Modern autonomous mobile robots (including self-driving cars) require a strong understanding of their environment in order to operate safely and effectively. Comprehensive and accurate models of the surrounding environment are crucial for solving the challenges of autonomous operation. However, only a limited amount of information is perceived through the sensors which are limited regarding their capabilities, the field of view and the kind of data they provide.
While sensors like LIDAR, Radar, Kinect provide 3D data including all spatial dimensions, cameras on the other hand only provide a 2D view of the surrounding. In the past, many attempts have been made to actually extract the 3D data out of 2D images coming from the camera. The human visual system is remarkably successful in solving this task, while algorithms very often fail to reconstruct and infer a depth map out of an image.
A novel approach proposes using deep learning in a self-supervised manner to tackle the problem of monocular depth estimation. In fact, researchers from the University College of London have developed an architecture for depth estimation that beats the current state-of-the-art depth estimation on the KITTI dataset challenge. Arguing that large-scale, varied datasets with ground truth training data are scarce, they propose a self-supervision based approach using monocular videos. Their approach and improvements
in-depth estimation, work well with monocular video data as well as with stereo pairs (Note: Synchronized pairs of data from stereo camera) or even with a combination of both.

The method
A simple way to address the depth estimation problem from a deep learning perspective is to train a network using depth images as ground truth in a supervised manner. However, as mentioned before having enough labeled data (in this case paired 2D-3D data) to be able to train sufficiently large (and deep) network architecture represents a challenge. As a consequence, the authors explore a self-supervised training approach. They frame the problem as a view-synthesis, where the network learns to predict a target image from the viewpoint of another. The proposed method is able to give depth estimation, given only a single color image.
An important problem that has to be taken into account when dealing with depth estimation is ego-motion. Especially in the cases with autonomous mobile robots, ego-motion estimation is crucial for obtaining good results in different tasks, not excluding depth estimation. In order to compensate ego-motion existing approaches have proposed a separate pose estimation network. In fact, this task of this network is to learn and to be able to estimate the relative camera transformation between subsequent sensor measurements (images).
Unlike these previously existing approaches who make use of a separate pose estimation network besides the depth estimation network, the novel method is using the encoder part of the depth estimation network as a transformer in the pose estimation network. To explain this more precisely, the pose estimation network (shown in the figure below) is concatenating features obtained from the encoder instead of concatenating the frames i.e. the raw data directly. The authors state that this significantly improves the results of pose estimation while reducing the number of parameters that have to be learned. They argue that this comes from the abstract features from the encoder which carry an important understanding of the geometry of the input images. The depth estimation network proposed in this paper is based on a U-net architecture (an encoder-decoder U shaped network with skip connections) and it ELU activations together with sigmoids. The encoder in the network is a pre-trained ResNet18.
The Encoder-Decoder depth estimation network (left). The usual pose estimation network (right). The proposed pose estimation network using the encoder from the depth estimation network (middle)
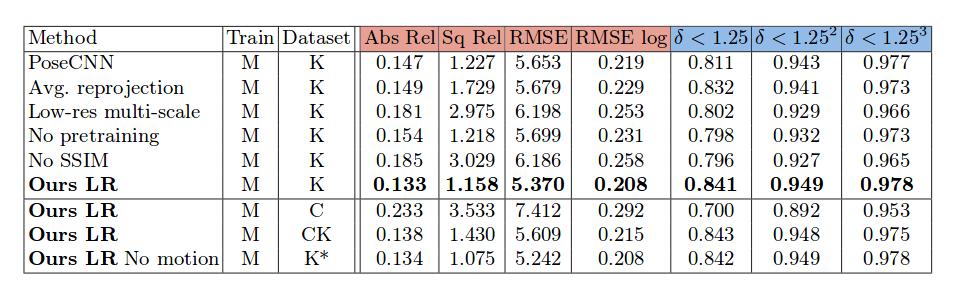
Besides the novel architecture, several improvements have been proposed. Firstly, the authors use a specifically designed loss function incorporating both L1 loss and SSIM (Structural Similarity Index). Secondly, they introduce an interesting approach where they compute the photometric error (the loss) in higher resolution images by up-sampling the low-resolution depth maps. Intuitively, this avoids the problem of creating holes in some parts of the image due to the error computation on down-sampled (encoded) depth maps. Finally, they add a smoothness term to their loss function.
Experiments
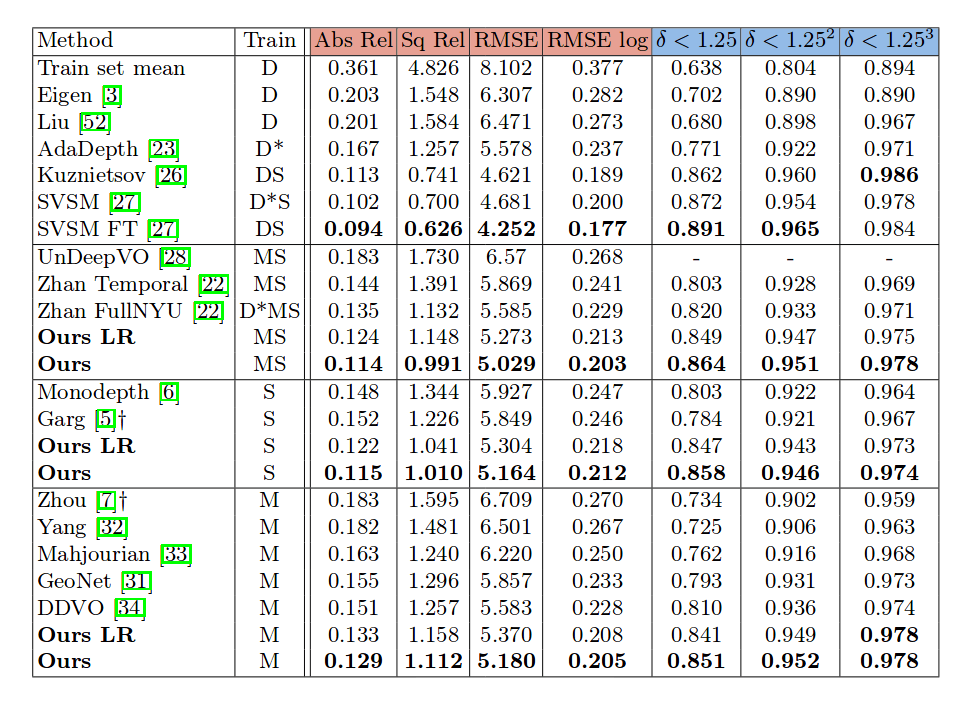
The implementation is done in PyTorch and the training was conducted using the KITTI dataset of 128×416 input image resolution. The size of the dataset is around 39 000 triplets for training and evaluation, and data augmentation is extensively used in the form of horizontal mirroring, changes in brightness, contrast, saturation, hue jitter etc. Some of the results obtained are given in the table below.
Conclusion
This novel approach shows promising results in depth estimation from images. As an important task in the framework of future autonomous robots, 3D depth estimation is getting more and more attention thus making
it questionable if we actually have a need of (often expensive and complex) 3D sensors. Accurate depth estimation can have many applications besides mobile robots and self-driving cars, namely in many fields ranging from simple image editing to complete image understanding. Last but not least, this approach confirms again the power of deep learning, especially the power of encoder-decoder convolutional networks in a wide range of tasks.