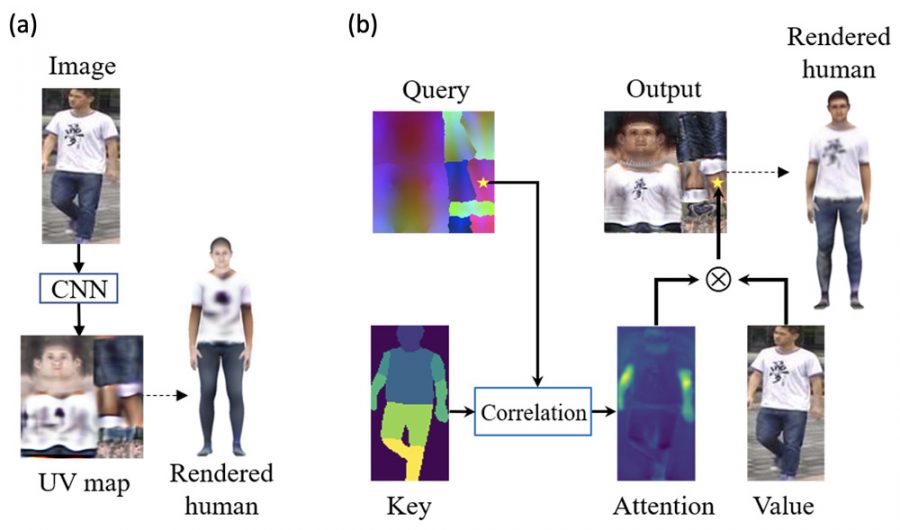
Texformer — фреймворк для оценки 3D-позы по одному изображению с использованием архитектуры трансформера. Точность восстановления позы у Texformer выше, чем у state-of-the-art моделей на основе сверточных нейросетей.
Архитектура модели приведена на рисунке ниже. Модуль внимания состоит из трех элементов:
- запросом является вычисленная заранее цветовая карта, получаемая путем проецирования координат стандартной трехмерной поверхности человека на UV-пространство.
- значением являются входное изображение и его двумерные координаты;
- ключом являются входное изображение и двумерная карта сегментации.
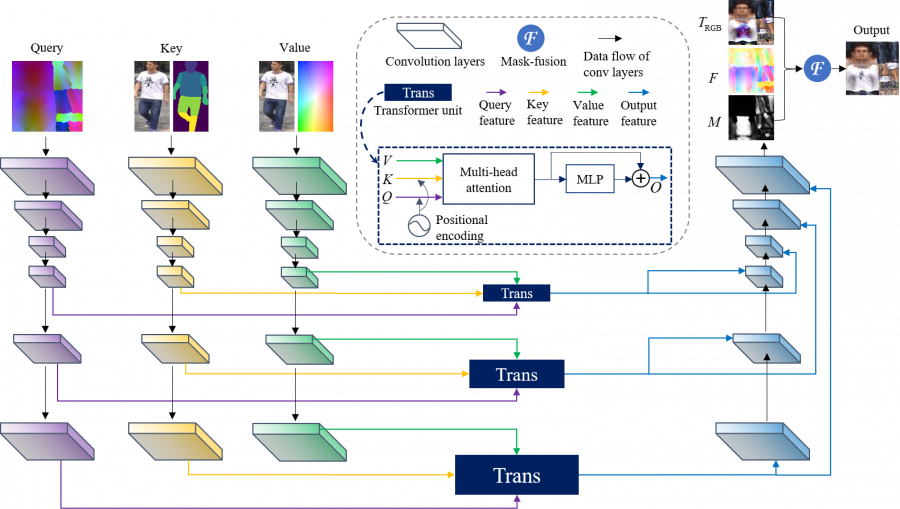
Запрос, значение и ключ заводятся в три сверточные нейросети для трансформации в пространстве признаков. Затем данные признаки заводятся в трансформер для генерации выходных признаков, которые обрабатываются в другой сверточной нейросети, генерирующей RGB UV-карту, текстуру и маску. Финальная выходная UV-карта получается путем наложения RGB-карты и текстуры с помощью маски.
Сравнение Texformer с моделями на основе сверточных нейросетей:
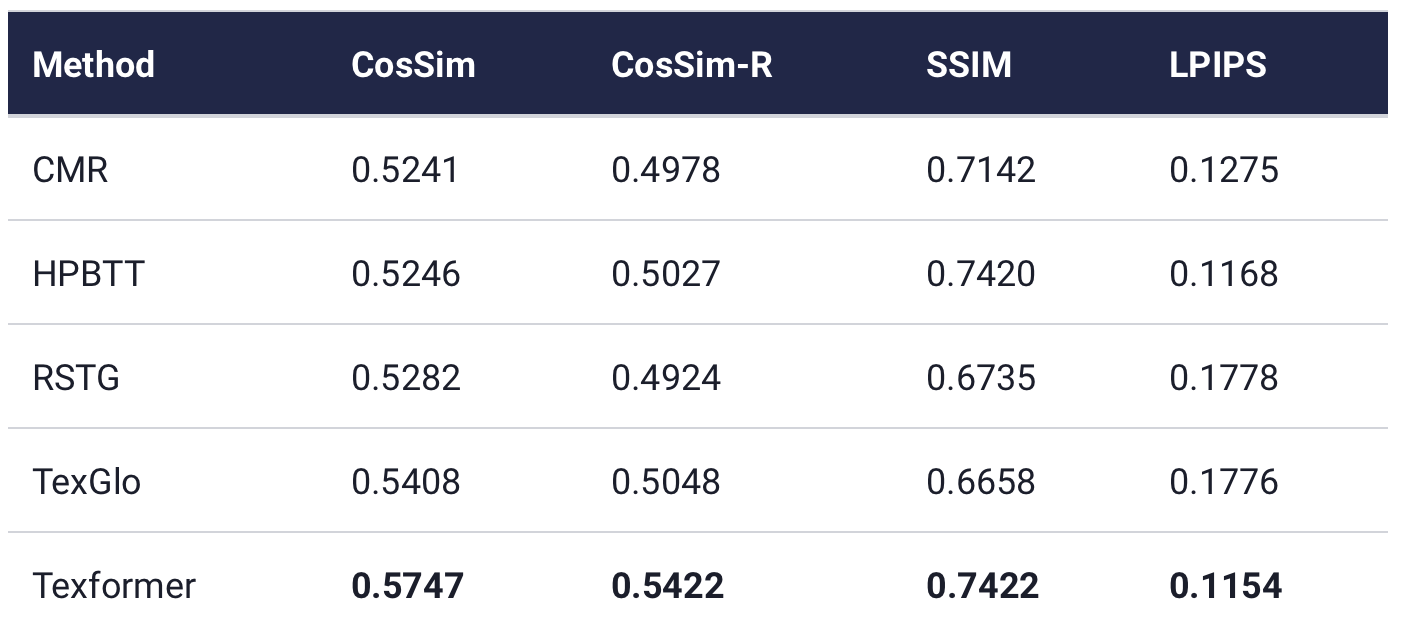
Фреймворк доступен в Github.