
Вам должны быть знакомы моменты, когда вы смотрите на код и удивляетесь: “Почему я использую в коде эти три параметра, в чем отличие между ними?”. И это неспроста, так как параметры выглядят очень похожими.
Epoch - Batch Size - Iteration
Чтобы выяснить разницу между этими параметрами, требуется понимание простых понятий, таких как градиентный спуск.
Градиентный спуск
Это ни что иное, как алгоритм итеративной оптимизации, используемый в машинном обучении для получения более точного результата (то есть поиск минимума кривой или многомерной поверхности).
Градиент показывает скорость убывания или возрастания функции.
Спуск говорит о том, что мы имеем дело с убыванием.
Алгоритм итеративный, процедура проводится несколько раз, чтобы добиться оптимального результата. При правильной реализации алгоритма, на каждом шаге результат получается лучше. Таким образом, итеративный характер градиентного спуска помогает плохо обученной модели оптимально подстроиться под данные.
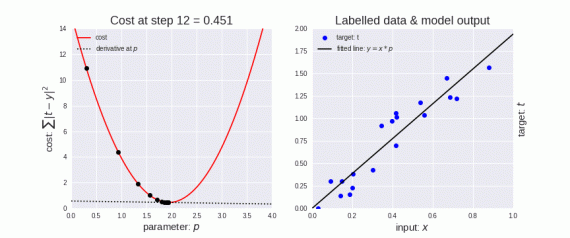
У градиентного спуска есть параметр, называемый скоростью обучения. На левой верхней картинке видно, что в самом начале шаги больше, то есть скорость обучения выше, а по мере приближения точек к краю кривой скорость обучения становится меньше благодаря уменьшению размера шагов. Кроме того, значение функции потерь (Cost function) уменьшается, или просто говорят, что потери уменьшаются. Часто люди называют функцию потерь Loss-функцией или просто «Лосс». Важно, что если Cost/Loss функция уменьшается, то это хорошо.
Как происходит обучение сети
Исследователи работают с гиганскими объемами данных, которые требуют соответствующих затрат ресурсов и времени. Чтобы эффективно работать с большими объемами данных, требуется использовать параметры (epoch, batch size, итерации), так как зачастую нет возможности загрузить сразу все данные в обработку.
Для преодоления этой проблемы, данные делят на части меньшего размера, загружают их по очереди и обновляют веса нейросети в конце каждого шага, подстраивая их под данные.
Epochs
Произошла одна эпоха (epoch) — весь датасет прошел через нейронную сеть в прямом и обратном направлении только один раз.
Так как одна эпоха слишком велика для используемой вычислительной мощности, датасет делят на маленькие партии — батчи.
Почему мы используем более одной эпохи
Вначале не понятно, почему недостаточно одного полного прохода датасета через нейронную сеть, и почему необходимо пускать полный датасет по сети несколько раз.
Нужно помнить, что мы используем ограниченный датасет, чтобы оптимизировать обучение и подстроить кривую под данные. Делается это с помощью градиентного спуска — итеративного процесса. Поэтому обновления весов после одного прохождения недостаточно.
Одна эпоха приводит к недообучению, а избыток эпох — к переобучению:
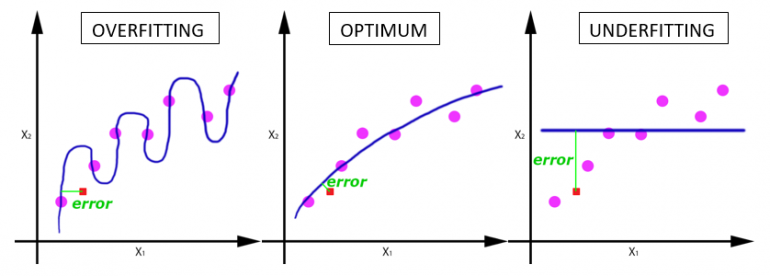
С увеличением числа эпох, веса нейронной сети изменяются все большее количество раз. Кривая с каждый разом лучше подстраивается под данные, переходя последовательно из плохо обученного состояния (последний график) в оптимальное (центральный график). Если вовремя не остановиться, то может произойти переобучение (первый график) — когда кривая очень точно подстроилась под точки, а обобщающая способность исчезла.
Какое количество эпох правильное?
На этот вопрос нет единственного точного ответа. Для различных датасетов оптимальное количество эпох будет отличаться. Но ясно, что количество эпох связано с разнообразием в данных. Например, в вашем датасете присутствуют только черные котики? Или это более разнообразный датасет?
Batch Size в нейронных сетях
Размер батча — это общее число тренировочных объектов, представленных в одном батче.
Отметим: Размер батча и число батчей — два разных параметра.
Что такое батч?
Нельзя пропустить через нейронную сеть разом весь датасет. Поэтому делим данные на пакеты, сеты или партии, так же, как большая статья делится на много разделов — введение, градиентный спуск, эпохи, Batch size и итерации. Такое разбиение позволяет легче прочитать и понять статью.
Итерации
Итерации — число батчей, необходимых для завершения одной эпохи.
Отметим: число батчей равно числу итераций для одной эпохи.
Например, собираемся использовать 2000 тренировочных объектов.
Можно разделить полный датасет из 2000 объектов на батчи размером 500 объектов. Таким образом, для завершения одной эпохи потребуется 4 итерации.
Получились следующие параметры:
Batch size = 500 Iterations = 4 Epoch = 1







Картинки про переобучение и недообучение нужно местами поменять, зачем мозг ломать? Про batches так и не раскрыли суть. Что будет, когда все объекты одного пакета пройдут через нейронку? Как посчитается… Подробнее »
Спасибо, очень хорошая статья!