
Recognizing facial expressions is quite an interesting and at the same time challenging task. The humans are likely to benefit significantly if facial expression recognition is performed automatically by computer algorithms. Possible applications of such an algorithm would include better transcription of videos, movie or advertisement recommendations, detection of pain in telemedicine, etc.
Still, not even all humans perform equally well at recognizing other people’s emotions, but it seems that machines should be good at this, shouldn’t they? We all know that humans express their emotions with eyes, eyebrows, lips movements. So how good are current state-of-the-art approaches in recognizing these motion patterns? It turns out that modern machine learning algorithms demonstrate around 55% accuracy for recognizing facial expressions from the real-world images and 46% accuracy while performing the same task from the videos.
Let’s now discover how covariances can improve the accuracy, with which facial expressions are recognized and classified.

Figure 1. Sample images of different expressions and distortion of the region between eyebrows in the corresponding image
What is suggested to improve the results?
Group of researchers from ETH Zurich (Switzerland) and KU Leuven (Belgium) point out to the fact that classifying facial expressions into different categories (sadness, anger, joy, etc.) requires capturing regional distortions of facial landmarks. Next, they believe that second-order statistics such as covariance is more suited to capture such distortions in regional facial features.
The suggested approach was applied to two separate tasks:
- Facial expression recognition from images: covariance pooling was introduced after final convolutional layers. Dimensionality reduction was carried out using the concepts from the manifold network, which was trained together with conventional CNNs in the end-to-end fashion.
- Facial expression recognition from videos: covariance pooling was used here to capture the temporal evolution of per-frame features. The researchers conducted several experiments using manifold networks for pooling per-frame features.
Now, let’s dig deeper into this new approach to facial expression recognition using covariance pooling.
Model architecture
First, image-based facial expression recognition will be discussed. Here the algorithm starts with face detection to get rid of the irrelevant information that is contained in the real-world images. So, face detection is performed and aligned based on the facial landmark locations. Then, normalized faces are fed into a deep CNN. In order to pool the feature maps spatially from the CNN, covariance pooling is used. Finally, the manifold network is employed to deeply learn the second-order statistics.
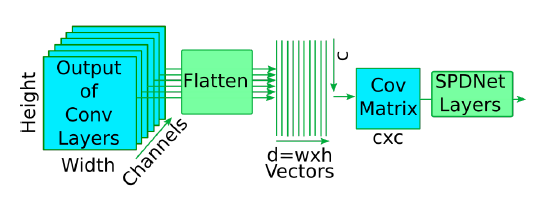
Figure 2. The pipeline of the proposed model for image-based facial expression recognition
Next, the model for video-based facial expression recognition is mostly similar to the image-based one, but yet has some peculiarities. Firstly, the pipeline starts with getting useful information from videos: all frames are extracted from videos, and then face detection and alignment is performed on each individual frame. Furthermore, the authors of this model suggested pooling the frames over time since, intuitively, the temporal covariance can capture the useful facial motion pattern. Afterward, they again employed the manifold network for dimensionality reduction and non-linearity on covariance matrices.
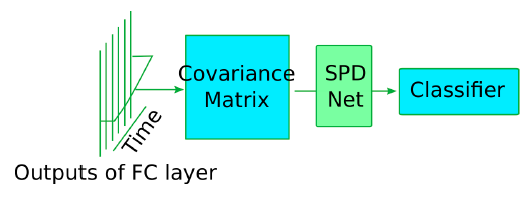
Figure 3. The overview of the presented model for video-based facial expression recognition
Now, let’s have a short overview of the two core techniques used in the proposed models: covariance pooling and manifold network for learning the second-order features deeply.
Covariance pooling. Covariance matrix was used for summarizing the second-order information in the set. However, in order to preserve the geometric structure while employing layers of the symmetric positive definite (SPD) manifold network, the covariance matrices are required to be SPD. But, even if the matrices are only positive semi-definite, they can be regularized by adding a multiple of the trace to diagonal entries of the covariance matrix.
SPD Manifold Network (SPDNet). The covariance matrices calculated on the previous step typically reside on the Riemannian manifold of SPD matrices. They are often large, and their dimension needs to be reduced without losing the geometric structure. So, let’s briefly discuss specific layers that are used to solve these tasks:
- Bilinear Mapping Layer (BiMap) accomplishes the task of reducing dimension while preserving the geometric structure.
- Eigenvalue Rectification Layer (ReEig) is used to introduce non-linearity.
- Log Eigenvalue Layer (LogEig) endows elements in the Riemannian manifold so that matrices can be flattened, and standard Euclidean operations can be applied.
Note that BiMap and ReEig layers can be used together, and so the block of these two layers is abbreviated as BiRe.
