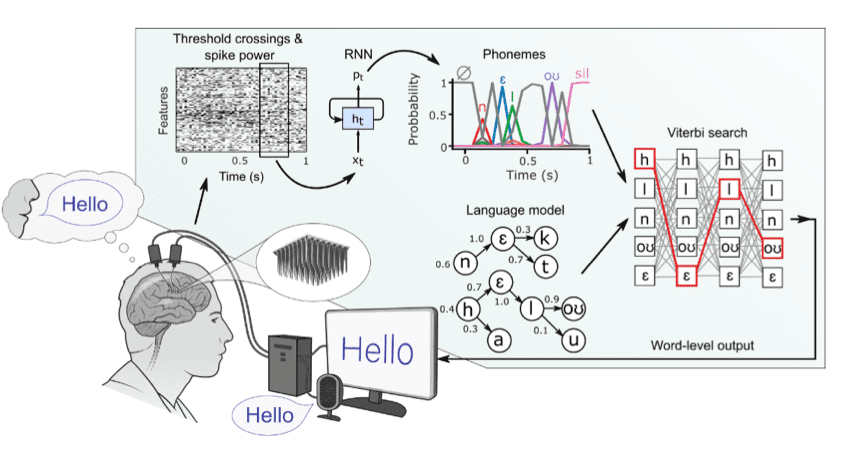
Исследователи Стэнфордского университета разработали интерфейс мозг-компьютер для синтеза речи из сигналов, захваченных в мозге пациента и обработанных рекуррентной нейросетью. Прототип системы может декодировать речь со скоростью 62 слова в минуту, что в 3.4 раза быстрее альтернативных методов.
Использование моделей глубокого обучения для интерпретации активности человеческого мозга является активной областью исследований. В большинстве из них используются имплантированные в мозг пациента датчики для генерации текста на основе сигналов мозга. Вместе с тем, в ряде исследований использовались носимые датчики используемые, например, для управления в видеоиграх.
Работая с пациентом, который потерял способность к речи из-за бокового амиотрофического склероза, ученые использовали имплантированные в мозг пациента микроэлектроды для детектирования сигналов нервной активности, генерируемых при попытках пациентом произнести предложения. Эти сигналы подавались на вход управляемого реккурентного блока, обученного декодировать нейронные сигналы в фонемы для синтеза речи.
Чтобы собрать обучающую выборку, пациента попросили попытаться произнести 10850 предложений. Для тестирования модели использовались предложения, отсутствовавшие при обучении. Тестовая выборка включала в себя предложения двух типов, состоящих из 50 различных слов и 125 тысяч различных слов.
Ученые выяснили, что сокращение интервала между обучением и тестированием нейросети уменьшает ошибку декодирования из-за нивелирования вклада изменений в нейронной активности. При обучении на 50 слов система достигла 9%-ной точности декодирования, а на 125 тысячах слов – 23,8%-ной точности.
Скорость декодирования 62 слова в минуту, достигнутая в экспериментах, в 3.4 раза превосходит скорость альтернативных технологий, позволяющих общаться пациентам с параличом.