Команда исследователей ByteDance Seed совместно с Институтом AIR Университета Цинхуа представила Seed Diffusion Preview — языковую модель на основе дискретной диффузии, демонстрирующую рекордную скорость инференса. Модель достигает 2,146 токенов в секунду на графических процессорах H20, сохраняя при этом конкурентоспособную производительность на бенчмарках генерации кода. Seed Diffusion Preview — новый state-of-the-art на Парето-границе «скорость-качество» для моделей генерации кода. Модель можно потестировать в интерактивном демо.
Архитектура Seed Diffusion
В Seed Diffusion Preview применяется диффузия дискретных состояний вместо традиционного авторегрессивного декодирования токен-за-токеном. Эта архитектурная особенность позволяет модели генерировать токены параллельно, значительно ускоряя вывод по сравнению с традиционными авторегрессивными моделями.
Модель основывается на стандартной плотной архитектуре трансформера, оптимизированной для задач генерации кода. Исследователи сознательно исключили сложные компоненты логических рассуждений, сосредоточившись на создании эффективной базовой системы с максимальной скоростью вывода.
TSC: двухэтапный процесс обучения
Ключевая методологическая инновация — TSC (двухэтапная программа обучения), представляющая собой структурированный подход к обучению с двумя типами процессов аугментации данных в прямой диффузии.
Искажение на основе маскирования: На первых 80% шагов обучения применяется стандартная стратегия маскирования, постепенно заменяющая токены в наборе данных специальным токеном [MASK]. Процесс контролируется функцией зашумления, которая определяет, какую долю токенов нужно замаскировать на каждом этапе обучения. Эта функция задает распределение вероятностей для сохранения исходного токена или его замены на [MASK] в каждой позиции последовательности, постепенно увеличивая степень маскирования по мере продвижения процесса диффузии.
Аугментация на основе редактирования: На заключительных 20% шагов обучения добавляется искажение данных через имитацию реальных операций редактирования кода как дополнительная техника регуляризации. Вместо простого маскирования система применяет более естественные преобразования: удаляет части кода, вставляет новые фрагменты или заменяет существующие элементы. Интенсивность этих изменений контролируется через расстояние Левенштейна — метрику, измеряющую минимальное количество операций редактирования, необходимых для превращения исходного кода в измененную версию. Это позволяет модели научиться восстанавливать код после различных типов реальных правок, которые программисты выполняют в повседневной работе.
Финальная функция потерь объединяет два компонента обучения: ELBO (нижнюю границу правдоподобия) — математический критерий оценки качества восстановления замаскированных токенов, и функцию потерь шумоподавления — метрику успешности восстановления кода после операций редактирования. Такая комбинированная архитектура позволяет модели одновременно учиться справляться с простыми искажениями (пропущенные фрагменты) и сложными реалистичными изменениями (правки кода), что делает систему более устойчивой и универсальной при работе с различными типами неполных или искаженных входных данных.
Оптимизация траекторий и ограниченная выборка
Из множества возможных способов восстановления кода модель сначала генерирует большое количество вариантов (траекторий генерации), затем отбирает только самые эффективные на основе математического критерия ELBO. Эти лучшие стратегии генерации формируют набор данных для финального дообучения модели, что позволяет ей изучить оптимальные пути восстановления кода вместо случайных подходов.
Обучение с подкреплением для ускорения вывода
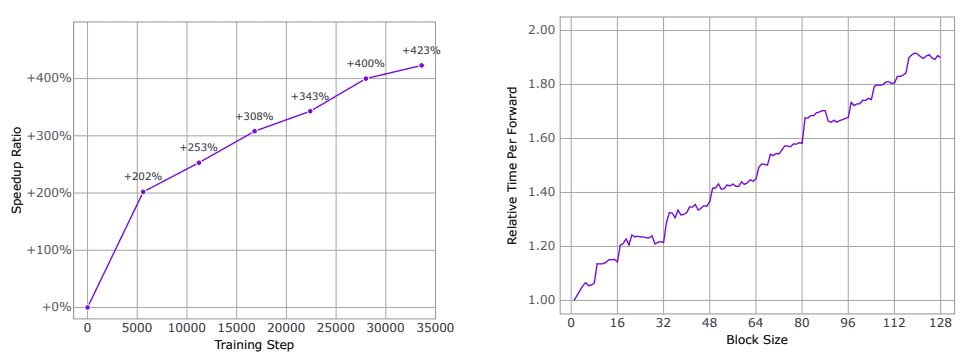
Для максимального использования возможностей параллельной обработки исследователи применяют метод обучения с подкреплением, направленный на сокращение количества шагов восстановления. Система учится генерировать код за минимальное число итераций через постепенную оптимизацию вспомогательной функции потерь. Результат впечатляющий: скорость вывода модели увеличивается более чем в 4 раза (400%+) по мере обучения, что подтверждается экспериментальными измерениями.
