Vision Outlooker (VOLO) — вариация архитектуры Vision Transformer, призванная снизить зависимость от дополнительных обучающих данных. Достигнут рекордный показатель 87,1% на ImageNet без предобучения. Код в открытом доступе.
Зачем это нужно
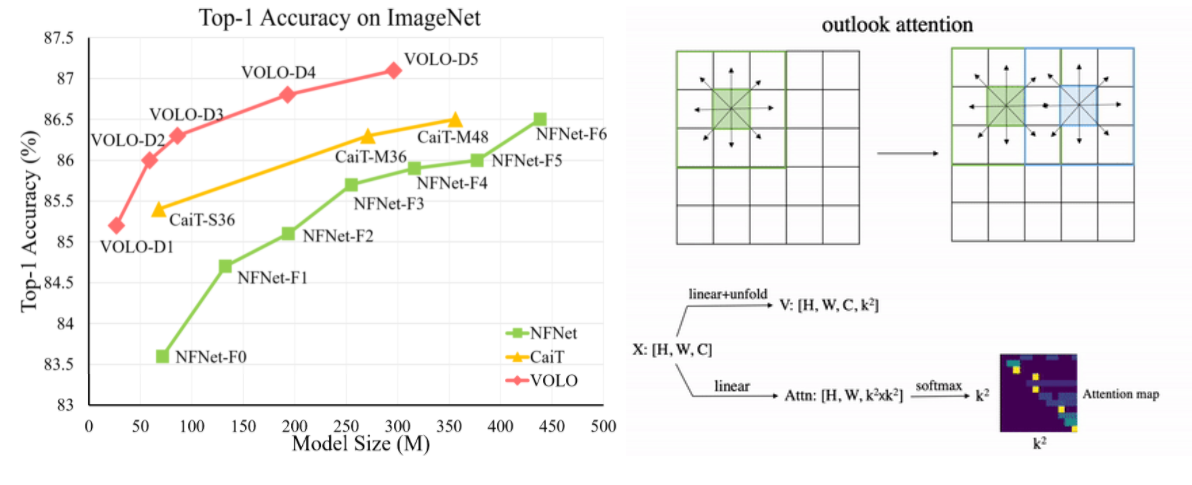
В течение многих лет в задаче классификации изображений доминировали свёрточные нейронные сети (CNN). С другой стороны, более новая архитектура Vision Transformer (ViT), основанная на механизме внимания (attention), показала более высокие результаты, опираясь на предобучение. Однако производительность трансформеров без дополнительных обучающих данных по-прежнему уступает современным свёрточным сетям. Авторы статьи стремятся сократить разрыв в производительности и продемонстрировать, что модели, основанные на внимании, способны превзойти CNN.
Как это работает
Авторы обнаружили, что ViT неэффективно кодирует высокоуровневые признаки объектов (fine-level features) в семантические токены на начальном этапе работы архитектуры. Этот фактор ограничивает производительность трансформеров на популярном датасете ImageNet. Архитектура Vision Outlooker (VOLO) создана для решения этой проблемы. Механизм «самовнимания» (self-attention) заменён механизмом «внешнего внимания» (outlook attention).
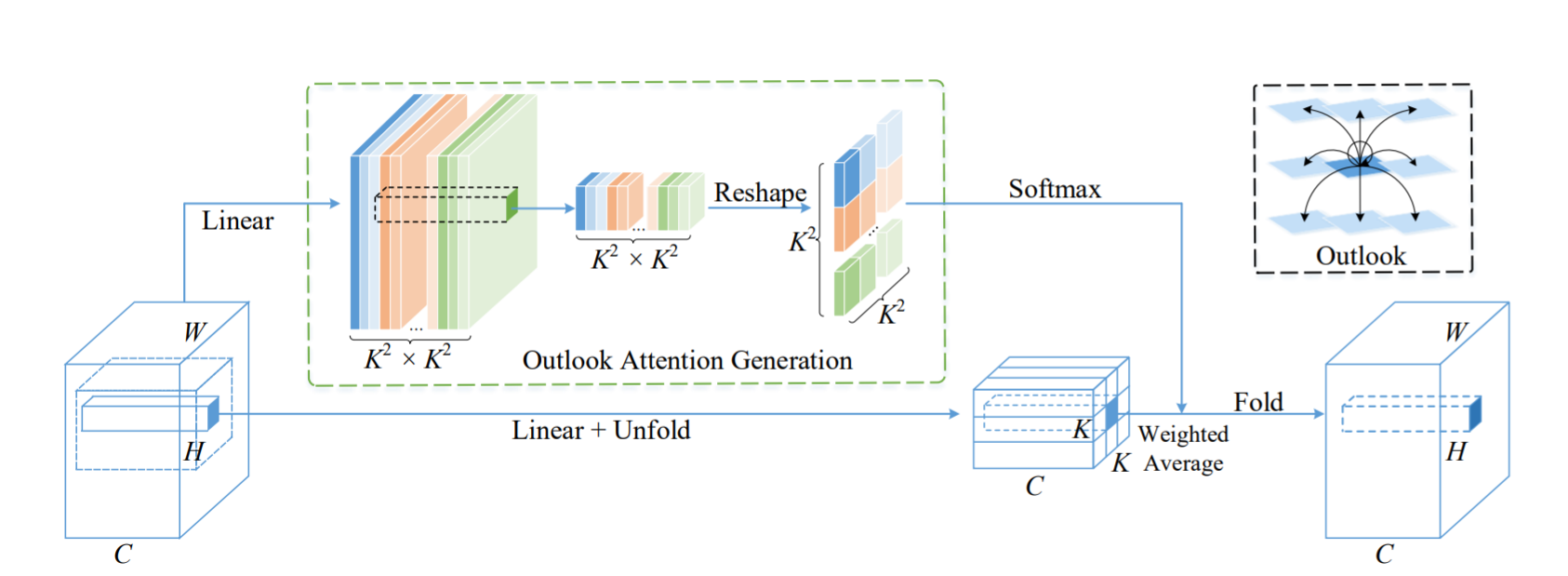
В отличие от self-attention, выполняющего поиск зависимостей в низкоуровневых признаках, outlook attention получает токены из признаков более высокого уровня. Основные преимущества предложенного механизма outlook attention:
- изучает пространство признаков эффективнее, чем свёртка.
- размечает высокоуровневые токены в пространстве, что сохраняет позиционную информацию на изображении.
- получает «карту внимания» с меньшими вычислительными затратами, чем self-attention, не используя скалярное произведение.
Архитектура VOLO работает в два этапа. Первый этап применяет к данным последовательность модулей Outlooker, включающих outlook attention. На втором этапе к сгенерированным токенам применяется последовательность трансформеров для обобщения содержимого изображения.
Результаты
VOLO достигает 87,1% по показателю top-1 accuracy в задаче классификации на ImageNet. Это первая модель, превысившая 87% точности без использования дополнительных данных для обучения. Кроме того, предварительно обученная модель VOLO переносится на другие задачи, такие как семантическая сегментация изображений. По показателю mIoU достигнуты 84,3% на датасете городских ландшафтов и 54,3% на датасете ADE20K.
Подробнее о VOLO читайте в статье на arXiv.
Код доступен в репозитории Github.









