Аналитики Gartner утверждают, что к 2020 году 85% взаимодействий клиентов с сервисами сведется к общению с чат-ботами. В 2018 году они уже обрабатывают около 30% операций. В этой статье мы расскажем, как создать своего чат-бота на Python.
Возможно, вы слышали о Duolingo: популярном приложении для изучения иностранных языков, в котором обучение проходит в форме игры. Duolingo популярен благодаря инновационному стилю обучения. Концепция проста: от пяти до десяти минут интерактивного обучения в день достаточно, чтобы выучить язык.
Несмотря на то что Duolingo позволяет изучить новый язык, у пользователей сервиса возникла проблема. Они почувствовали, что не развивают разговорные навыки, так как обучаются самостоятельно. Пользователи неохотно обучались в парах из-за смущения. Эта проблема не осталась незамеченной для разработчиков.
Команда сервиса решила проблему, создав чат-бота в приложении, чтобы помочь пользователям получать разговорные навыки и применять их на практике.
Поскольку боты разрабатывались так, чтобы быть разговорчивыми и дружелюбными, пользователи Duolingo практикуются в общении в удобное им время, выбирая «собеседника» из набора, пока не поборят смущение в достаточной степени, чтобы перейти к общению с другими пользователями. Это решило проблему пользователей и ускорило обучение через приложение.
Итак, что такое чат-бот?
Чат-бот — это программа, которая выясняет потребности пользователей, а затем помогает удовлетворить их (денежная транзакция, бронирование отелей, составление документов). Сегодня почти каждая компания имеет чат-бота для взаимодействия с пользователями. Некоторые способы использования чат-ботов:
- предоставление информации о рейсе;
- предоставление пользователям доступа к информации об их финансах;
- служба поддержки.
Возможности безграничны.
История чат-ботов восходит к 1966 году, когда Джозеф Вейценбаум разработал компьютерную программу ELIZA. Программа подражает манере речи психотерапевта и состоит лишь из 200 строк кода. Пообщаться с Элизой можно до сих пор на сайте.
Читайте также: Нейросети для написания текста на русском языке: подборка онлайн сервисов
Как работает чат-бот?
Существует два типа ботов: работающие по правилам и самообучающиеся.
- Бот первого типа отвечает на вопросы, основываясь на некоторых правилах, которым он обучен. Правила могут быть как простыми, так и очень сложными. Боты могут обрабатывать простые запросы, но не справлятся со сложными.
- Самообучающиеся боты создаются с использованием основанных на машинном обучении методов и определенно более эффективны, чем боты первого типа. Самообучающиеся боты бывают двух типов: поисковые и генеративные.
В поисковых ботах используются эвристические методы для выбора ответа из библиотеки предопределенных реплик. Такие чат-боты используют текст сообщения и контекст диалога для выбора ответа из предопределенного списка. Контекст включает в себя текущее положение в древе диалога, все предыдущие сообщения и сохраненные ранее переменные (например, имя пользователя). Эвристика для выбора ответа может быть спроектирована по-разному: от условной логики «или-или» до машинных классификаторов.
Генеративные боты могут самостоятельно создавать ответы и не всегда отвечают одним из предопределенных вариантов. Это делает их интеллектуальными, так как такие боты изучают каждое слово в запросе и генерируют ответ.
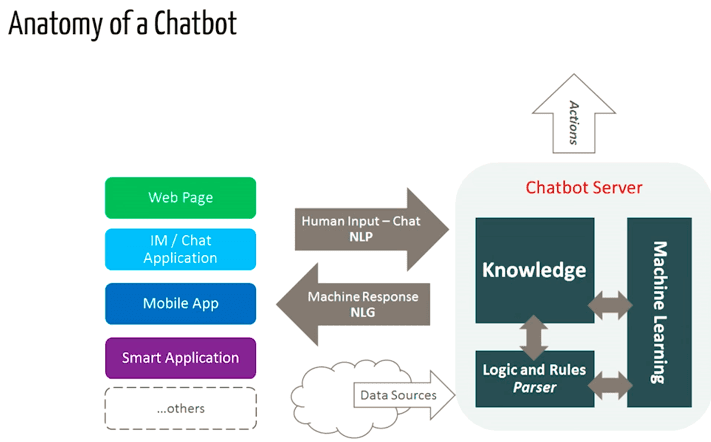
В этой статье мы научимся писать код простых поисковых чат-ботов на основе библиотеки NLTK.
Создание бота на Python
Предполагается, что вы умеете пользоваться библиотеками scikit и NLTK. Однако, если вы новичок в обработке естественного языка (NLP), вы все равно можете прочитать статью, а затем изучить соответствующую литературу.
