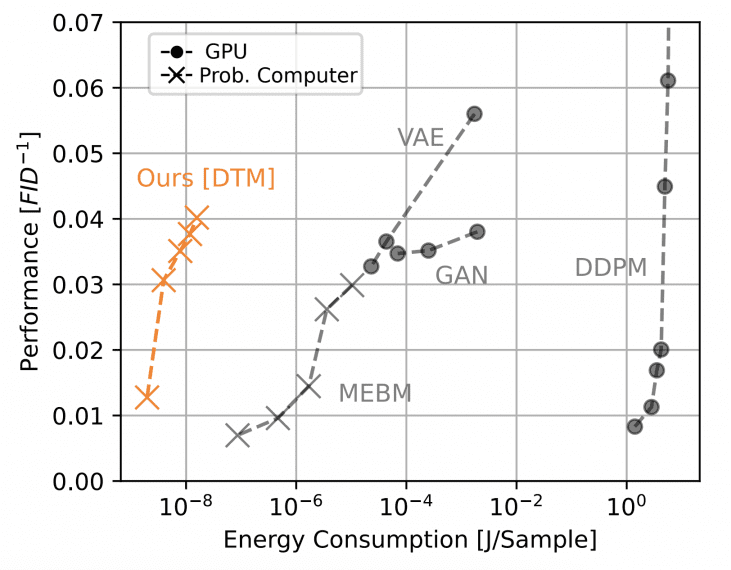
Исследователи из Extropic Corporation представили эффективную аппаратную архитектуру для вероятностных вычислений, основанную на Denoising Thermodynamic Models (DTM). Анализ показывает, что устройства на базе этой архитектуры могут достичь паритета производительности с GPU на простом бенчмарке генерации изображений, потребляя при этом примерно в 10,000 раз меньше энергии. DTM представляют собой последовательную композицию Energy-Based Models (EBM), реализованных на аппаратном уровне через транзисторные генераторы случайных чисел.
Архитектура Denoising Thermodynamic Computer
Традиционные подходы к вероятностным вычислениям использовали монолитные EBM для прямого моделирования распределений данных. Это создавало фундаментальную проблему mixing-expressivity tradeoff: чем точнее модель описывает сложные данные, тем сложнее из неё генерировать сэмплы.
Причина в структуре энергетического ландшафта — функции, которая присваивает каждому возможному варианту данных значение «энергии». Данные, похожие на обучающую выборку, получают низкую энергию (долины на ландшафте), непохожие — высокую (горы).
Например, если модель обучена на фотографиях датасета Fashion-MNIST, содержащим изображения одежды:
- Низкая энергия (долина): чёткое изображение ботинка, платья или футболки
- Высокая энергия (гора): случайный шум, размытое пятно, нечитаемые пиксели
Для сложных данных ландшафт содержит множество изолированных долин — их называют модами (modes). Каждая мода соответствует отдельной категории данных: одна мода для изображений обуви, другая для платьев, третья для футболок. Алгоритм генерации должен «путешествовать» по этому ландшафту, но вероятность перехода между модами через энергетический барьер высотой ΔE экспоненциально мала: P ∝ e^(-ΔE).
Чтобы перейти от генерации ботинок к генерации платьев, алгоритму нужно пройти через область данных, непохожих на обучающую выборку (подняться на гору между модами), что происходит крайне редко. В результате алгоритм застревает в одной категории на тысячи итераций, что делает обучение нестабильным, а генерацию — энергетически затратной.
