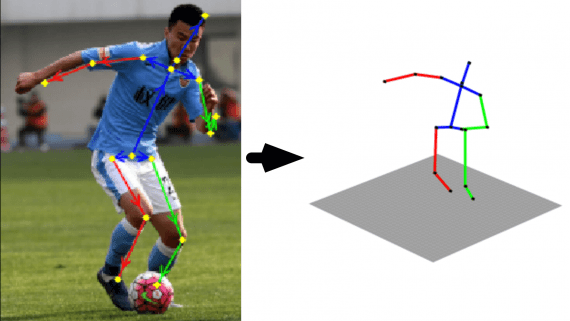
HybridPose — это нейросетевая модель для распознавания позы объекта в 6D. Модель принимает на вход изображение объекта и предсказывает ключевые точки, векторы границ и отношение позы объекта относительно его стандартного положения. Использование промежуточных представлений позы объекта улучшает устойчивость предсказаний модели. Например, это актуально для случая с наложением объектов друг на друга. На датасете Occlusion Linemod нейросеть обошла предыдущий state-of-the-art на 67.4% в точности предсказанных поз.
Стандартные подходы для 6D распознавания позы используют одно представление для кодирования данных позы объекта. HybridPose использует промежуточное представление, в котором хранится информация о геометрии объекта: ключевые точки, векторы границ (edge vectors) и смещение положения объекта от его стандартного положения (symmetry correspondence).
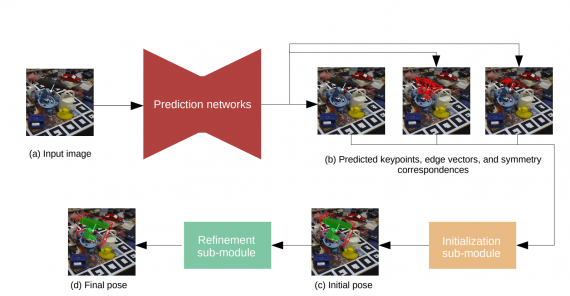
Архитектура нейросети
На вход HybridPose принимает изображение с объектом известного класса, которое было сделано с помощью стенопа с известными параметрами. На выходе модель отдает 6D расположение объекта относительно камеры. HybridPose использует три предсказательные сети чтобы определить:
- Набор ключевых точек объекта (keypoints);
- Набор связей между точками (edges between keypoints);
- Симметрическое соответствие между пикселями изображения (symmetry correspondences)
Оценка работы модели
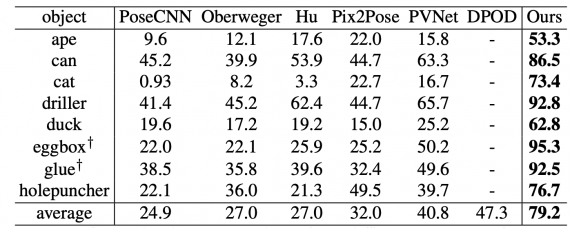
Исследователи протестировали модель на датасете Linemod. В качестве метрики использовали ADD(-S) точность. ADD(-S) точность определяется как процент тестовых примеров, для которых средняя дистанция между предсказанием и истинным значением меньше 10%. HybridPose сравнили с базовыми подходами для оценки 6D позы объекта: PoseCNN, Oberweger et al., Hu et al., PVNet и DPOD. Ниже видно, что на сабсете Linemod HybridPose выдает более точные результаты. Occlusion Linemod — это часть датасета, которая состоит из изображений, на которых объекты перекрывают друг друга.