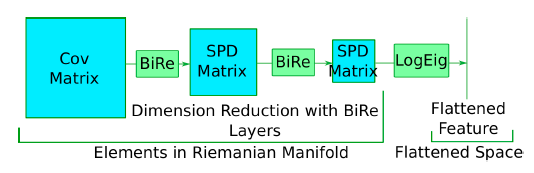
Figure 4. Illustration of SPD Manifold Network (SPDNet) with 2-BiRe layers
Results for image-based facial expression recognition
To compare the performance of the suggested approach to some baseline models, researchers used two datasets:
- Real-world Affective Faces (RAF) contains 15331 images labeled with seven basic emotion categories of which 3068 were used for validation and 12271 for training.
- Static Facial Expressions in the Wild (SFEW) 2.0 contains 1394 images, of which 958 were used for training and 436 for validation.
Then, it was decided to experiment with various models while introducing covariance pooling. You can see the details of the models considered in Table 1.
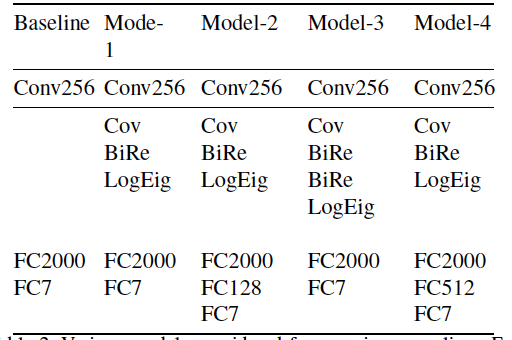
Table 1. Various models considered for covariance pooling
Now, various models described in the table above, as well as some other state-of-the-art models without covariance pooling, are listed in Table 2 together with the respective accuracies.
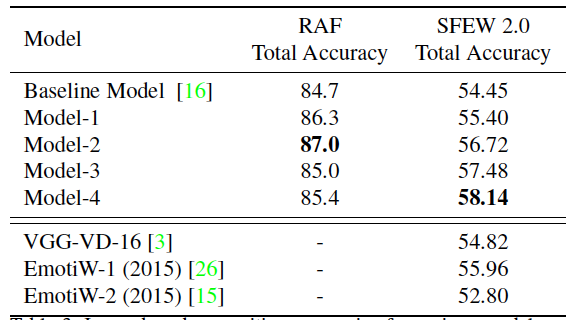
Table 2. Comparison of image-based recognition accuracies for various models
As you can see, Model-2 demonstrates 87% accuracy in the RAF dataset and outperforms the baseline model for 2.3%, which is a very good result for such a challenging task as face expression recognition. Next, Model-4 with covariance pooling shows improvement of almost 3,7% over baseline in the SFEW 2.0 dataset, which obviously justifies the use of SPDNet for image-based facial expression recognition. In total, these results are the best results for this kind of problem achieved by various state-of-the-art methods so far.

Figure 5. Samples from each class of the SFEW dataset that were most accurately and least accurately classified.
Results for video-based facial expression recognition
Here Acted Facial Expressions in the Wild (AFEW) dataset was used to compare a novel approach with existing methods. This dataset was prepared by selecting videos from movies. It contains about 1156 publicly available labeled videos of which 773 videos were used for training and 383 for validation.
The results of the proposed methods with covariance pooling as well as of some other state-of-the-art methods selected for comparison are provided below. However, it should be noted that datasets used for pretraining of other models are not uniform, and so the detailed comparison of all existing methods requires further research.
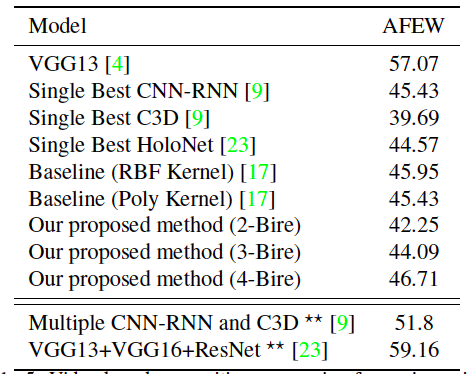
Table 3. Comparison of video-based recognition accuracies for various models.
As it can be observed from the Table 3, the model with covariance pooling and 4 BiRe layers was able to slightly surpass the results of the baseline model. It also demonstrated higher accuracy than all single models that were trained on publicly available training datasets. The VGG13 network, which shows much higher accuracy was trained on a private dataset containing a significantly higher number of samples. Still, we cannot conclude that introducing covariance pooling to the problem of video-based face expression recognition provides any significant improvements with regards to recognition accuracy.
Conclusion
In summary, this study introduces the end-to-end pooling of second-order statistics for both videos and images in the context of facial expression recognition. However, state-of-the-art results were achieved only for image-based facial expression recognition. Here the recognition accuracy after introducing covariance pooling to the model outperformed all other existing methods.
For the problem of video-based facial expression recognition, training SPDNet on image-based features was still able to obtain results comparable to state-of-the-art results. Not very high accuracy of the suggested method could be a result of the relatively small size of AFEW dataset compared to parameters in the network. The authors of this method conclude that further work is necessary to see if training end-to-end using joint convolutional network and SPDNet can improve the results.




