Ни одна современная камера не сравнится с глазами человека. Если человек смотрит на восход и закат, когда виден огромный разрыв между светлыми и темными тонами, он в состоянии разглядеть мельчайшие детали. Камерам же сложно в этих ситуациях. В результате получается фотографии с угольно чёрными тенями и слепяще белыми светлыми участками.

Исследователи из университета Гонконга и Даляньского технологического университета предложили новый метод преобразования изображений в визуально привлекательное, с помощью глубоких нейронных сетей.
Предлагаемый метод исправляет изображение со слишком или недостаточно долгой экспозицией и привносит много деталей. Метод работает со стандартным LDR изображением (изображение LDR — это изображение с низким динамическим диапазоном), и создает улучшенное изображение, всё ещё в диапазоне LDR, но визуально обогащенное восстановленными деталями. Глубокая нейронная сеть возвращает детали, которые лежат в диапазоне HDR (высокий динамический диапазон), но уменьшились в диапазоне LDR. Здесь и кроется вся магия.
Как это работает?
Новый метод называется Deep Reciprocating HDR Transformation, он работает путем применения взаимного преобразования, использующего две глубокие нейронные сети. Идея работы проста: взяв образ LDR, детали реконструируются в области HDR и изображение переводится обратно в область LDR, обогащенную деталями. Хотя это звучит просто, есть два трюка, о которых расскажем ниже.
Чтобы сделать взаимное преобразование, используются две сверточные нейронные сети (CNN). Первая называется сетью HDR оценки, она принимает входное изображение, кодирует в скрытое представление более низкого диапазона, а затем декодирует это представление для восстановления HDR изображения. Вторая, называемая сетью LDR коррекции, выполняет обратное преобразование: принимает оцененное HDR изображение из первой сети и выводит исправленное LDR изображение. Обе сети — простые автокодировщики, кодирующие данные в скрытое представление размера 512.
Эти две сети обучаются совместно и имеют одинаковую архитектуру. Однако, как уже упоминалось выше, есть два трюка: оптимизация и функция затрат, которые дают решение проблемы.

