GigaGAN — open source модель с 1 миллиардом параметров, которая генерирует изображения размером 512×512 пикселей за 0,13 секунды, что на порядки быстрее, чем диффузные и авторегрессионные модели. Кроме того, исследователи обучили быстрый апсемплер (модель повышения разрешения), который создает изображения 4K на основе выводов text-to-image моделей низкого разрешения. GigaGAN достигает более низкого значения метрики FID (чем меньше, тем лучше) по сравнению с моделями Stable Diffusion v1.5 и DALL·E 2.
Успех диффузных моделей предопределил резкое изменение предпочитаемой архитектуры генеративных моделей для создания изображений. Раньше GAN-ы с техниками вроде StyleGAN были стандартным выбором. Однако с появлением DALL·E 2 авторегрессионные и диффузионные модели в одночасье стали новым стандартом. Этот быстрый сдвиг вызывает фундаментальный вопрос: можно ли масштабировать GAN-ы, чтобы они могли обучаться на больших датасетах, подобных LAION?
Исследователи института Карнеги-Меллон и Adobe Research обнаружили, что простое масштабирование архитектуры StyleGAN быстро приводит к нестабильности. Они спроектировали GigaGAN — новую архитектуру GAN, которая показывает, что GAN-ы могут быть жизнеспособным вариантом для задачи создания изображений из текста.
Три основных преимущества GigaGAN:
- Он на порядки быстрее диффузных моделей, ему требуется всего 0,13 секунды для синтеза изображения размером 512 пикселей;
- Модель быстро генерирует Hi-Res изображения, например, размером 16 мегапикселей за 3,66 секунды;
- Наконец, GigaGAN поддерживает методы редактирования латентного пространства, такие как латентная интерполяция, смешивание стилей и операции с векторами.
Архитектура GigaGAN
Генератор
Генератор GigaGAN включает в себя сеть текстового кодирования, сеть карты стилей, мульти-масштабную сеть синтеза, а также механизм внимания и адаптивный выбор ядра свертки:
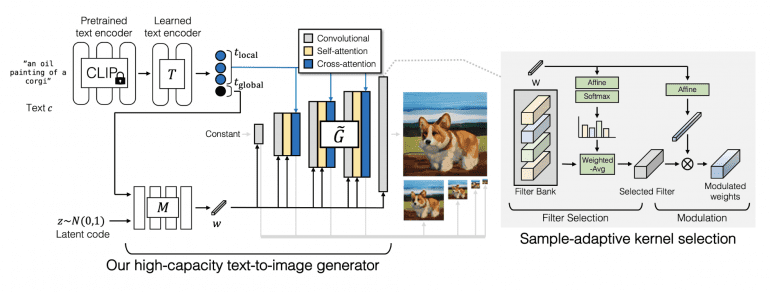
В сети текстового кодирования они сначала извлекают текстовые вложения, используя предварительно обученную модель CLIP и обученные слои внимания T. Затем вложение передается в сеть карты стилей M для создания вектора стиля w, аналогично модели StyleGAN. Далее синтезирующая сеть использует код в качестве модуляции и текстовые вложения в качестве внимания для создания пирамиды изображений. Адаптивный выбором ядра свертки позволяет адаптировать выбор ядер свертки в зависимости от поданного на вход текстового описания.
Дискриминатор
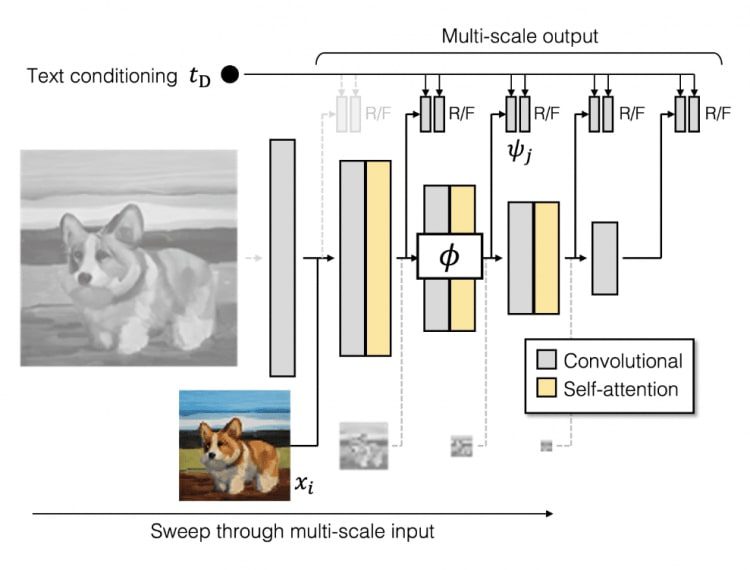
Дискриминатор GigaGAN, подобно генератору, состоит из двух сетей для обработки изображения и текстового описания. Ветвь текстового описания обрабатывает текст, аналогично генератору. Сеть обработки изображения получает пирамиду изображений и делает независимые прогнозы для каждой шкалы изображения. Более того, прогнозы делаются на всех последующих слоях понижения разрешения. Дополнительные функции потерь используются для обеспечения эффективной сходимости.
Результаты
Сравнение с недавними моделями текст-в-изображение показывает, что GigaGAN достигает более низкого значения FID, чем DALL·E 2, Stable Diffusion и Parti-750M, при этом значительно превосходя конкурентных методов в скорости.
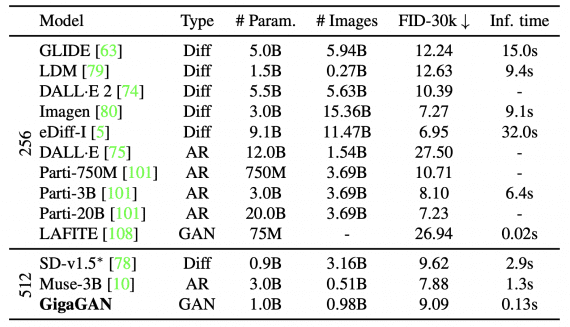
Отметим, что GigaGAN и SD-v1.5 требуют для обучения 4 783 и 6 250 GPU-дней A100, а Imagen и Parti нуждаются в приблизительно 4 755 и 320 днях работы с процессорами TPUv4.