Исследователи из Samsung AI и Сколково представили новую архитектуру нейросети для трекинга позы человека на видео. Метод обходит state-of-the-art подходы в случае видеосъемки с нескольких камер.
Оценка позы человека в 3D является актуальной проблемой компьютерного зрения. Такие модели находят применение в распознавании действий, в HCI, создании спецэффектов и т.п. Исследователи описывают две конфигурации нейросети: первая основывается на понятии алгебраической триангуляции, а вторая — на объемной триангуляции. Понятие триангуляции в компьютерном зрении отсылает к поиску точки в 3D пространстве с учетом проекции его проекцию на два и более изображений.
Описание подхода
Предполагается, что ведется синхронное видеонаблюдение за человеком с нескольких камер. Видео с этих камер преобразуются в проекционные матрицы. Целью модели является определить положение в трехмерном пространстве фиксированного количества точек на человеческом теле в момент t. Интересно, что модель не использует информацию о предыдущем положении точки на теле и на каждой отметке времени ищет положение точки заново.
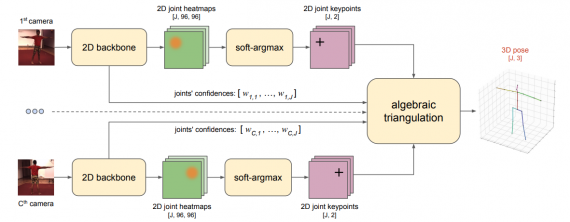
Модель на алгебраической триангуляции
Изображения каждой из камер сначала обрезаются так, чтобы на изображении остался только человек. Из обрезанные изображения получаются карты признаков. Внутри 2D backbone части архитектуры — ResNet-152. Затем получаются промежуточные тепловые карты, за которыми следует конволюционная сеть, которая трансформирует эти тепловые карты в интерпретируемые карты точек тела человека. Эти карты поступают с разных камер поступают в блок с алгебраической триангуляцией и выдают на выходе координаты позы человека.
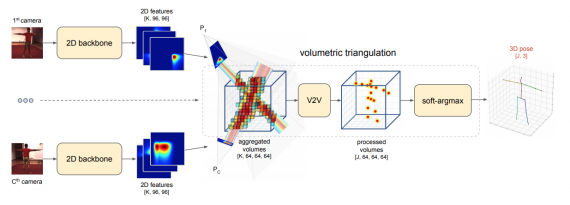
Модель на объемной триангуляции
В случае со второй конфигурация обрезанные изображения также попадают в ResNet и конволюционные слои. Затем генерируются 2D признаки изображений.Эти признаки агрегируются в точки с помощью объемное триангуляции.
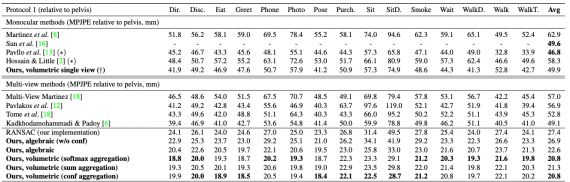
Результаты работы моделей
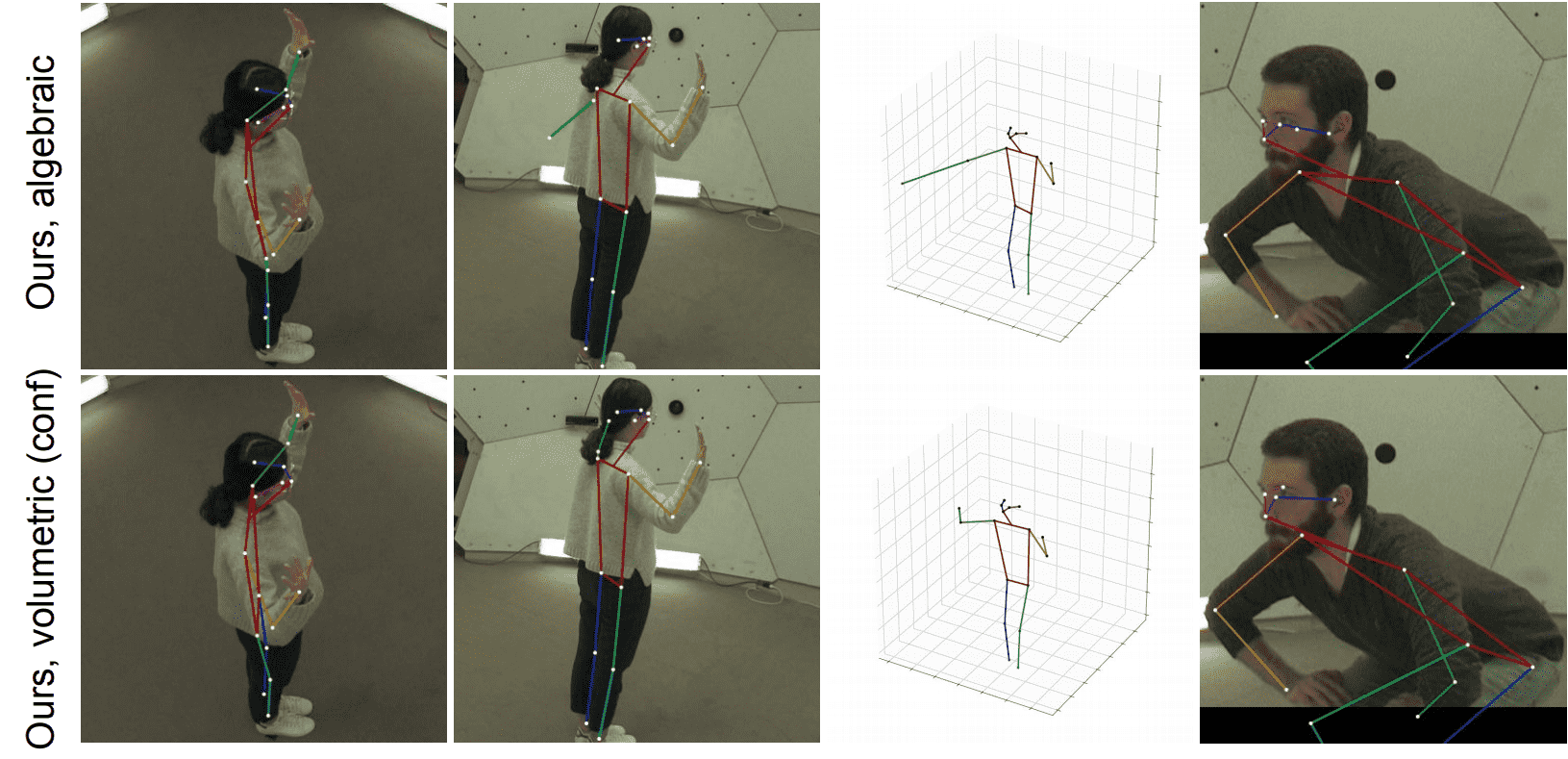
Исследователи проверяли разные конфигурации нейросети на датасете Human3.6M. В качестве метрики эффективности использовалась MPJPE. Видно, что модель на объемной триангуляции работает лучше, чем на алгебраической. В целом, на задаче с множеством камер нейросеть более эффективна.