QeRL — фреймворк для обучения языковых моделей методом обучения с подкреплением, который одновременно снижает требования к GPU и превосходит в точности традиционные методы LoRA и QLoRA. На модели Qwen2.5-7B-Instruct QeRL достигает 90.8% точности на математическом бенчмарке GSM8K против 88.1% у 16-битного LoRA и 85.0% у QLoRA, скорость при этом в 1.5-2 раза выше. Впервые стало возможным обучать 32-миллиардную модель с подкреплением на одном GPU H100, вместо 2-3 GPU, необходимых для стандартных подходов.
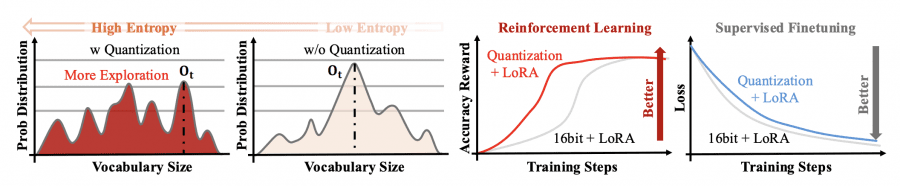
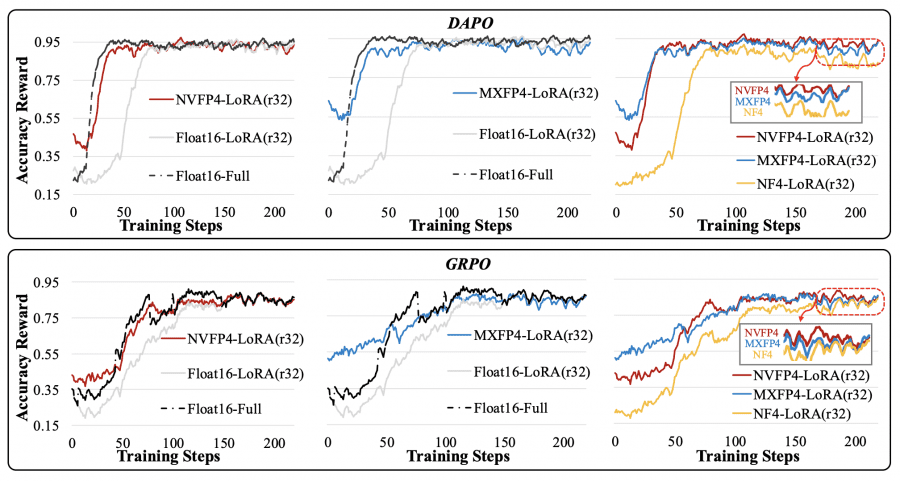
Шум квантизации, традиционно считающийся недостатком, в контексте RL улучшает способность модели находить более эффективные стратегии решения задач. Это объясняет, почему квантизованные модели показывают не только сопоставимую, но и превосходящую точность по сравнению с полноточными аналогами. QeRL комбинирует квантизацию NVFP4 с низкоранговой адаптацией LoRA, ускоряя критически важную фазу генерации выборок (rollout) и снижая потребление памяти на 50-60%.
Сравнение с LoRA и QLoRA
Фаза rollout (генерация выборок) — это этап обучения с подкреплением, когда модель создает множество вариантов ответов на каждый входной запрос. Например, модель получает математическую задачу и должна сгенерировать 8-16 различных решений длиной до нескольких тысяч токенов каждое. Именно эта фаза занимает большую часть времени обучения.