Блочный параллельный вывод
Для оптимального баланса между вычислительными затратами и задержкой применяется параллельная диффузионная выборка на уровне блоков с причинно-следственным упорядочиванием между блоками. Система использует кэширование ключ-значение для ранее сгенерированных блоков, обеспечивая эффективность вывода без существенного снижения качества в процессе генерации.
Результаты Seed Diffusion и сравнения с другими моделями
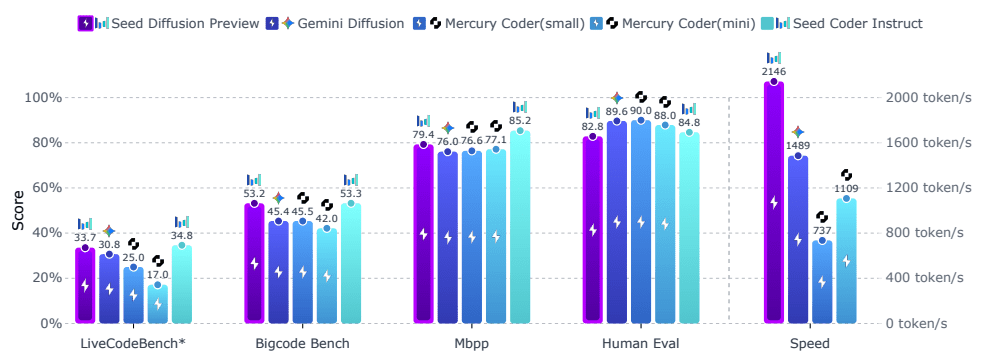
Seed Diffusion Preview демонстрирует конкурентоспособную производительность на комплексном наборе бенчмарков для оценки генерации кода.
Скорость вывода: 2,146 токенов в секунду на графических процессорах H20 — примерно в два раза быстрее Mercury Coder (1,109 т/с) и в полтора раза быстрее Gemini Diffusion (1,489 т/с).
Метрики производительности на бенчмарках:
- HumanEval: 84.8% точность
- MBPP: 88.0% точность
- BigCodeBench: 45.4% успешность
- LiveCodeBench: 33.7% доля прохождения
На специализированных задачах редактирования кода модель показывает особенно сильные результаты:
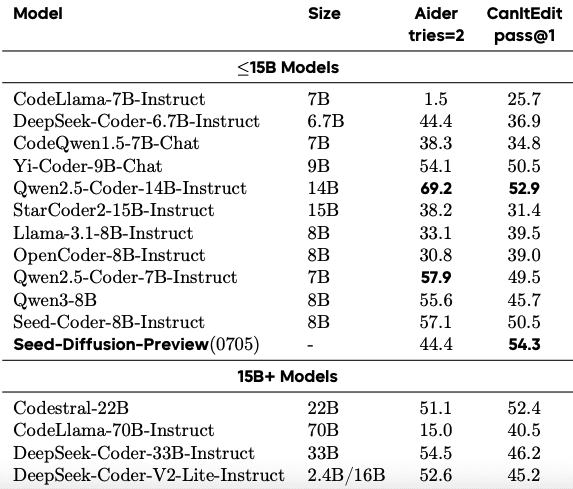
- Бенчмарк Aider: 44.4% успешность (настройка tries=2)
- CanItEdit: 54.3% метрика pass@1
В мультиязыковом бенчмарке MBXP Seed Diffusion Preview достигает среднего балла 72.6%, демонстрируя стабильную производительность по 13 языкам программирования от Python (79.4%) до Swift (54.2%).
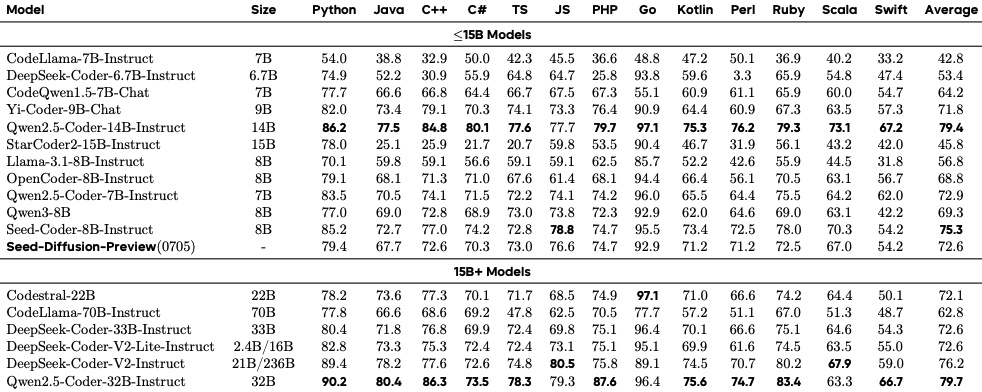
Исследование подтверждает практическую применимость дискретной диффузии для реальных приложений генерации кода. Метод обеспечивает оптимальный баланс скорости и качества, критически важный для развертывания в корпоративных средах.