Дерево решений — логическая схема, позволяющие получить окончательное решение о классификации объекта после ответов на иерархически организованную систему вопросов. Стоит сказать, большинство высоко результативных решений на Kaggle — комбинация XGboost-ов, одного из вариантов деревьев решений, и очень качественного фичер-инжиниринга.
Один уровень
Стоящая за деревьями решений идея проста. Представим датасет, созданный путем записи времени ухода из дома и времени прихода на работу. Анализируя эти данные, можно увидеть, что в большинстве случаев выход из дома раньше 8:15 приводит к своевременному прибытию на работу, а выход после 8:15 — к опозданию.

Теперь этот паттерн можно выразить через дерево решений. В самой первой точке разветвления следует задать вопрос: “Выход из дома осуществляется раньше 8:15?”. Теперь есть две ветви — “да” и “нет”. Для согласованности будем считать положительный ответ левой веткой. Вводя такую границу решения, мы разбиваем данные на две группы. Хотя в таком случаем есть некоторые исключения и сложности, общее правило — разделение по времени с границей 8:15. Если вы выходите до 8:15, можете быть уверены, что попадете на работу вовремя. В противном случае — будьте уверены, что опоздаете.
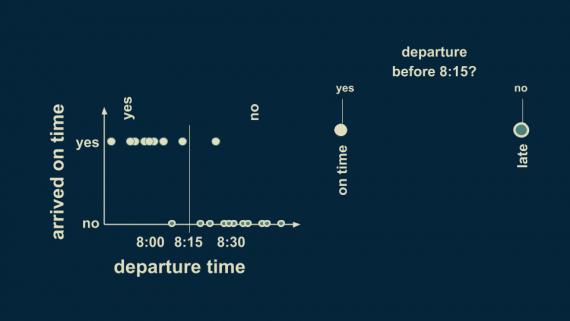
Это самое простое дерево решений, состоящее из одной пары ветвей.
Два уровня
Мы можем уточнить оценку пунктуальности с помощью разделения обеих ветвей. Если мы добавим дополнительные границы решений со значениями 8:00 и 8:30, можем получить более точное предсказание исхода.
Выход до 8:00 однозначно приведет к своевременному появлению на работе, тогда как с 8:00 до 8:15 — лишь к высокой вероятности прийти вовремя, но не к гарантии. Похожим образом ветвь с выходом после 8:15 делится на две ветви с решающим вопросом: “отправление до 8:30?”. Если ответ положительный, то есть большая вероятность опоздать, если же отрицательный — вы гарантированно опоздаете.
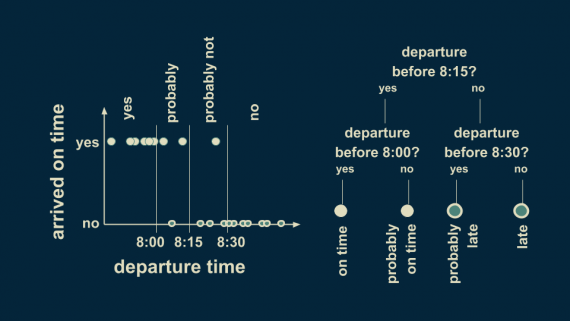
Это дерево решений имеет уже два уровня. В общем случае, они могут иметь столько уровней, сколько вы захотите. В большинстве случаем каждый узел (решающий вопрос) имеет только две ветви.
Рассматриваемый пример использует только один фактор и одну целевую переменную, которую необходимо предсказать. Фактором выступает время отправления, а целевая переменная — приедем ли мы вовремя. Целевая переменная категориальная, так как она имеет только два различных значения. Деревья решений с категориальной целевой переменной называются классифицирующими деревьями.
Многомерное дерево решений
Можно расширить этот пример на случай нескольких предикторных переменных. Рассмотрим время выхода и день недели. Начнем собирать данные с понедельника (день 1), тогда суббота = 6, воскресенье = 7. Исследуя данные, можно видеть, что в субботу и воскресенье зеленые точки смещены в левую сторону. Это означает, выход в 8:10 является достаточным, чтобы успеть на работу вовремя в будний день, но не достаточным в выходные.

Чтобы отобразить этот факт в дереве решений, можем начать также, как и в первом примере, установив границу решений как 8:15. Выход после 8:15 скорее всего приведет к опозданию. Выход из дома до 8:15 — не показательный фактор, хотя ранее мы предполагали, что это гарантирует прибытие вовремя. Теперь мы видим по данным, что это не является полной правдой.