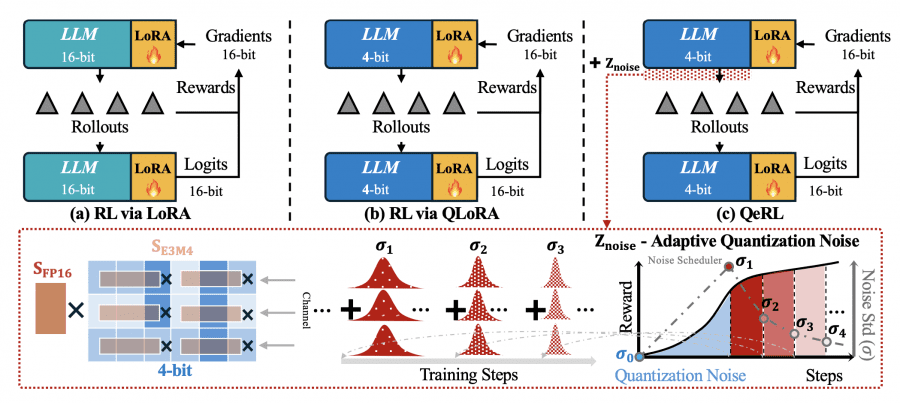
LoRA (Low-Rank Adaptation) снижает количество обучаемых параметров через декомпозицию W + ΔW = W + BA, где обновляются только низкоранговые матрицы A и B вместо полной матрицы весов. Это ускоряет этап обновления градиентов, но создает главную проблему — медленную генерацию выборок. Модель по-прежнему работает в 16-битной точности, требуя полного объема GPU-памяти для инференса.
QLoRA пытается решить проблему памяти, интегрируя LoRA с 4-битной квантизацией NF4. Однако подход создает новую проблему: NF4 требует распаковки значений через таблицу поиска перед каждым умножением матриц, что замедляет генерацию в 1.5–2 раза. Получается парадокс: экономия памяти достигается за счёт увеличения времени обучения.
Как QeRL превосходит предшественников
QeRL использует квантизацию NVFP4 — 4-битный формат с плавающей точкой со встроенной аппаратной поддержкой в архитектурах графических процессоров Hopper и Blackwell. В отличие от NF4, NVFP4 не требует медленной распаковки через таблицу поиска. Формат использует коэффициент масштабирования FP8 (E4M3) с блоками по 16 элементов, что обеспечивает детализированное масштабирование при сохранении скорости вычислений.
Интеграция с Marlin kernel ускоряет перемножение матриц для квантизованных весов. Во время генерации выборок модель работает полностью в 4-битной точности, снижая использование памяти в 2-3 раза. Обратное распространение градиентов происходит через LoRA адаптеры в 16-битной точности, сохраняя стабильность обучения.
Важное открытие исследователей: шум квантизации, который традиционно считается недостатком, в контексте RL становится преимуществом. Квантизованная модель вносит небольшие систематические ошибки во время прямого прохода, которые увеличивают энтропию вероятностного распределения над токенами. Вместо концентрации вероятности на одном «оптимальном» токене, модель рассматривает более широкий спектр вариантов, что улучшает exploration — поиск лучших стратегий решения задач.
Для оптимизации exploration QeRL вводит Adaptive Quantization Noise (AQN) — механизм динамической регулировки уровня шума во время обучения. На ранних этапах высокий уровень шума стимулирует широкое изучение пространства решений. По мере обучения шум постепенно снижается по экспоненциальному графику: σ(k) = σ_start · (σ_end/σ_start)^((k-1)/(K-1)), что позволяет модели сфокусироваться на эксплуатации найденных стратегий.
Технически шум интегрируется в параметры RMSNorm без дополнительных параметров: w_noise = Z_noise + w, где Z_noise — случайный вектор, сэмплируемый на каждом прямым проходом. Channel-wise аддитивный шум трансформируется в row-wise мультипликативный шум весовой матрицы, избегая нарушения совместимости с NVFP4 × BF16 операциями.
Экспериментальные результаты
Эксперименты на математических датасетах GSM8K и BigMath демонстрируют значительное преимущество QeRL. На модели Qwen2.5-7B-Instruct при обучении с GRPO на GSM8K:
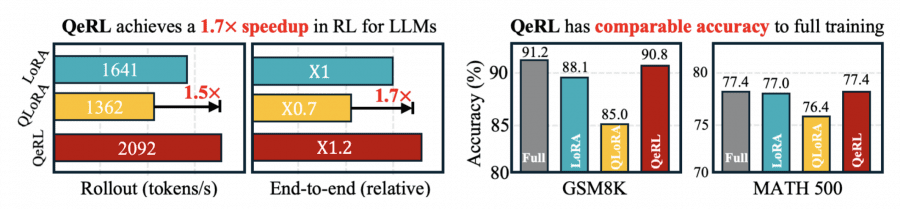
LoRA (16-bit): точность 88.1%
QLoRA (NF4): точность 85.0%
QeRL (NVFP4): точность 90.8%
QeRL превосходит LoRA на 2.7 пункта и QLoRA на 5.8 пункта. Более того, QeRL достигает результата, сопоставимого с full-parameter fine-tuning (91.2%), обучая при этом только 1% параметров.