Сеть оценки HDR
Первая сеть обучается прогнозированию данных HDR, она обучена с использованием ELU активизации и нормализации пакетов, а функция потерь — простая средняя квадратичная ошибка. И здесь зарыт первый трюк: функция потери MSE определяется с использованием разности между выходной и основной истиной, с измененными константами, используемыми для преобразования данных HDR в LDR.
Коррекция LDR
Вторая сеть берет результат первой сети и дает исправленное LDR изображение. Второй трюк входит в эту часть: результат первой сети (оценка HDR) , находящийся еще в области LDR (это происходит из первого трюка) изменяется до подачи во вторую сеть. Таким образом, этот результат преобразуется в область HDR с помощью гамма-коррекции, а затем применяется логарифмическая операция.
Две сети автокодировщика имеют одинаковую архитектуру и используют пропускные соединения. Полная архитектура сети:
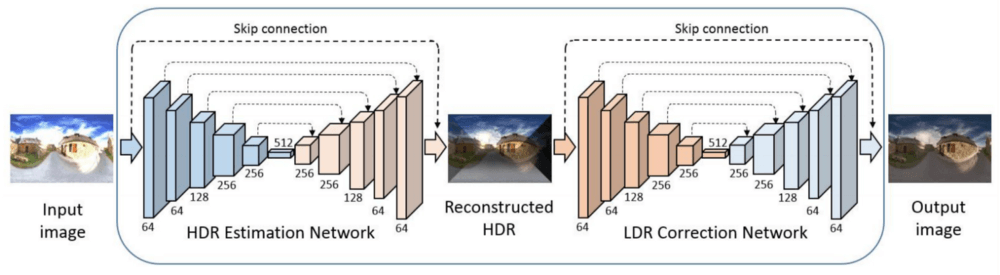
Каждая сеть состоит из пяти convolutional (сверточных) и пяти deconvolution (развертывающихся) слоев:
Conv 1 Layer: 9 x 9 размер ядра, 64 карты признаков
Conv 2 Layer: 5 x 5 размер ядра, 64 карты признаков
Conv 3 Layer: 3 x 3 размер ядра, 128 карт признаков
Conv 4 Layer: 3 x 3 размер ядра, 256 карт признаков
Conv 5 Layer: 3 x 3 размер ядра, 256 карт признаков
Скрытое представление: 1 x 512
Deconv 1 Layer: 3 x 3 размер ядра, 256 карт признаков
Deconv 2 Layer: 3 x 3 размер ядра, 256 карт признаков
Deconv 3 Layer: 3 x 3 размер ядра, 128 карт признаков
Deconv 4 Layer: 5 x 5 размер ядра, 64 карты признаков
Deconv 5 Layer: 9 x 9 размер ядра, 64 карты признаков
Обучение проводилось с использованием алгоритма оптимизатора ADAM с начальной скоростью обучения 1e-2.
Набор данных
Два набора данных используются для обучения и тестирования метода: набор данных городской панорамы и уличной панорамы Sun360. Также, авторы отмечают, что использовали Photoshop при создании правдивых LDR изображений с человеческим контролем для промежуточной задачи. Размер тренировочного набора, который используется для тренировки обеих сетей, составляет 40 000 изображений (исходное изображение LDR, истинное HDR и истинное LDR изображение).
Результаты
Как утверждают авторы, предложенный метод работает лучше современных аналогов. Оценка проводилась путем сравнения с Cape, WVM, SMF, L0S и DJF.
Оценка сложная, так как главной целью является создание визуально приятных изображений, которые трудно поддаются количественной оценке, а также субъективны. Однако авторы используют ряд различных оценочных показателей. Авторы использовали HDR-VDP-2 характеристику для оценки первой сети, которая отражает восприятие человека, а для оценки метода и сравнения с существующими методами использовались показатели: PSNR, SSIM, FSIM.
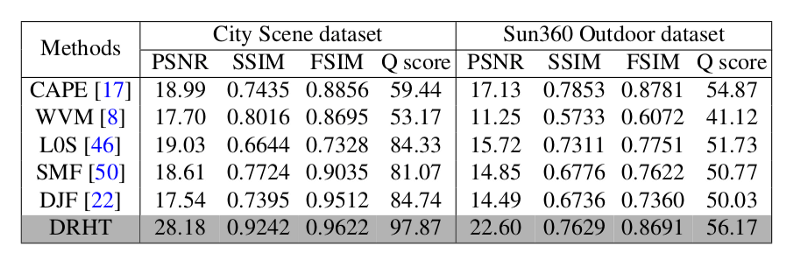
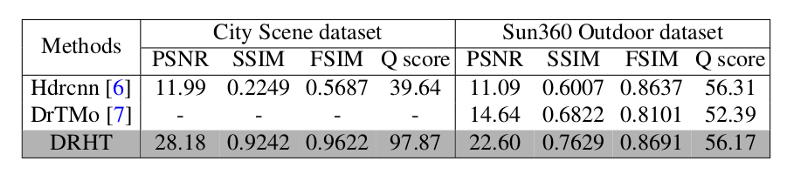
Визуальная оценка также предоставляется там, где значимые результаты предлагаемого метода видны рядом с результатами других существующих методов.

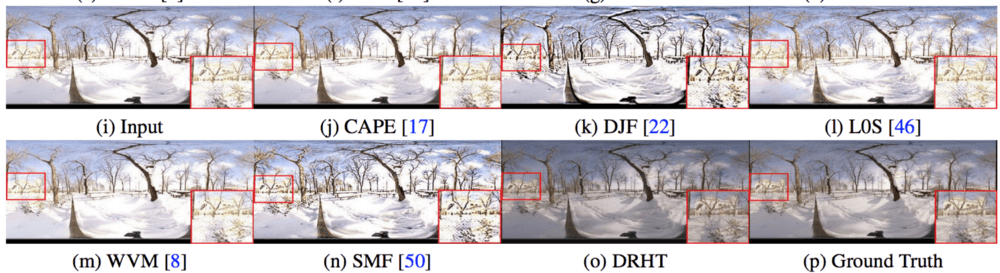
Предложенный метод показывает, что скрытые детали в переэкспонированных или недоэкспонированных изображениях, хорошо восстанавливаются, а глубокое обучение оказалось успешным в этой важной и нетривиальной задаче.