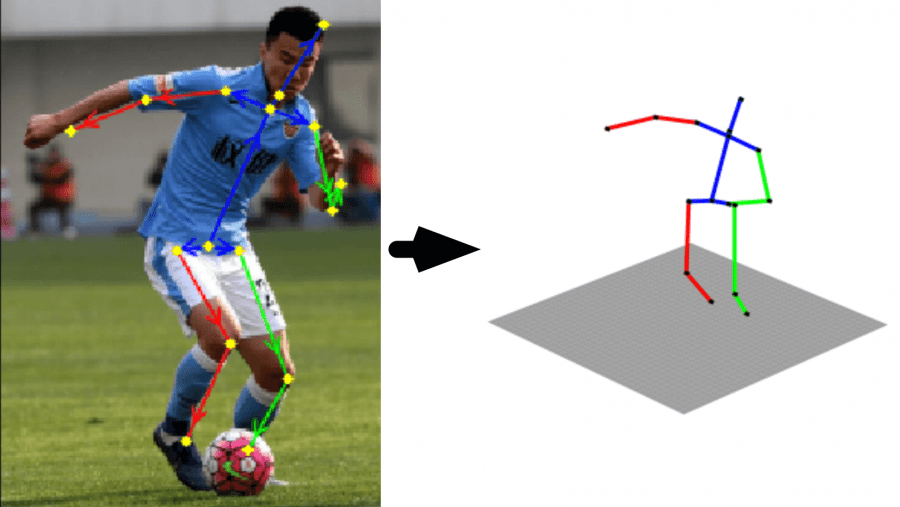
Autonomous driving, virtual reality, human-computer interaction and video surveillance — these are all application scenarios, where you would like to derive a 3D human pose out of a single RGB image. Significant advances have been made in this area after Convolutional Neural Network has been employed to solve the problem of 3D pose inference. However, the task remains challenging for outdoor environments as it is very difficult to obtain 3D pose ground truth for in-the-wild images.
So, let’s see how this fancy “FBI” abbreviation helps with inferring a 3D human pose out of a single RGB image.
Suggested Approach
Group of researchers forms Shenzhen (China) proposed a novel framework for deriving a 3D human pose from a single image. In particular, they suggest exploiting the information of each bone indicating if it is forward or backward with respect to the view of the camera. They refer to this data as Forward-or-Backward Information (or simply, FBI).
Their method starts with training a Convolutional Neural Network with two branches: one is related to mapping 2D joint locations from an image and another comes from FBI of bones. In fact, several state-of-the-art methods use information on the 2D joint locations for predicting a 3D human pose. However, this is an ill-posed problem since different valid 3D poses can explain the same observed 2D joints. At the same time, information on whether each bone is forward or backward when combined with 2D joint locations provides a unique 3D joint position. So, the researchers claim that feeding both 2D joint locations and FBI of bones into a deep regression network will provide better predictions of the 3D positions of joints.

Furthermore, to support the training, they have developed an annotation user interface and labeled FBI for around 12,000 in-the-wild images. They simplified the problem by distinguishing 14 bones with each bone having one of the three states with respect to camera view: forward, backward or parallel to sight. Hired annotators were asked to label images randomly selected from MPII dataset, where the 2D bones are provided. For each of the bones, the annotator was asked to make a choice from three options: forward, backward or uncertain (considering the difficulty to give an accurate judgment for the “parallel to sight” option). It is reported that in total around 20% of bones were marked as uncertain. The figure above illustrates the distribution of out-of-plane angles for all uncertain bones. As expected, people show more uncertainty when the bone is closer to parallel with the view plane.
Network Architecture
Let’s now discover in more depth the network architecture of the suggested approach.

The network consists of three components:
1. 2D pose estimator. It takes an image of a human as input and outputs the 2D locations of 16 joints of the human.
2. FBI predictor. This component also takes an image as input but outputs the FBI of 14 bones with three possible statuses: forward, backward and uncertain. The network here starts from a sequence of convolutional layers, followed by two successive stacked hourglass modules. The extracted feature maps are then fed into a set of convolutional layers and followed by a fully connected layer with a softmax layer to output classification results.
3. 3D pose regressor. At this stage, a deep regression network is learned to infer the 3D coordinates of the joints by taking both their 2D locations and the FBI as input. To keep more information, the regressor takes the generated probability matrix of the softmax layer as input. Thus, 2D locations and the probability matrix are concatenated together and then mapped to the 3D pose by exploiting two cascaded blocks.
Comparisons against existing methods
The quantitative comparison was carried out based on Human3.6M, a dataset containing 3.6 million of RGB images that capture 7 professional actors performing 15 different activities (i.e., walking, eating, sitting etc.). The mean per joint position error (MPJPE) between the ground truth and prediction was used as the evaluation metric, and the results are presented in Table 1.
![Table 1. Quantitative comparisons based on MPJPE. Ordinal [19] is a concurrent work with the method presented here. The best score without consideration of this work is marked in blue bold. Black bold is used to highlight the best score when taking this work for comparison.](https://new.neurohive.io/wp-content/uploads/2018/07/table1.png)
For some of the previous works, the prediction has been further aligned with the ground truth via a rigid transformation. The results are presented in the table below.
![Table 2. Quantitative comparisons based on MPJPE after rigid transformation. Ordinal [19] is a concurrent work with the method presented here. The best score without consideration of this work is marked in blue bold. Black bold is used to highlight the best score when taking this work for comparison.](https://new.neurohive.io/wp-content/uploads/2018/07/table2.png)
The results of the quantitative comparison demonstrate that the presented approach outperforms all previous works almost on all actions and makes considerable improvements in such complicated actions like sitting and sitting down. However, it worth noting that one of the works, marked as Ordinal [19] in the above tables, exploited a similar strategy and achieved comparable results. Specifically, it proposed an annotation tool for collecting the depth relations for all joints. However, their annotation procedure seems to be a much more tedious task comparing to the one presented in this article.
To confirm the efficiency of this method for in-the-wild images, the researchers took 1,000 images from their FBI dataset as a test data and conducted another comparison against the state-of-the-art method presented by Zhou et al. Here the correctness ratio of FBI derived from the 3D pose was used as the evaluation metric. Thus, the method of Zhou et al. had 75% correctness ratio while the presented approach reached 78%. You can also see the results of a qualitative comparison on the image below.

Bottom line
The proposed approach suggests exploiting a new information called Forward-Backward Information (FBI) of bones for 3D human pose estimation, and this piece of data, in fact, helps to get more 3D-aware features from images. As a result, this method outperforms all previous works. However, this is not the only contribution of this research team. They have also labeled the FBI for 12,000 in-the-wild images with a well-designed user interface. These images will become publicly available to benefit other researchers working in this area.








[…] Перевод – Борис Румянцев, оригинал. […]