Чтобы сделать более точную оценку для выходных, разделим левую ветвь на выходные и будние дни. Теперь выход из дома до 8:15 в будний день гарантирует своевременное прибытие на работу. Для выходного дня в большинстве случаев это тоже вовремя, но не всегда. Мы обновили дерево решений с помощью узла, который отражает новую решающую границу.

Можно еще сильнее уточнить оценку разделением ветки с отправлением до 8:15 в выходной день на отправление до 8:00 и после. Отправление до 8:00 скорее всего приведет к своевременному появлению на работе, а в интервале с 8:00 до 8:15 к опозданию с большой вероятностью. Получилось двумерное дерево решений, аккуратно поделенное на 4 различных региона. Два из них соответствуют прибытию вовремя, два — опозданию.

Это трехуровневое дерево. Отметим, что не обязательно все ветки должны простираться на одинаковое количество уровней.
Регрессионное дерево решений
Рассмотрим случай с непрерывной целевой переменной, а не категориальной. В случае использования модели для предсказания непрерывных количественных переменных дерево называется регрессионным. Мы посмотрели на одномерные и двумерные классификационные деревья, теперь настало время взглянуть на регрессионные.
Перед нами стоит задача оценки времени пробуждения в зависимости от возраста человека. Корень нашего регрессионного дерева — оценка всего датасета. В этом случае, если требуется оценка без знания возраста конкретного человека, разумным предположением будет 6:25. Это и будет корнем нашего дерева.
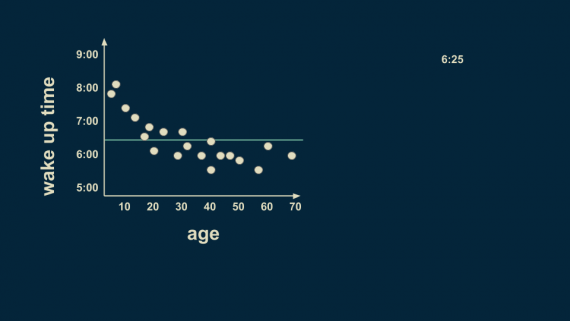
Разумное первое разбиение — возраст 25 лет. В среднем, люди моложе 25 лет просыпаются в 7:05, а старше 25 — в 6 часов.
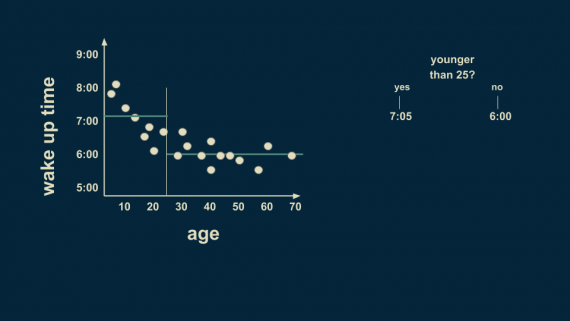
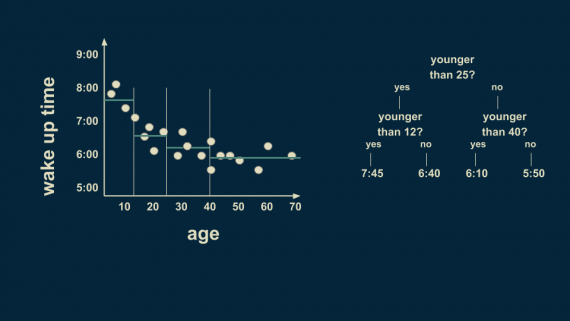
Существует всё еще много вариаций разбиения на возрастные группы, поэтому мы можем разделить выборку еще раз. Теперь можно предположить, что люди младше 12 лет просыпаются в 7:45, а в возрасте от 12 до 25 лет — в 6:40.
Группа людей старше 25 лет тоже может быть разумно разделена. Люди в возрасте от 25 до 40 лет просыпаются в среднем в 6:10, а в возрасте от 40 до 70 — в 5:50.