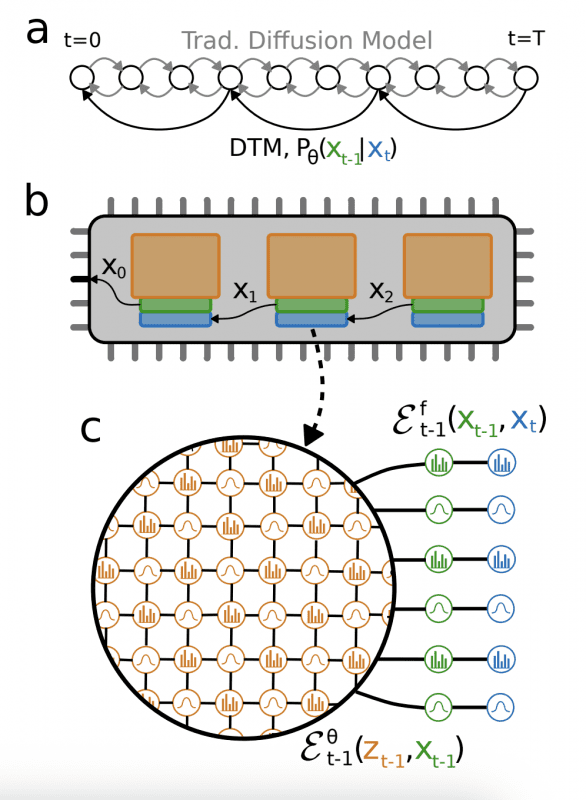
DTM решают эту проблему через декомпозицию: вместо одной EBM со сложным многомодальным ландшафтом используется цепочка простых EBM с пологими ландшафтами, по которым алгоритм сэмплирования движется эффективно. Каждая EBM выполняет небольшое преобразование — один шаг постепенного удаления шума, а последовательная композиция преобразований моделирует полное распределение данных без накопления сложности в одной модели.
Архитектура DTCA (Denoising Thermodynamic Computer Architecture) строится на простом принципе: процесс добавления шума к данным реализуется через локальные связи между последовательными состояниями. Каждая аппаратная EBM в цепочке отвечает за один шаг удаления шума — она получает зашумлённое изображение и восстанавливает чуть менее зашумлённую версию.
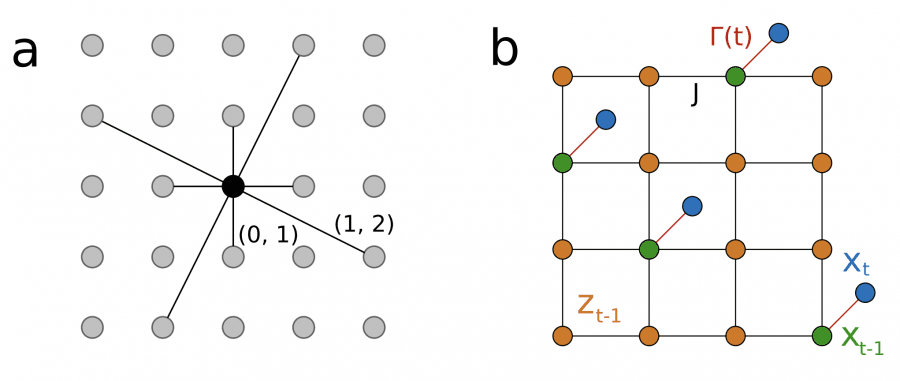
Энергетическая функция каждой EBM состоит из двух компонент. Первая — фиксированная часть, которая связывает текущее состояние с предыдущим (реализует процесс зашумления). Вторая — обучаемая часть, которая учится распознавать структуру данных. Критически важно, что фиксированная часть требует только простых парных взаимодействий между соседними переменными — каждый пиксель связан напрямую только с соответствующим пикселем на предыдущем шаге. Такая локальность идеально подходит для аппаратной реализации: не требуются длинные провода для связи далёких элементов чипа, что минимизирует энергопотребление и упрощает производство.
Транзисторный генератор случайных чисел
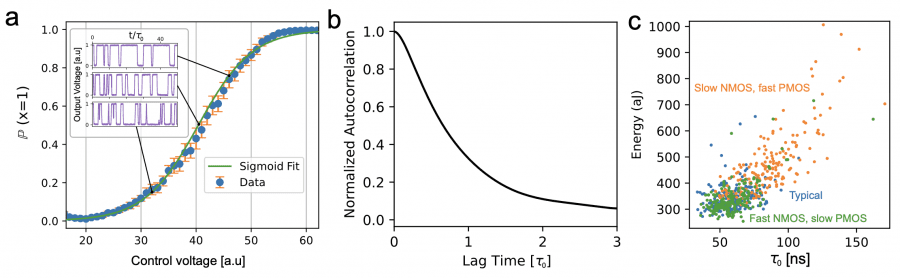
Главная инновация — полностью транзисторный генератор случайных чисел, использующий флуктуации тока в транзисторах, работающих в подпороговом режиме. Экспериментальные измерения показывают, что генератор производит случайные биты со скоростью около 10 миллионов бит в секунду, потребляя примерно 350 аттоджоулей на бит. Выходная характеристика генератора — вероятность получить единицу или ноль — описывается сигмоидой от управляющего напряжения. Эта особенность позволяет напрямую реализовать алгоритм сэмплирования Гиббса для машин Больцмана: изменяя напряжение, можно управлять вероятностью переключения каждого бита, что и требуется для условного обновления состояний в вероятностной модели.
