По всему миру разработчики используют сверточные нейронные сети для переноса стилистики одного изображения на другое или просто модификации изображения. Когда существующие методы достигли высокой скорости обработки, исследователей и разработчиков заинтересовало преобразование видео. Тем не менее, модели стилизации картинок обычно плохо работают для видеороликов из-за высокой временной несогласованности (некогерентности): визуально это наблюдается как “мерцание” между последовательными преобразованными кадрами и несовпадение текстур и узоров движущихся объектов. Некоторым моделям удалось улучшить временную согласованность, но они не могут наряду с этим гарантировать высокую скорость обработки и хорошее качество восприятия.
Для решения этой сложной задачи недавно была представлен новый метод стилизации видео в режиме реального времени — ReCoNet. Авторы утверждают, что способ позволяет генерировать плавные ролики, сохраняя при этом благоприятную для восприятия картинку. Более того, по сравнению с другими существующими методами ReCoNet демонстрирует выдающуюся качественную и количественную производительность. Давайте узнаем, как авторам модели удалось достичь всего этого одновременно.
Предлагаемый подход
Группа исследователей из Университета Гонконга предложила real-time coherent video style transfer network (ReCoNet) в качестве современного подхода к стилизации видео. Это нейронная сеть прямого распространения, позволяющая выполнять обработку в режиме real-time. Видеофайл преобразовывается кадр за кадром через энкодер/декодер. Сеть потерь VGG отвечает за учет качества восприятия стиля.