Поскольку наблюдается большая неоднозначность для младшей группы, можем разделить её еще раз. Теперь границей решений будет возраст 8 лет, что позволит более точно подстроиться под данные. Также можно разделить возрастную группу в диапазоне от 40 до 70 лет на отметке 58 лет. Отметим, мы добиваемся того, чтобы в каждом листе дерева находилось только одно или два значения из данных. Но это условие опасно тем, что может приводить к переобучению, о котором мы поговорим в скором времени.
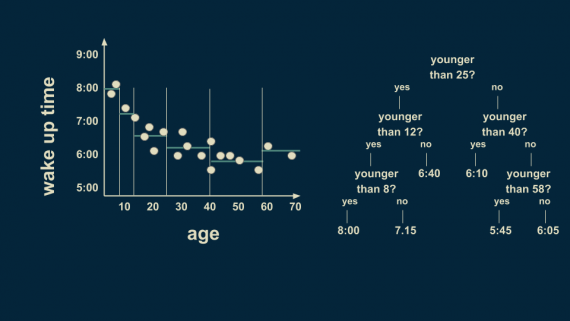
В результате необходимо получить численную оценку в зависимости от возраста. Если требуется оценить время пробуждения для 36-летнего человека, можно начать с самой верхушки дерева. Этот процесс описывается следующим образом:
- “Младше 25 лет?” — Нет; идем вправо.
- “Младше 40 лет?” — Да; идем влево.
- Оценка для этого листа — 6:10.
Структура дерева решений позволяет сортировать людей разных возрастов на соответствующие им ячейки и делать оценки времени пробуждения.
Конечно, существует способ расширения регрессионного дерева на случай двух предсказательных переменных. Если рассматривать не только возраст человека, но также и месяц года, можно получить явный и информативный паттерн. В Северной Америке дни длиннее в летние месяцы, и становится светлее раньше по утрам. В нашем нереалистичном примере дети и подростки не обременены строгим расписанием работы или учебы в школе, а их время пробуждения зависит только от того, когда восходит солнце. С другой стороны, взрослым присущ более стабильный распорядок дня, лишь немного зависящий от сезона. Но даже так, для старшего поколения характерно чуть более раннее время пробуждения.
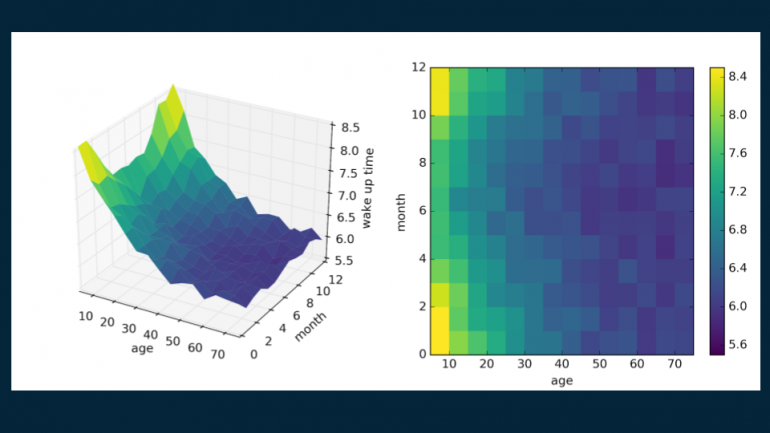
Разветвленное дерево
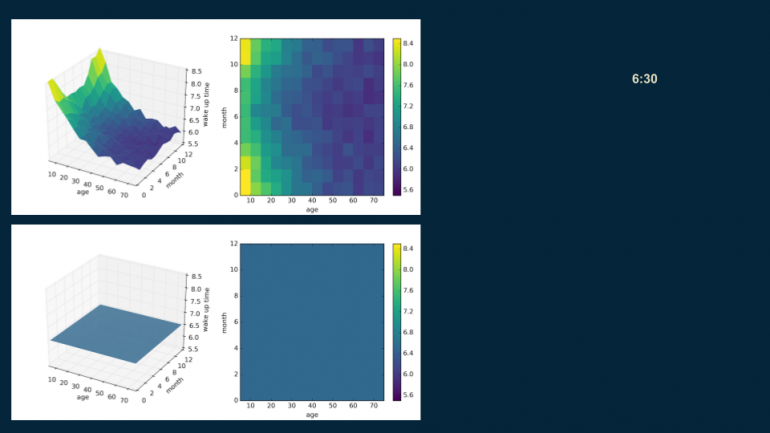
Мы создаем дерево решений почти таким же образом, как и прошлое. Начинаем с корня — единичная оценка, которая грубо описывает весь набор данных — 6:30. (Здесь представлен код для визуализации с помощью библиотеки matplotlib).