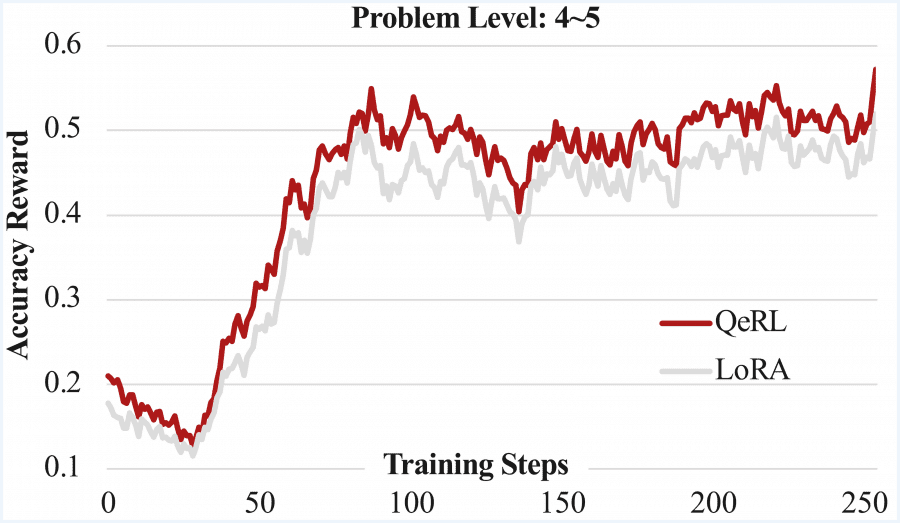
На более сложном датасете BigMath с уровнями сложности 3-5 для модели 7B QeRL улучшает средний score с 25.7 (базовая квантизованная модель) до 36.4, превосходя 35.7 у vanilla LoRA. Для модели 14B на датасете AMC 23 QeRL достигает 57.5, превосходя даже full-parameter training (55.0).
По скорости генерации выборок QeRL демонстрирует существенное ускорение. Для модели 7B при размере батча 8 пропускная способность составляет 2091.8 токенов/с против 1641.1 у LoRA — ускорение в 1.3 раза. QLoRA показывает лишь 0.7 от скорости LoRA из-за медленной распаковки NF4. End-to-end ускорение обучения — 1.1-1.2× для модели 7B и 1.3-1.4× для модели 14B.
Для модели 32B разница еще более драматична: QeRL достигает 2× ускорения генерации выборок. Критично то, что QeRL позволяет обучать 32B модель на одном H100 80GB GPU, в то время как ванильная LoRA требует 2-3 GPU из-за ограничений памяти.
Практическая ценность
Типичное RL обучение модели рассуждения занимает 20-100 часов на 8× H100 GPU. QeRL сокращает это время до 60-80 часов, экономя 1-2 дня на эксперимент. При стоимости H100 в облаке $2-4 за GPU-час, экономия составляет около $1,000 на один эксперимент или $10,000-$50,000 на полный исследовательский проект с множественными итерациями.
Главное преимущество — снижение порога при обучении больших моделей. 32B модель теперь может обучаться на одном GPU вместо 2-3 GPU, что снижает порог входа для небольших исследовательских групп и стартапов. QeRL использует только 40-50% GPU-памяти ванильной LoRA, открывая возможности для экспериментов на более доступном оборудовании.
Фреймворк выпущен под открытой лицензией на GitHub. Методология применима не только к математическим задачам, но и к другим доменам, требующим многошагового рассуждения — программированию, научным рассуждениям, планированию действий.






