EzAudio — новая диффузная модель генерации аудио на основе текста (T2A), разработанная исследователями из Tencent AI Lab и Университета Джонса Хопкинса. В основе модели — архитектура диффузионного трансформера для обработки латентных представлений аудиоданных. По результатам тестирования EzAudio превосходит текущие open-source модели как по объективным метрикам, так и по субъективной оценке. Модель может использоваться для реальных задач генерации музыки и звуковых эффектов. Демо модели и API доступно на Hugging Face.
Примеры работы EzAudio
«Двигатель автомобиля ревёт, затем ускоряется с высокой скоростью, металлическая поверхность скрипит, затем следуют визжащие шины»:
«Лошадь цокает копытами под дождём и ветром, гром гремит вдалеке»:
«Пианино играет на фоне ударов пластика»:
Архитектура модели
Исследователи решали проблемы повышения качества синтезированного аудио, снижения вычислительных затрат, оптимизации процесса семплирования и подготовки данных для обучения. Они характерны для всех T2A моделей.
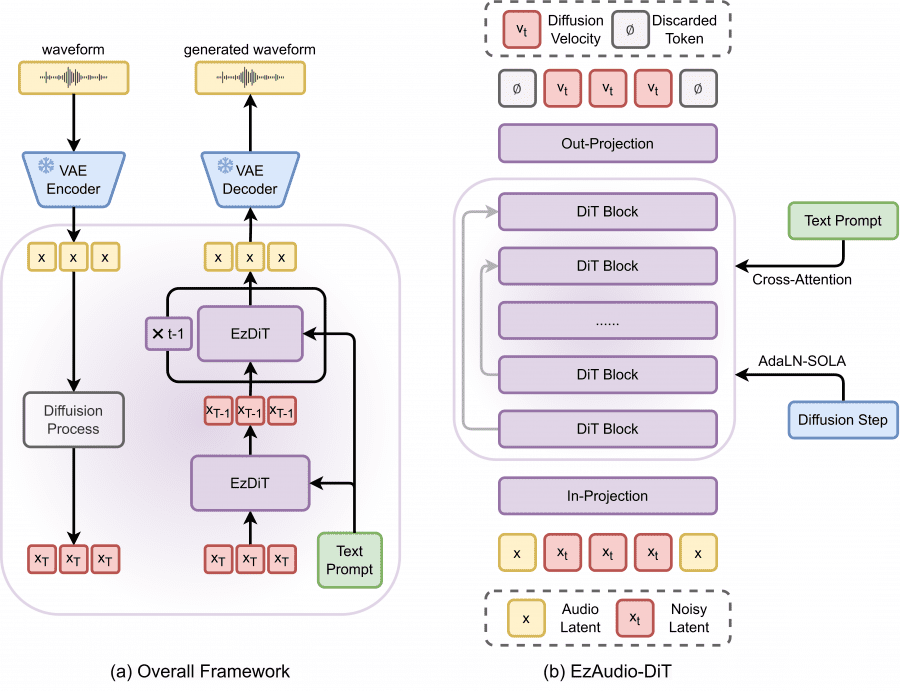
1D VAE на основе волновой формы
EzAudio использует вариационный автокодировщик (VAE) на основе 1D волновой формы, вместо традиционных 2D спектрограмм. Подход минимизирует сложность обработки двухмерных данных и исключает необходимость в дополнительных вокодерах. Вариационный автокодировщик сжатия звуковых данных обеспечивает высокую степень генеративной эффективности при меньших вычислительных затратах.
Диффузионный трансформер для генерации латентных представлений аудио
В основе модели лежит специализированная архитектура диффузионного трансформера для обработки латентных представлений аудиоданных. Модифицированная техника адаптивной нормализации слоя AdaLN-SOLA снижает количество параметров модели, сохраняя её производительность. Длинные скип-соединения сохраняют детализированную информацию на всех этапах генерации. Методы стабилизации обучения и улучшения сходимости трансформеров RoPE и QK-Norm ускоряют процесс обучения и повышают точность генерации.
Многослойная стратегия обучения
Трёхэтапный подход к обучению нацелен на эффективное использование данных:
- Маскированное моделирование на неразмеченных данных для изучения акустических зависимостей.