Обработка естественного языка (NLP)
Обработка естественного языка — это область исследований, в которой изучается взаимодействие между человеческим языком и компьютером. NLP основана на синтезе компьютерных наук, искусственного интеллекта и вычислительной лингвистики. NLP — это способ для компьютеров анализировать, понимать и извлекать смысл из человеческого языка разумным и полезным образом.
Краткое введение в NLKT
NLTK (Natural Language Toolkit) — платформа для создания программ на Python для работы с естественной речью. NLKT предоставляет простые в использовании интерфейсы для более чем 50 корпораций и лингвистических ресурсов, таких как WordNet, а также набор библиотек для обработки текста в целях классификации, токенизации, генерации, тегирования, синтаксического анализа и понимания семантики, создания оболочки библиотек NLP для коммерческого применения.
Книга Natural Language Processing with Python — практическое введение в программирование для обработки языка. Рекомендуем ее прочитать, если вы владеете английским языком.
Загрузка и установка NLTK
- Установите NLTK: запустите pip install nltk.
- Тестовая установка: запустите python, затем введите import nltk.
Инструкции для конкретных платформ смотрите здесь.
Установка пакетов NLTK
Импортируйте NLTK и запустите nltk.download(). Это откроет загрузчик NLTK, где вы сможете выбрать версию кода и модели для загрузки. Вы также можете загрузить все пакеты сразу.
Предварительная обработка текста с помощью NLTK
Основная проблема с данными заключается в том, что они представлены в текстовом формате. Для решения задач алгоритмами машинного обучения требуется некий вектор свойств. Поэтому прежде чем начать создавать проект по NLP, нужно предварительно обработать его. Предварительная обработка текста включает в себя:
- Преобразование букв в заглавные или строчные, чтобы алгоритм не обрабатывал одни и те же слова повторно.
- Токенизация. Токенизация — термин, используемый для описания процесса преобразования обычных текстовых строк в список токенов, то есть слов. Токенизатор предложений используется для составления списка предложений. Токенизатор слов составляет список слов.
Пакет NLTK включает в себя предварительно обученный токенизатор Punkt для английского языка.
- Удаление шума, то есть всего, что не является цифрой или буквой;
- Удаление стоп-слов. Иногда из словаря полностью исключаются некоторые крайне распространенные слова, которые, как считается, не имеют большого значения для формирования ответа на вопрос пользователя. Эти слова называются стоп-словами (междометия, артикли, некоторые вводные слова);
- Cтемминг: приведение слова к коренному значению. Например, если нам нужно провести стемминг слов «стемы», «стемминг», «стемированный» и «стемизация», результатом будет одно слово — «стем».
- Лемматизация. Лемматизация — немного отличающийся от стемминга метод. Основное различие между ними заключается в том, что стемминг часто создает несуществующие слова, тогда как лемма — это реально существующее слово. Таким образом, ваш исходный стем, то есть слово, которое получается после стемминга, не всегда можно найти в словаре, а лемму — можно. Пример лемматизации: «run» — основа для слов «running» или «ran», а «better» и «good» находятся в одной и той же лемме и потому считаются одинаковыми.
Набор слов
После первого этапа предварительной обработки нужно преобразовать текст в вектор (или массив) чисел. «Набор слов» — это представление текста, описывающего наличие слов в тексте. «Набор слов» состоит из:
- словаря известных слов;
- частот, с которыми каждое слово встречается в тексте.
Почему используется слово «набор»? Это связано с тем, что информация о порядке или структуре слов в тексте отбрасывается, и модель учитывает только то, как часто определенные слова встречаются в тексте, но не то, где именно они находятся.
Идея «набора слов» состоит в том, что тексты похожи по содержанию, если включают в себя похожие слова. Кроме того, кое-что узнать о содержании текста можно лишь по набору слов.
Например, если словарь содержит слова {Learning, is, the, not, great} и мы хотим составить вектор предложения “Learning is great”, получится вектор (1, 1, 0, 0, 1).
Метод TF-IDF
Проблема «набора слов» заключается в том, что в тексте могут доминировать часто встречающиеся слова, которые не содержат ценную для нас информацию. Также «набор слов» присваивает большую важность длинным текстам по сравнению с короткими.
Один из подходов к решению этих проблем состоит в том, чтобы вычислять частоту появления слова не в одном тексте, а во всех сразу. За счет этого вклад, например, артиклей «a» и «the» будет нивелирован. Такой подход называется TF-IDF (Term Frequency-Inverse Document Frequency) и состоит из двух этапов:
- TF — вычисление частоты появления слова в одном тексте
TF = (Число раз, когда слово "t" встречается в тексте)/(Количество слов в тексте)
- IDF — вычисление того, на сколько редко слово встречается во всех текстах
IDF = 1+log(N/n), где N - общее количество текстов, n - во скольких текстах встречается "t"
Коэффициент TF-IDF — это вес, часто используемый для обработки информации и интеллектуального анализа текста. Он является статистической мерой, используемой для оценки важности слова для текста в некотором наборе текстов.