Новизна их подхода заключается в введении штрафов за искажение яркости в временны́х потерях (temporal loss) выходного уровня. Он позволяет фиксировать изменения яркости прослеживаемых пикселей во входном видео и повышает стабильность стилизации в областях с эффектами освещения. В целом, это ограничение является ключевым в подавлении некогерентности. Однако также предлагается ввести временну́ю потерю на уровне объектов, которая штрафует за изменения высокоуровневых признаков одного и того же объекта в последовательных кадрах, тем самым повышая согласованность на прослеживаемых объектах.
Архитектура сети
Рассмотрим технические детали предлагаемого подхода и более внимательно изучим архитектуру сети (представлена на рисунке 2).
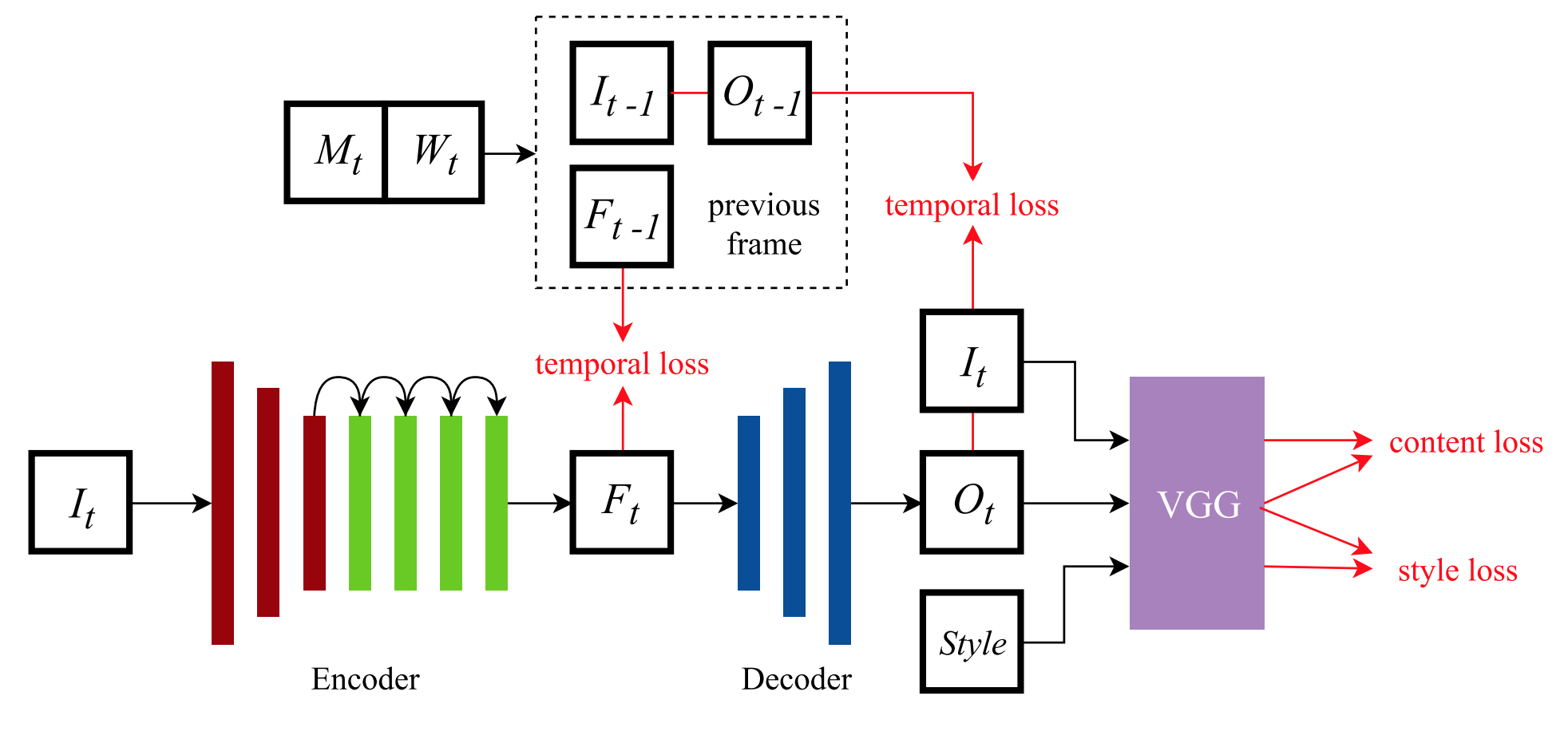
ReCoNet состоит из трех модулей:
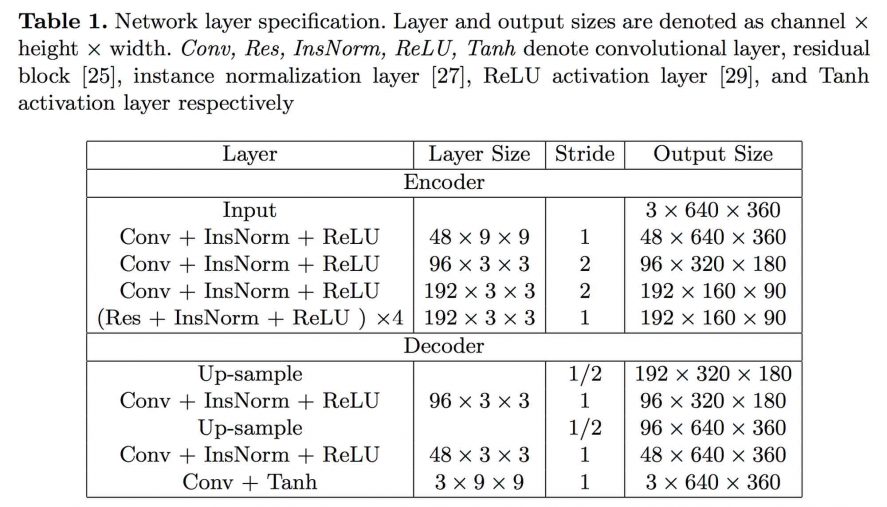
- Энкодер преобразует кадры входного изображения в карты признаков с извлеченной информацией о восприятии (perceptual information). Энкодер содержит три сверточных слоя и четыре остаточных блока (residual blocks).
- Декодер генерирует стилизованные изображения по картам признаков. Чтобы уменьшить артефакты вида “шахматная доска”, декодер включает в себя два сверточных слоя сэмплирования (up-sampling, он же unpooling) с последним сверточным слоем (вместо одного традиционного деконволюционного слоя).