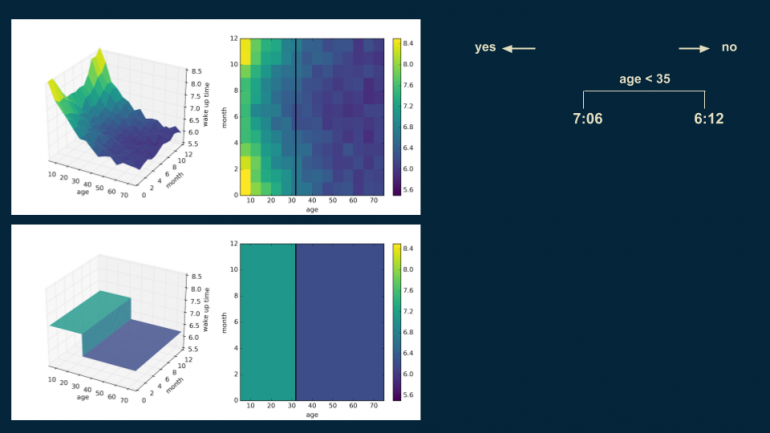
Далее ищем подходящее место для установления границы решений. Делим данные по возрасту на отметке 35 лет, создавая две части:
- популяция младше 35 лет с временем пробуждения 7:06
- популяция старше 35 лет с временем пробуждения 6:12
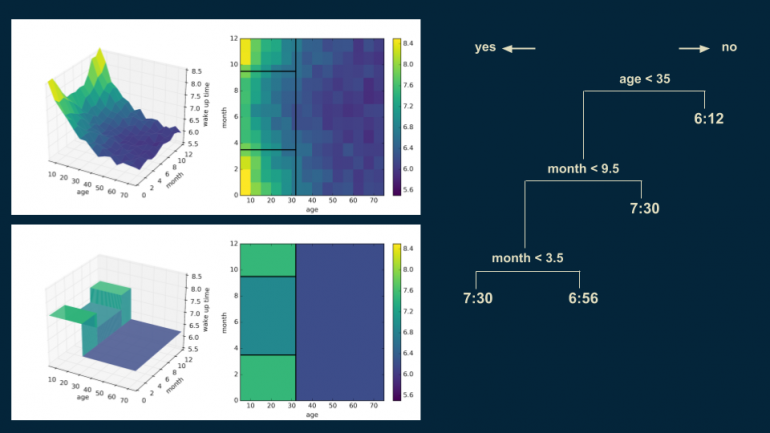
Повторяем этот процесс, разделяя более молодую популяцию на два уровня — событие произошло до середины сентября и событие произошло до середины марта, соответственно. Такое разделение изолирует зимние месяцы от летних. Время пробуждения в зимние месяцы — 7:30 для людей младше 35 лет, а для летних — 6:56.
Теперь можем вернуться в узел с популяцией старше 35 лет и разделить его еще раз с границей в 48 лет для более точного представления.
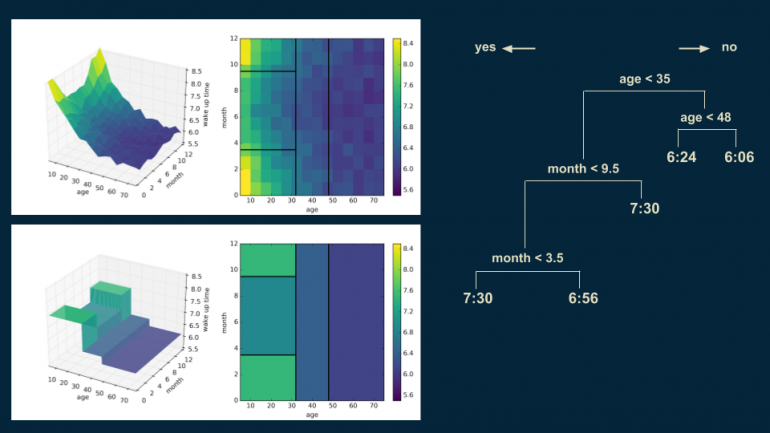
Таким же образом разделим группу младше 35 лет для зимних месяцев добавлением границы в 18 лет. Человек младше 18 в зимние месяцы просыпается в 7:54, в противном случае, в 6:48.
