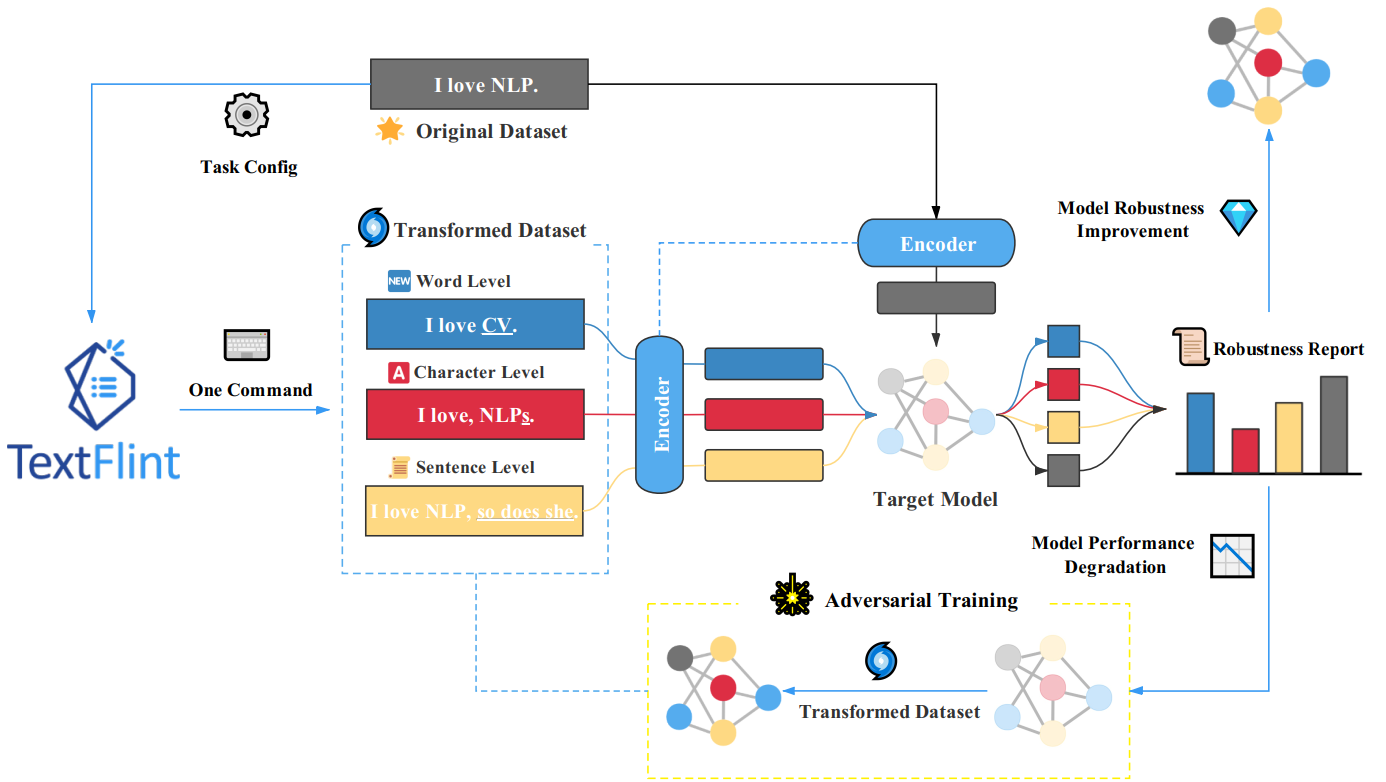
TextFlint – мультиязычная, многозадачная платформа для анализа устойчивости NLP-моделей. В открытом доступе для английского и китайского языков, другие языки разрабатываются. Включает инструменты обработки текста:
- общие и специфические преобразования текста;
- выделение подмножеств;
- преобразование текста для состязательных атак;
- комбинации перечисленного.
Зачем это нужно
Генерализация NLP-моделей необходима для обеспечения устойчивости и стабильных показателей не только на тестовых, но и на произвольных данных. Модели, обученные на не исчерпывающих датасетах, повторяют неполноту данных. К тому же, глубокие нейронные сети уязвимы для состязательных атак на тщательно подобранных примерах.
Чтобы проверить полезность TextFlint, авторы протестовали более 67000 современных моделей глубокого обучения, моделей классического обучения с учителем и действующих систем. Почти все модели показали значительное снижение производительности. Точность прогнозов BERT для распознавания настроения текста, распознавания именованных сущностей и логического вывода на естественном языке была снижена более чем на 50%. Цель авторов – предоставить разработчикам удобный и автоматизированный инструмент для создания устойчивых NLP-моделей.
Особенности TextFlint
Полное покрытие преобразований текста. TextFlint применяет 20 общих преобразований, 8 выделений подмножества и 60 специфических преобразований, а также тысячи их комбинаций. Поддерживается преобразование текста для состязательной атаки на конкретную модель.
Генерация размеченных аугментированных данных. TextFlint поддерживает преобразование произвольных текстов с генерацией соответствующих лейблов. Доступны для загрузки 6903 датасета, сгенерированных преобразованием 24 известных датасетов для задач NLP.
Полный аналитический отчет. TextFlint предоставляет отчет об анализе лексики, синтаксиса и семантики модели с указанием недостатков. Оценивается, насколько выход модели лингвистически согласован и приемлем для человека. На основании выявленных дефектов платформа генерирует большое количество данных для дообучения модели.