Исследователи из Facebook AI опубликовали нейросеть, которая генерирует аудиозаписи с голосами публичных личностей. Примеры сгенерированных аудиозаписей находятся по ссылке.
Представление аудиосигнала
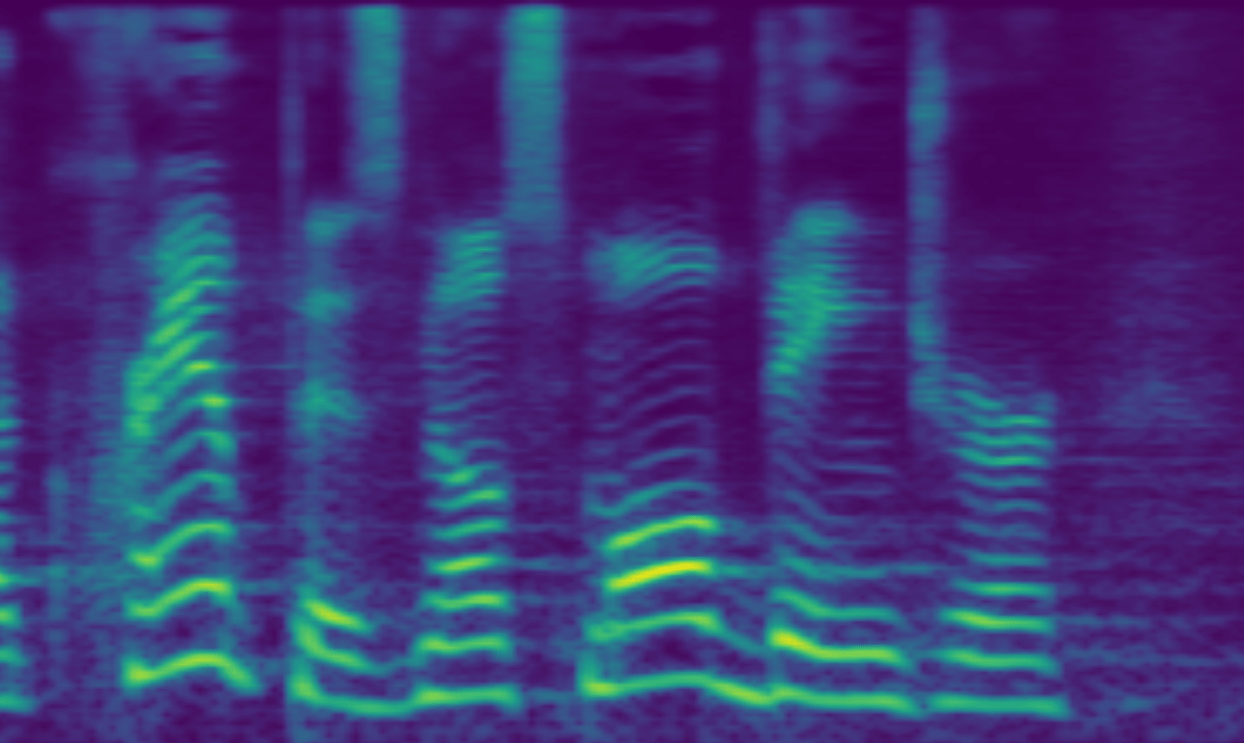
Сигнал имеет эквивалентные представления: в зависимости от изменений во времени и от изменений в частотности. Это применимо к аудиоволнам. В ранних исследованиях аудиосигналы представляли в соответствии с изменениями во времени. В MelNet для генерации аудиосигналов используется комбинация обоих подходов — time-frequency спектограммы. Спектограмма — это визуальное представление аудиосигналов в 2D, которое отражает изменения частотности в зависимости от времени.
Что внутри MelNet
Чтобы генерировать аудиволны, MelNet использует авторегрессивное моделирование. Авторегрессивные модели учатся моделировать комплексные распределения на основе моделирования последовательности более простых распределений. Так, модель предсказывает один элемент за другим. Схоже с PixelCNN, MelNet моделирует спектограммы поэлементно для временного и частотного измерений. В качестве модели исследователи используют Multidimensional RNN и one-dimensional RNN.
Исследователи экспериментируют с двумя вариациями модели:
- моделирование спектограммы по временным фреймам;
- моделирование спектограммы от глобальной структуры к локальной
Недостатком авторегрессивных моделей является ограниченная возможность восстанавливать глобальную структуру распределения. С этой целью исследователи обучают модель сначала генерировать общую структуру, а потом применяют повышение размерности, чтобы на основе глобальной структуры смоделировать локальную.

Эксперименты по обучению модели
Исследователи обучили MelNet генерировать аудиозапись без каких-либо условий на трех датасетах:
- Музыка: датасет с записями игры на пианино на музыкальном соревновании. Данные были записаны за несколько лет, что повлияло на изменения в качестве звука из года в год;
- Речь одного человека: датасет с записями аудиокниг;
- Речь нескольких людей: датасет с записями разговоров нескольких людей. В выборке спикеры 145 национальностей, с разными акцентами, разных возрастных категорий
Исследователи проверили MelNet на прикладной задаче генерации из текста в речь. Для этого MelNet была обучена на двух датасетах:
- Речь одного человека: переиспользуется датасет с записями аудиокниг, но к данным добавляются транскрипты аудиозаписей;
- Речь нескольких людей: датасет с записями от двух тысяч спикеров (примерно по 10 минут на запись)