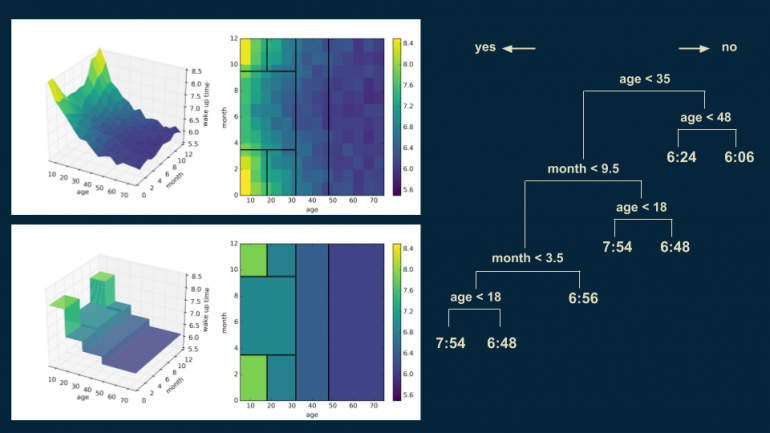
Можно увидеть, что на графике начинают появляться высокие угловые пики. При каждом дополнительном разделении форма модели дерева решений становится более похожа на оригинальные данные. Кроме того, можно заметить, что в верхнем правом углу графика решающая граница начинает делить датасет на регионы примерно одинакового цвета.
Следующее разделение продолжает этот тренд, фокусируясь на группе младше 35 в летние месяцы, устанавливает границу в возрасте 13 лет. Форма модели становится всё более похожа на форму данных.
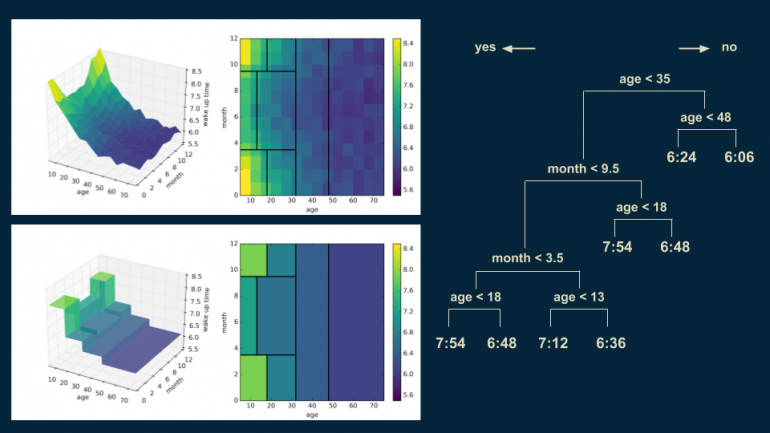
Этот процесс продолжается до тех пор, пока модель не станет хорошо представлять плавные тренды, соответствующие данным. Каждый решающий регион постепенно должен становиться меньше, тогда как аппроксимация лежащей в основе данных функции улучшается.
В тоже время деревья решений не лишены недостатков, важнейший из которых — переобучение. Возвращаясь к примеру регрессионного дерева с одной переменной (предсказание времени пробуждения по данным о возрасте), представим, что мы продолжаем разделять ось возраста до тех пор, пока в каждой ячейке не окажется один или два объекта из данных.