- Сеть потерь VGG-16 вычисляет ошибки восприятия. Предварительно обучена на датасете ImageNet.
Кроме того, на выходах с энкодера и декодера вычисляется и суммируется многоуровневая временная ошибка для уменьшения некогерентности.
На этапе обучения применяется синергический механизм обучения, использующий два кадра (синергический эффект — возрастание эффективности деятельности в результате соединения, интеграции, слияния отдельных частей в единую систему за счет так называемого системного эффекта, прим.). Это означает, что для каждой итерации сеть в два прогона генерирует карты признаков и преобразованный вывод для двух последовательных кадров. Обратите внимание, что на этапе тестирования сетью обрабатывается только один кадр ролика за один проход. Тем не менее, в процессе обучения временные потери вычисляются с использованием карт признаков и стилизованного вывода обоих кадров, а потери восприятия вычисляются на каждом кадре независимо и суммируются. Конечная функция потерь для двухкадрового обучения:
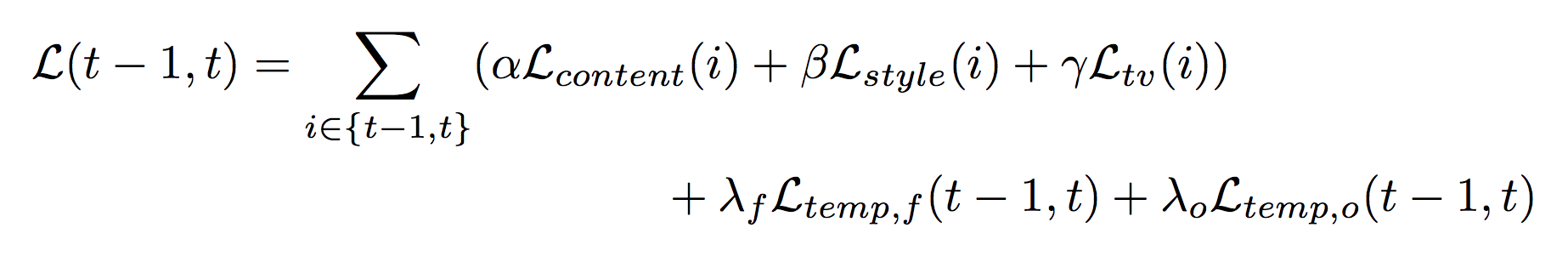
где α, ?, ?, ?? и ?? — это гиперпараметры при обучении.
Результаты, полученные с помощью ReCoNet
На рисунке 3 показано, как предлагаемый метод передает четыре разных стиля на трех последовательных видеокадрах. Как можно заметить, ReCoNet успешно воспроизводит цвет, штрихи и текстуры базового стиля и создает визуально согласованные видеокадры.


