
Исследователи из Adept представили open source языковую модель Persimmon-8B c длиной контекста 16k токенов, что в 4 раза больше самой компактной Llama 2 и text-davinci-002, используемой в GPT-3.5. Длинный контекст позволяет отправлять на вход модели более длинные промпты и, соответсвенно, решать более сложные и разнообразные задачи. Persimmon-8B требует в 3 раза меньше данных для обучения по сравнению с Llama2 и работает на одном GPU Nvidia A100. Модель распространяется под открытой лицензий Apache, которая позволяет копировать, изменять и использовать исходный код модели и использовать ее в коммерческих целях. Исходный код моделей -сhat и -base доступен на Github.
Архитектура и обучение модели
Persimmon-8B представляет собой стандартный декодер-трансформер с модификациями в архитектуре. Использование ква ReLU в качестве функции активации часто приводит к тому, что выходные активации состоят на 90% из нулей. Это открывает интересные возможности для оптимизации. Также исследователи предпочли Вращательное позиционное кодирование (rotary positional encoding) библиотеке Alibi и добавили layer нормализацию в эмбеддинги Q (запрос) и K (ключ) перед их задействованием в механизме внимания.
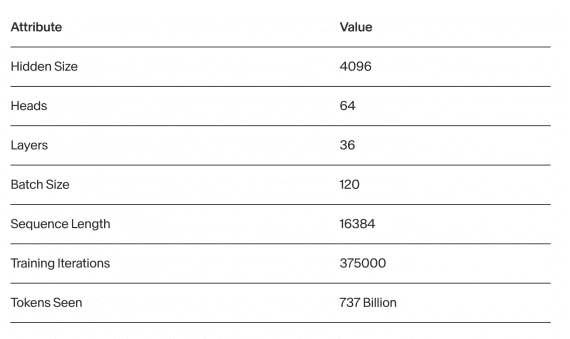
Модель обучалась на последовательности длиной 16k токенов на корпусе данных, содержащем 737 миллиардов токенов и состоящем на ~75% из текста и ~25% из кода. Обычно для обучения моделей используются контексты не длиннее 4k токенов с последующим расширением контекста. Обучение на такой длинной последовательности на протяжении всего обучения стало возможным благодаря разработке улучшенной версии FlashAttention и внесению изменений в базовые механизмы вращательных (rotary) вычислений.
Результаты Persimmon-8B
Исследователи сравнили модель Persimmon-8B с наиболее производительными моделями сравнимых размеров — LLama 2 и MPT 7B Instruct. Дообученная на инструкциях модель Persimmon-8B-FT оказалась самой производительной на бенчмарках MMLU, Winogrande, Arc Easy, Arc Challenge и HumanEval:
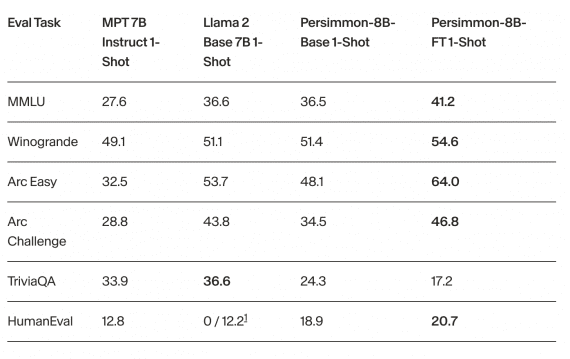
Базовая модель Persimmon-8B-Base продемонстрировала производительность сопоставимую с моделью Llama 2, хотя использовала в 3 раза меньше данных для обучения.