Пример
Рассмотрим текст, содержащий 100 слов, в котором слово «телефон» появляется 5 раз. Параметр TF для слова «телефон» равен (5/100) = 0,05.
Теперь предположим, что у нас 10 миллионов документов, и слово телефон появляется в тысяче из них. Коэффициент вычисляется как 1+log(10 000 000/1000) = 4. Таким образом, TD-IDF равен 0,05 * 4 = 0,20.
TF-IDF может быть реализован в scikit так:
from sklearn.feature_extraction.text import TfidfVectorizer
Коэффициент Отиаи
TF-IDF — это преобразование, применяемое к текстам для получения двух вещественных векторов в векторном пространстве. Тогда мы можем получить коэффициент Отиаи любой пары векторов, вычислив их поэлементное произведение и разделив его на произведение их норм. Таким образом, получается косинус угла между векторами. Коэффициент Отиаи является мерой сходства между двумя ненулевыми векторами. Используя эту формулу, можно вычислить схожесть между любыми двумя текстами d1 и d2.
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
Здесь d1, d2 — два ненулевых вектора.
Подробное объяснение и практический пример TF-IDF и коэффициента Отиаи приведены в посте по ссылке.
Пришло время перейти к решению нашей задачи, то есть созданию чат-бота. Назовем его «ROBO».
Обучение чат-бота
В нашем примере мы будем использовать страницу Википедии в качестве текста. Скопируйте содержимое страницы и поместите его в текстовый файл под названием «chatbot.txt». Можете сразу использовать другой текст.
Импорт необходимых библиотек
import nltk import numpy as np import random import string # to process standard python strings
Чтение данных
Выполним чтение файла corpus.txt и преобразуем весь текст в список предложений и список слов для дальнейшей предварительной обработки.
f=open('chatbot.txt','r',errors = 'ignore')
raw=f.read()
raw=raw.lower()# converts to lowercase
nltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use only
sent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences word_tokens = nltk.word_tokenize(raw)# converts to list of words
Давайте рассмотрим пример файлов sent_tokens и word_tokens
sent_tokens[:2] ['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods.', 'such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the turing test.']
word_tokens[:2]
['a', 'chatbot', '(', 'also', 'known']
Предварительная обработка исходного текста
Теперь определим функцию LemTokens, которая примет в качестве входных параметров токены и выдаст нормированные токены.
lemmer = nltk.stem.WordNetLemmatizer() #WordNet is a semantically-oriented dictionary of English included in NLTK.
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
Подбор ключевых слов
Определим реплику-приветствие бота. Если пользователь приветствует бота, бот поздоровается в ответ. В ELIZA используется простое сопоставление ключевых слов для приветствий. Будем использовать ту же идею.
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)
GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
Генерация ответа
Чтобы сгенерировать ответ нашего бота для ввода вопросов, будет использоваться концепция схожести текстов. Поэтому мы начинаем с импорта необходимых модулей.
- Импортируйте векторизатор TFidf из библиотеки, чтобы преобразовать набор необработанных текстов в матрицу свойств TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
- Кроме того, импортируйте модуль коэффициента Отиаи из библиотеки scikit
from sklearn.metrics.pairwise import cosine_similarity
Этот модуль будет использоваться для поиска в запросе пользователя ключевых слов. Это самый простой способ создать чат-бота.
Определим функцию отклика, которая возвращает один из нескольких возможных ответов. Если запрос не соответствует ни одному ключевому слову, бот выдает ответ «Извините! Я вас не понимаю».
def response(user_response):
robo_response=''
TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response
Наконец, мы задаем реплики бота в начале и конце переписки, в зависимости от реплик пользователя.
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome..")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
sent_tokens.append(user_response)
word_tokens=word_tokens+nltk.word_tokenize(user_response)
final_words=list(set(word_tokens))
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care..")
Вот и все. Мы написали код нашего первого бота в NLTK. Здесь вы можете найти весь код вместе с текстом. Теперь давайте посмотрим, как он взаимодействует с людьми:

Получилось не так уж плохо. Даже если чат-бот не смог дать удовлетворительного ответа на некоторые вопросы, он хорошо справился с другими.
Заключение
Хотя наш примитивный бот едва ли обладает когнитивными навыками, это был неплохой способ разобраться с NLP и узнать о работе чат-ботов. «ROBO», по крайней мере, отвечает на запросы пользователя. Он, конечно, не обманет ваших друзей, и для коммерческой системы вы захотите рассмотреть одну из существующих бот-платформ или фреймворки, но этот пример поможет вам продумать архитектуру бота.
Интересные статьи:
- Как создать собственную нейронную сеть с нуля на языке Python
- Word2Vec: как работать с векторными представлениями слов
- Как применять теорему Байеса для решения реальных задач