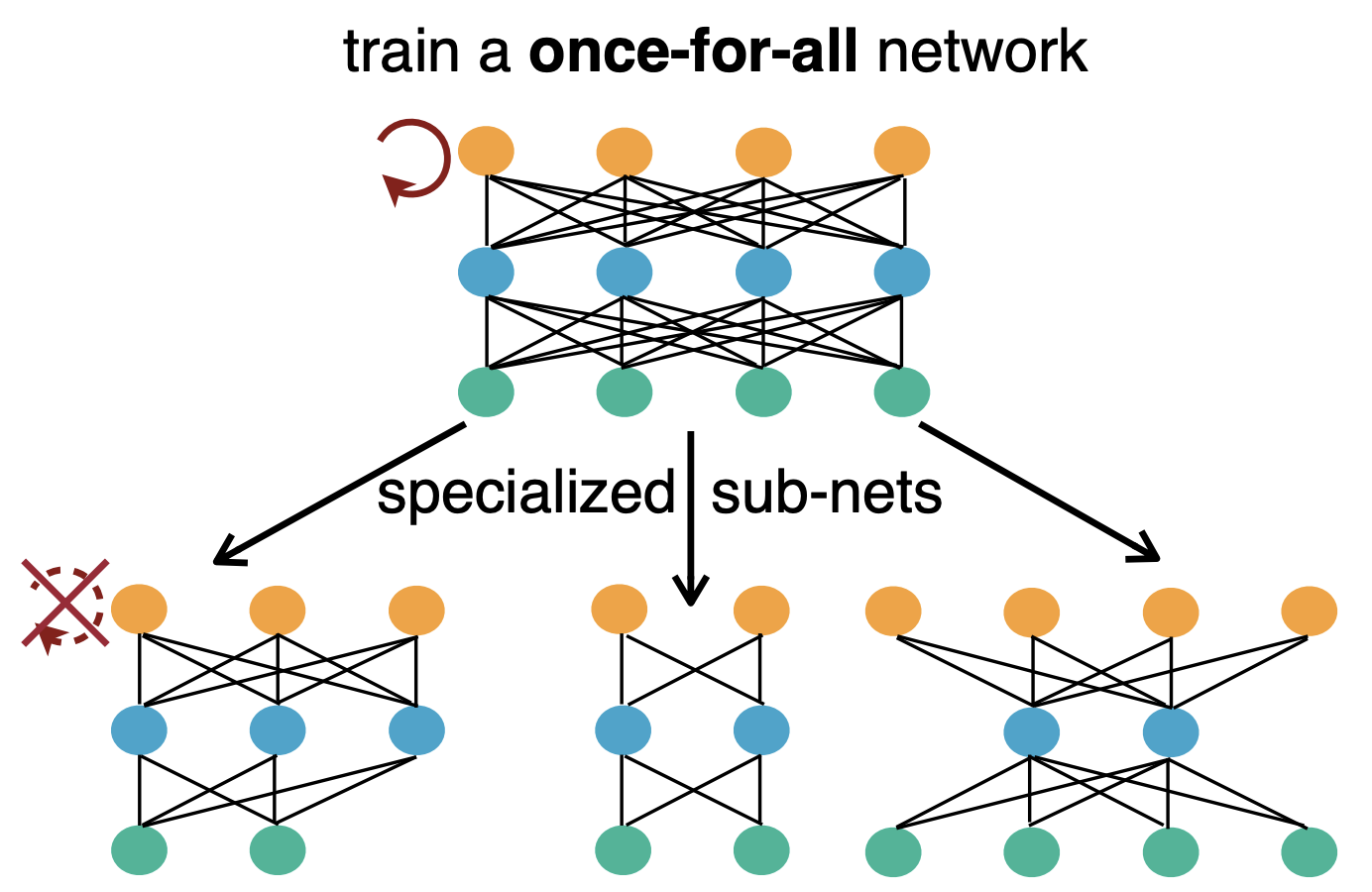
Исследователи предлагают One For All модель для автоматизации поиска архитектуры нейросети. Основное отличие OFA от предыдущих решений заключается в том, что не нужно отдельно продумывать и обучать модели для каждого отдельного сценария. One For All модель напрямую ищет оптимальную подсеть. В сравнении с state-of-the-art архитектурами поиска OFA нейросеть была в 14 раз быстрее, чем ProxylessNAS, в 16 раз быстрее, чем FBNet, и в 1,142 раз быстрее, чем MnasNet.
В чем проблема
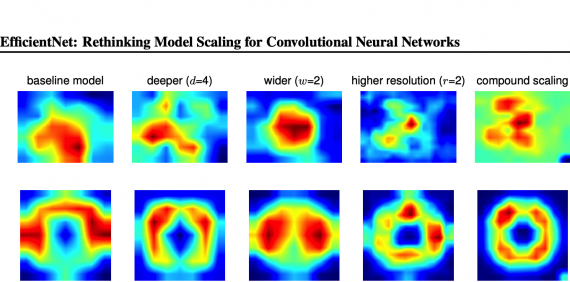
Задача исследования заключалась в том, чтобы отфильтровать веса нейросети так, чтобы подсеть не теряла в точности по сравнению с полной нейросетью. Важно, чтобы при сравнении конфигурации сжатой и полной нейросетей были одинаковы: глубина, ширина, размер кернела и разрешение. OFA нейросеть поддерживает более широкое пространство поиска подсетей (10^(19) подсетей), чем прошлые AutoML методы.
Чтобы эффективно обучить OFA модель, исследователи предлагают алгоритм прогрессивного сжатия. Алгоритм позволяет обучить полную нейросеть и дообучить нейросеть так, чтобы она поддерживала различные размеры подсетей. Использование алгоритма прогрессивного сжатия позволяет увеличить точность найденной подсети. В случае когда алгоритм не использовали, точность подсети была ниже на 2%.
Как модель работает
Стандартные AutoML методы применяют алгоритмы поиска, чтобы найти оптимальную подсеть. Исследователи предлагают случайно отбирать подсети из полной нейросети OFA. Затем на основе этих подсетей рассчитываются таблицы точности и скрытых состояний (latency tables). Это позволяет делать прямые запросы к таблицам. Такой подход не растет линейно в сложности, как другие AutoML алгоритмы.
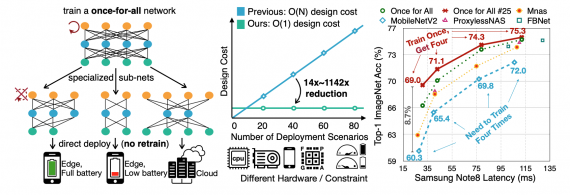
OFA нейросети, обученные на ImageNet, получают результаты, которые сравнимы с независимо обученными моделями. Несмотря на это, OFA требует в 12 раз больше ресурсов для обучения, чем независимо обученные модели. Исследователи предлагают, что эта ресурсоемкость алгоритма может быть уменьшена.