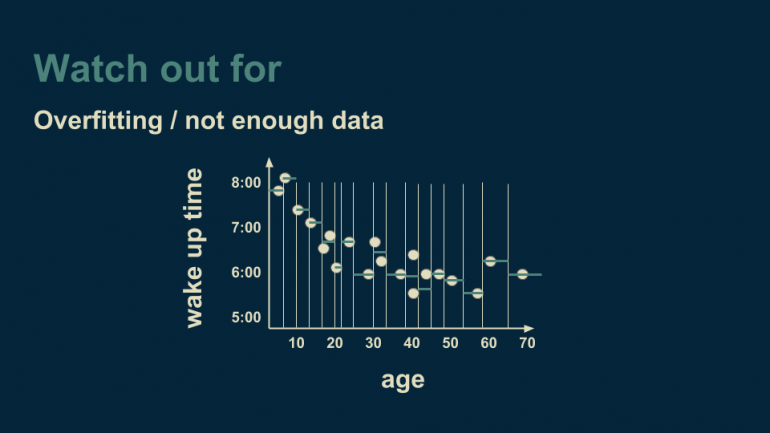
Когда мы дошли до этой стадии, дерево объясняет и описывает данные очень хорошо. Даже слишком хорошо. Такая модель не только находит лежащие в основе данных тренды (гладкая кривая, по которой следуют данные), но также реагирует и на шумы (несмоделированные отклонения), характерные для исследуемых данных. Если будет необходимо применить эту модель и предсказать время пробуждения на новых данных, шум из тренировочного сета будет делать предсказание менее точным. В идеале мы хотим, чтобы дерево решений находило только тренды, но не реагировало на шумы. Один из способов защититься от переобучения — убедиться, что в каждом листе нашего дерева находится больше чем один или несколько объектов. Такой способ позволяет усреднением избавиться от шума.
Другая вещь, на которую стоит обратить внимание — большое количество переменных. Мы начали с одномерного регрессионного дерева, затем добавили данные о месяцах, чтобы трансформировать дерево в двумерное. Такой метод не придает значение количеству измерений, которые у нас есть. Можно, например, добавить широту, интенсивность физической нагрузки человека в определенный день, индекс массы тела или любые другие переменные, которые могут быть релевантны для нашей задачи.
Чтобы визуализировать многомерные данные, используем прием, предложенный Джеффри Хинтоном — исследователем в области искусственных нейронных сетей. Он рекомендует следующее: “Чтобы иметь дело с гиперплоскостью в четырнадцатимерном пространстве, представьте себе трехмерное пространстве и скажите самому себе очень громко “четырнадцать.”
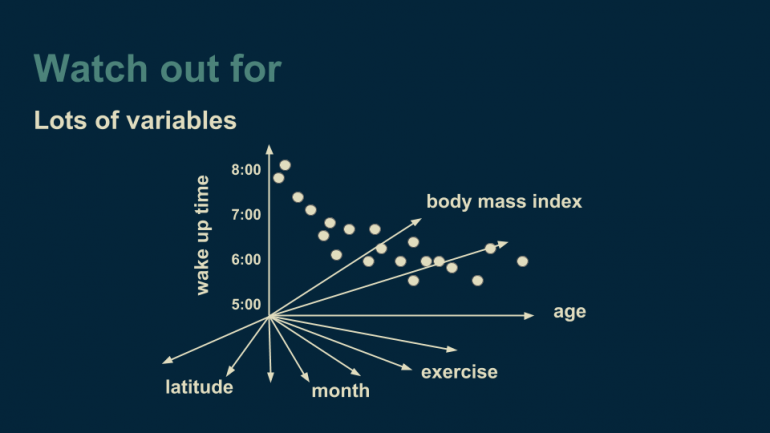
Проблема, возникающая при работе с многими переменными, связана с решением о том, какая из переменных должна идти в ветку при построении решающего дерева. Если имеется много переменных, то требуется большое количество вычислений. Также, чем больше переменных мы добавляем, тем большее количество данных нам необходимо, чтобы достоверно выбирать между ними. Легко попасть в ситуацию, где количество объектов в данных сравнимо с количеством переменных. Если наш датасет представлен в виде таблицы, то такая ситуация соответствует совпадению количества строк и столбцов. Существуют методы для борьбы с такими ситуациями, например, случайный выбор переменной для разделения в каждой ветке, но это требует повышенного внимания.
Вы можете свободно пользоваться всеми преимуществами силы деревьев решений, пока следите за местами, где модель может терпеть неудачи. Деревья решений — фантастический инструмент, когда вы хотите сделать как можно меньше предположений о ваших данных. Они обобщают и могут находить нелинейные зависимости между предсказательной и целевой переменной также хорошо, как и влияние одной предсказательной переменной на другую. Если имеется достаточное количество данных для осуществления необходимых разбиений, деревья решений могут выявлять квадратичные, экспоненциальные, циклические и другие зависимости. Деревья могут также находить неплавное поведение, резкие прыжки и пики, которые другие модели, такие как линейная регрессия или искусственные нейронные сети, могут скрывать.
Поэтому в задачах с большим объемом данных деревья решений показывают более высокие результаты, чем другие методы.