Использование исключительно транзисторов устраняет неопределенность коммуникационных издержек между различными технологиями и позволяет принципиальное прогнозирование производительности устройства. Модель энергопотребления строится на основе измерений реальных схем, физических моделей и симуляций, учитывая вклады от RNG, схемы смещения, тактового сигнала и межъячеечных коммуникаций.
Результаты и сравнительный анализ
Экспериментальные результаты на наборе данных Fashion-MNIST демонстрируют превосходство DTM над монолитными EBM. DTM с восемью последовательными слоями достигает качества генерации FID 28.5 (чем ниже показатель Fréchet Inception Distance, тем реалистичнее изображения). Каждый слой использует машину Больцмана с сеткой 70×70 узлов, где каждый узел соединён с 12 соседями по паттерну G12 — это означает связи с ближайшими соседями и несколько дальних связей для захвата более сложных зависимостей.
Энергопотребление для генерации одного изображения составляет примерно 1.6 триллиона наноджоулей, что на четыре порядка меньше, чем у наиболее эффективного решения на графических процессорах.
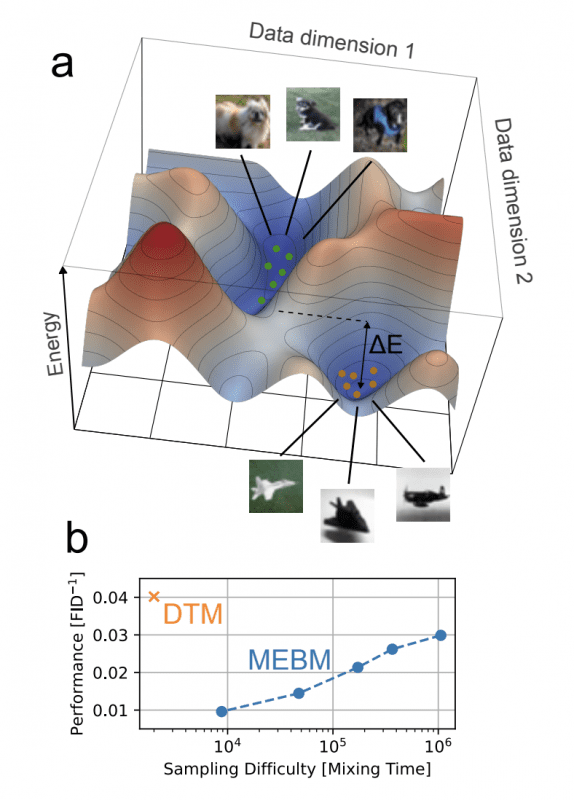
Для стабилизации обучения применяется адаптивный штраф за корреляцию (Adaptive Correlation Penalty, ACP) — механизм, который динамически регулирует сложность модели на основе того, насколько быстро алгоритм генерации перемещается по энергетическому ландшафту. ACP отслеживает автокорреляцию — степень похожести последовательных сэмплов: если алгоритм застревает и генерирует похожие варианты, автокорреляция высока. Механизм поддерживает автокорреляцию ниже заданного порога (например, 0.03), автоматически находя баланс между выразительностью модели и скоростью генерации.
Физическая модель показывает, что на чипе размером 6×6 миллиметров может разместиться около миллиона вычислительных ячеек, что значительно превышает требования экспериментальных моделей (крупнейшая DTM использовала примерно 50 тысяч ячеек). Дальнейшее масштабирование вероятностных вычислений предполагается через гибридные термодинамико-детерминированные архитектуры: небольшая классическая нейронная сеть преобразует цветные изображения в бинарное представление, совместимое с DTM, после чего вероятностный компьютер выполняет основную работу по генерации.
Эксперименты на наборе данных CIFAR-10 показали, что для достижения того же качества классическая часть гибридной модели может быть в 10 раз меньше, чем генератор в традиционной генеративно-состязательной сети (GAN).








Почему не до 100500 раз, очень странно.