- Выравнивание текста с аудио с помощью синтетических данных.
- Тонкая настройка на размеченных человеком данных для повышения точности генерации.
Модель также использует метод пересчёта без классификатора (CFG) для улучшения выравнивания с запросами, сохраняя высокое качество аудиовыхода даже при увеличении значений CFG.
Результаты и метрики
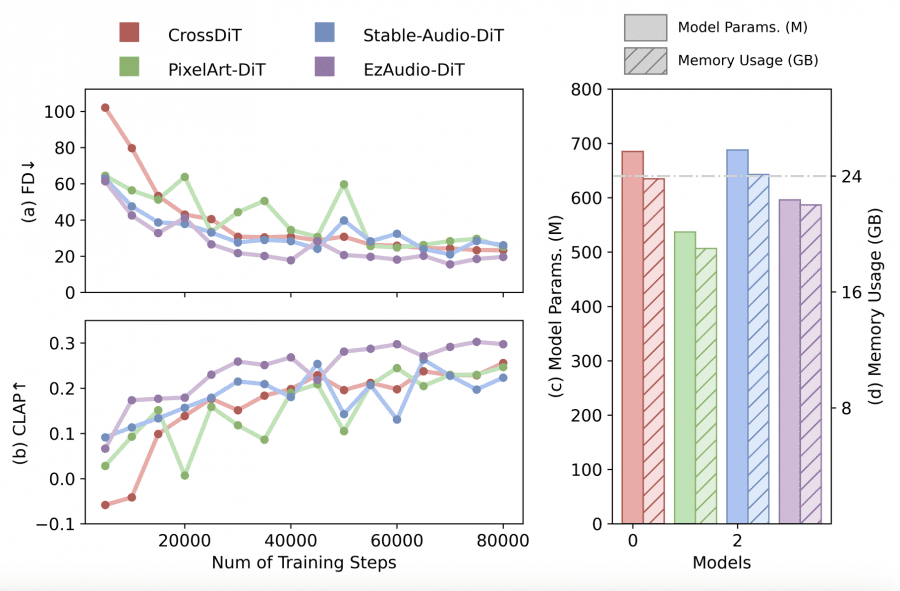
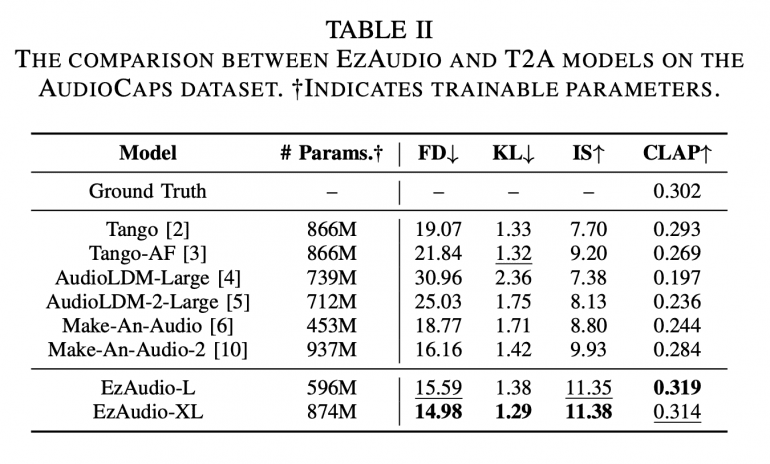
EzAudio-XL достигает Frechet Distance (FD) 14.98 и CLAP score 0.314, что превосходит результаты существующих open-source моделей.
По субъективной оценке, качество аудио, сгенерированного EzAudio-XL, сопоставимо с реальными записями.
«EzAudio создаёт высокореалистичные аудиопримеры, превосходя существующие open-source модели как по объективным, так и по субъективным метрикам,» — отмечают исследователи в своей работе.
Заключение
Развитие диффузионных моделей на основе латентных представлений позволило достигнуть значительных успехов в области генерации аудиоконтента. EzAudio предлагает более эффективное и высококачественное решение для задач генерации аудио на основе текста, что открывает широкие перспективы для применения в различных отраслях.