слое. ACT может заменить стандартный модуль с механизмом внимания в DETR без потери в качестве предсказаний предобученной DETR модели. Предложенная архитектура достигает баланса между точностью предсказаний и вычислительной затратностью обучения и инференса в FLOPs.