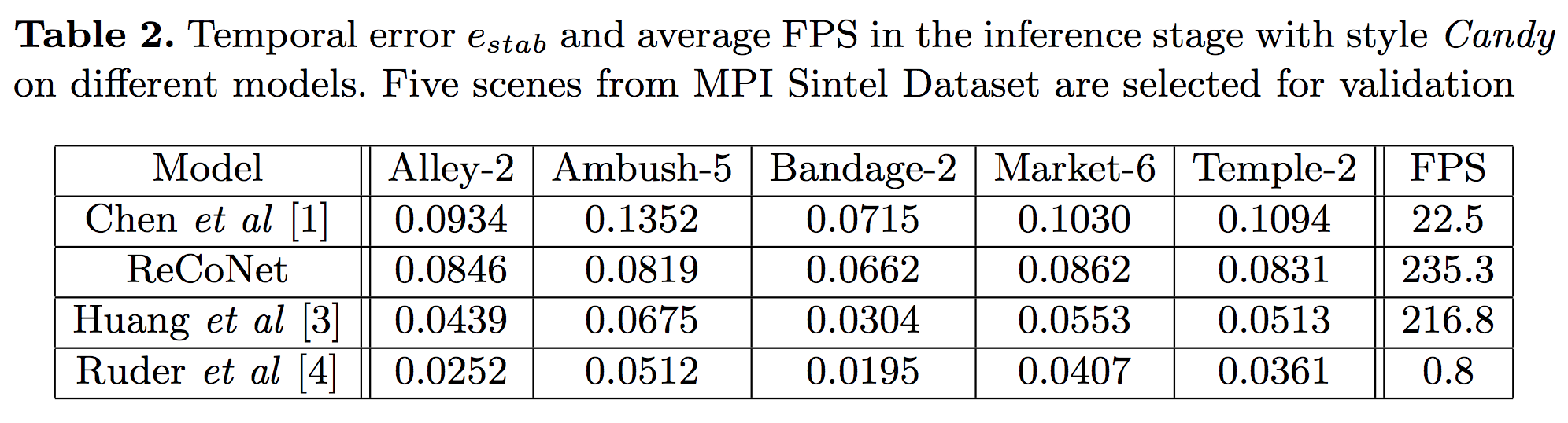
Затем исследователи провели количественное сравнение эффективности ReCoNet с тремя другими методами. В приведенной ниже таблице показаны временные ошибки четырех моделей преобразования видео в пяти разных сценах. Модель Ruder et al демонстрирует самые маленькие ошибки, но значения FPS не позволяют использовать ее в режиме real-time из-за малой скорости вывода. У модели Huang et al более низкие временные ошибки, чем у ReCoNet; но сможет ли эта модель захватить штрихи и мелкие текстуры аналогично ReCoNet? Обратимся к качественному анализу.
Как видно из верхней строки на рисунке 4, модель Huang et al плохо справляется с штрихами и узорами. Это может быть связано с тем, что она использует малое отношение веса между потерями восприятия и временными потерями для поддержания когерентности. Кроме того, модель использует карты признаков из более глубокого слоя relu4_2 в loss-сети для вычисления потери содержимого, что затрудняет обработку низкоуровневых признаков, таких как границы.

Нижняя строка на рисунке 4 показывает, что результаты работы Chen et al хорошо воспринимаются и по содержимому, и по стилю. Тем не менее, при увеличении некоторых областей можно обнаружить заметную некогерентность, что подтверждается более высокими временными ошибками.

Интересно, что авторы также сравнили модели, изучая отзывы пользователей. Для каждого из двух сравнений к 4 различным видеоклипам применялись 4 разных стиля. Для опроса были приглашены 50 человек, им предлагалось ответить на следующие вопросы:
- (Q1) Какая модель передает стиль лучше, особенно цвет, штрихи, текстуры и другие визуальные шаблоны?
- (Q2) Какая модель лучше согласована по времени (т. е. где меньше мерцающих артефактов и цвет и стиль одного и того же объекта более стабилен)?
- (Q3) Какая модель предпочтительнее в целом?
Результаты этого исследования, как показано в таблице 3, подтверждают выводы, сделанные из качественного анализа: ReCoNet достигает гораздо лучшей когерентности, чем модель Chen et al, сохраняя при этом одинаково хорошее восприятие стилей; модель Huang et al превосходит ReCoNet, когда дело доходит до временной согласованности, но визуально воспринимается результат гораздо хуже.
Итоги
Этот новый подход к переносу стиля на видео отлично подходит для создания согласованных стилизованных видеороликов в режиме обработки real-time, генерируя при этом действительно приятную для восприятия картинку. Авторы предложили использовать ограничение искажения яркости в временных потерях на уровне выходных данных и временную потерю уровня карты признаков для повышения стабильности при различных эффектах освещения, а также для лучшей временной согласованности. Когда речь заходит про когерентность, то ReCoNet оказывается среди новейших методов. Учитывая высокую скорость обработки и выдающиеся результаты в захвате информации о содержимом и стилистике, этот подход, безусловно, находится на “передовой” в стилистической обработке видео.
Перевод — Эдуард Поконечный