Исследователи из Пекинского университета представили FLM-101B — открытую большую языковую модель с 101 миллиардом параметров, обученную с нуля на 300 миллиардах токенов при затратах «всего лишь» $100 000. Обучение таких масштабных языковых требует огромных вычислительных ресурсов, что делает их использование недоступным для большинства исследователей. FLM-101B демонстрирует возможность снижения затрат на обучение благодаря новой стратегии роста (growth strategy). Код модели доступен на HuggingFace.
FLM-101B обучалась на кластере из 24 DGX-A800 GPU (8×80G). Для обеспечения стабильности обучения на масштабе 100B, авторы использовали методы предсказания потерь на разных масштабах, смешанной точности (mixed precision) с bfloat16 и развили идеи своей предыдущей работы FreeLM.
Архитектура и обучение FLM-101B
FLM-101B основана на архитектуре только-декодер GPT, которая продемонстрировала высокую производительность на языковых задачах. В нее внесены две ключевые модификации: цели FreeLM и экстраполируемые позиционные вложения (xPos) для более эффективного моделирования длинных последовательностей.
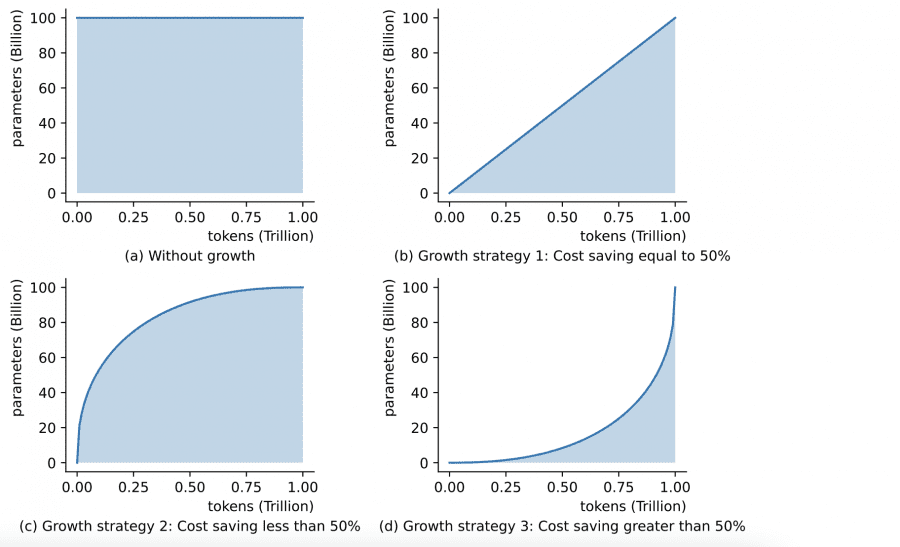
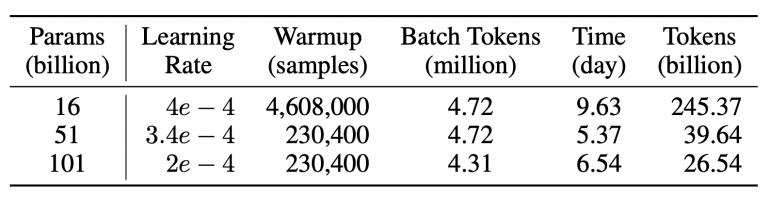
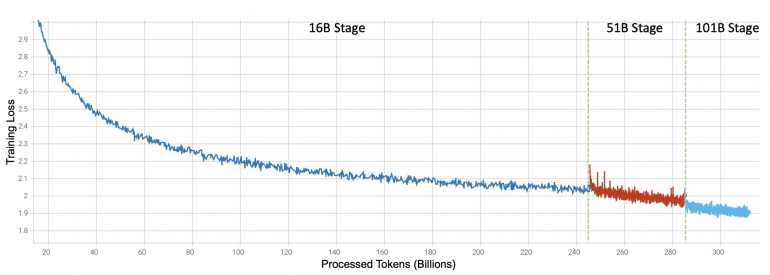
Размер скрытого состояния — 10 240, количество слоев — 80, окно контекста — 2 048, количество голов внимания — 80. Использовался оптимизатор AdamW с линейным уменьшением скорости обучения, весовым усилением, обрезкой градиента и другими оптимизированными настройками. Следуя стратегии роста, FLM-101B обучалась последовательно на 16B, 51B и 101B параметрах. Обучение модели при новом подходе заняло 21 день, что на 72% быстрее по сравнению с обучением модели 101B с нуля (76 дней).
Каждый размер наследует знания от предыдущего. Модель была предварительно обучена на корпусах текстовых данных на английском (53,5%) и китайском (46,5%) языках.
Подробнее о методе
Несколько ключевых методов, которыми исследователи решали задачу снижения вычислительных затрат при обучении больших языковых моделей, таких как FLM-101B:
- Стратегия роста (growth strategy). Подход, при котором обучение начинается с небольшой модели, и количество параметров растет последовательно, существенно снижает затраты на обучение. Так авторы смогли избежать обучения модели на 100B с нуля.
- Эффективный параллелизм (efficient parallelism). Авторы используют комбинацию стратегий параллелизма данных, тензоров и моделей в потоке для максимизации производительности на своем многоядерном кластере с графическими процессорами. Это обеспечивает эффективное масштабирование.
- Смешанная точность (mixed precision). Обучение со смешанной точностью с использованием bfloat16 уменьшает использование памяти и время обучения по сравнению с float32. Это дополнительно улучшает эффективность.
- Предсказание потерь (loss prediction). Предсказывая потери обучения на разных масштабах, авторы находят оптимальные гиперпараметры. Это экономит затраты на пробные запуски.
- Последовательная активация (checkpoint activation). Активация только частей модели во время обучения снижает затраты на активацию. Авторы используют это для оценки вычислительных затрат базовых моделей.
Эти методы имеют потенциал использованы для при обучении моделей для решения самых разнообразных задач глубокого обучения.
Результаты FLM-101B
Несмотря на низкие затраты на обучение, FLM-101B достигает конкурентоспособных результатов по сравнению с GPT-3, LLAMA 2 и GLM-130B на популярных бенчмарках:
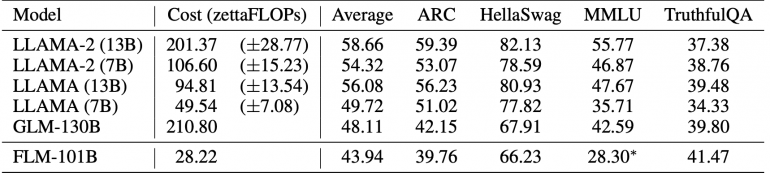
На вопросно-ответном бенчмарке TruthfulQA от OpenAI FLM-101B достигает лучшей точности 41,47% среди базовых моделей, превосходя GLM-130B на 2 пункта. Для ARC и HellaSwag, которые проверяют логику, FLM-101B сравним с GLM-130B, несмотря на использование гораздо меньшего объема данных. Авторы ожидают улучшения показателя с добавлением большего объема данных. На бенчмарках профессиональных знаний, таких как SuperGLUE и MMLU, FLM-101B уступает моделям, обученным на специфичных для этой области данных.