
Исследователи из Cornell Tech и Adobe Research опубликовали нейросетевую модель, которая генерирует динамические сцены на основе видеозаписей. Модель принимает на вход видео, снятое с одного ракурса. На выходе модель отдает динамическую 3D модель сцены, в которой можно регулировать угол обзора и параметр времени. Модель обходит state-of-the-art архитектуры для генерации сцены из одноракурсного видео.
Архитектура модели
Neural Scene Flow Fields — это представление, которое моделирует динамическую сцену как непрерывную функцию внешнего вида, геометрии и движения 3D сцены. Представление оптимизируется с помощью нейросети. NSFF может использоваться для комплексный динамичных сцен.
Чтобы захватить динамику сцены, исследователи расширяют статичный подход через введение времени и прямое моделирование 3D движения. Для данных 3D точки и времени модель предсказывается не только коэффициент отражения и непрозрачности, но и последующий и предыдущий поток 3D сцены. Для этого в модели встроена специальная функция потерь. Подробнее функционал ошибки описан в оригинальной статье.
Тестирование подхода
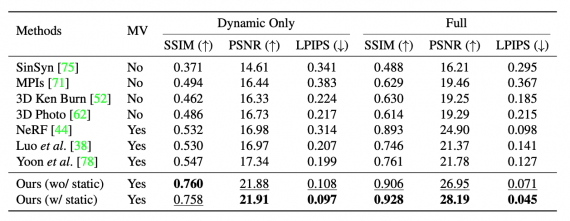
Подход сравнивали с state-of-the-art одноракурсными и многоракурсными методами для генерации сцен: MPI, SinSyn, 3D Photos, 3D Ken Burns, NeRF и другими. В качестве метрики исследователи использовали качество рендеринга (SSIM, PSNR и LPIPS). Ниже видно, что предложенный подход справляется с задачей лучше, чем альтернативные модели.

без кода это всё не более чем фейк