DeepView — это нейросеть, которая по паре входных фотографий восстанавливает вид с фотографии с остальных ракурсов. Результаты работы нейросети можно посмотреть на официальном сайте. Модель получает state-of-the-art результаты на датасетах Lytro и Spaces, который был собран исследователями вручную.
Нейросеть принимает на вход изображения одного вида с разных ракурсов и восстанавливает остальные ракурсы так, что на изображение можно смотреть в 3D. Модель учитывает такие характеристики вида, как границы объектов, тени от освещения, тонкие объекты и сцены с сложной перспективой.
Что внутри DeepView
Пайплайн работы модели состоит из следующих шагов:
- Сеть принимает на вход ряд изображений с разных ракурсов;
- Сцена на изображениях реконструируется с помощью обученного градиентного спуска (LGD);
- На выходе сеть отдает многоплановое изображение (multi-plane image) со сценой во всех ракурсах
Изображения обрабатываются в сверточной нейросети, которая предсказывает многоплановое изображение. Предсказанное изображение затем итеративно улучшается. Для этой задачи градиенты имеют интуитивное объяснение. Они кодируют характеристики сцены между входными видами слоями многопланового изображения. Изображения, которые нейросеть отдает на выходе, могут использоваться для синтезирования изображений видов в реальном времени.

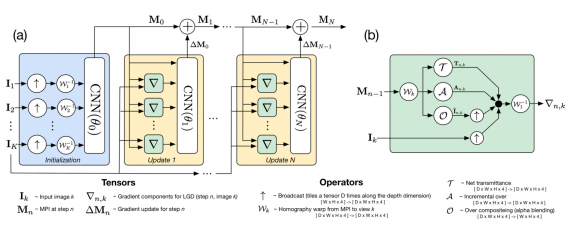
DeepView состоит из нескольких частей:
- Сверточная нейросеть, которая инициализирует многоплановое изображение на основе входных изображений (а — голубой блок);
- Последовательность сверточных нейросетей, которые итеративно улучшают сгенерированное изображение. Все сети в последовательности имеют одну архитектуру и разные веса (a — желтые блоки);
- Вместо того, чтобы напрямую вычислять градиент по функции потерь, модель считает градиенты для каждого отдельного вида в многоплановом изображении (b)
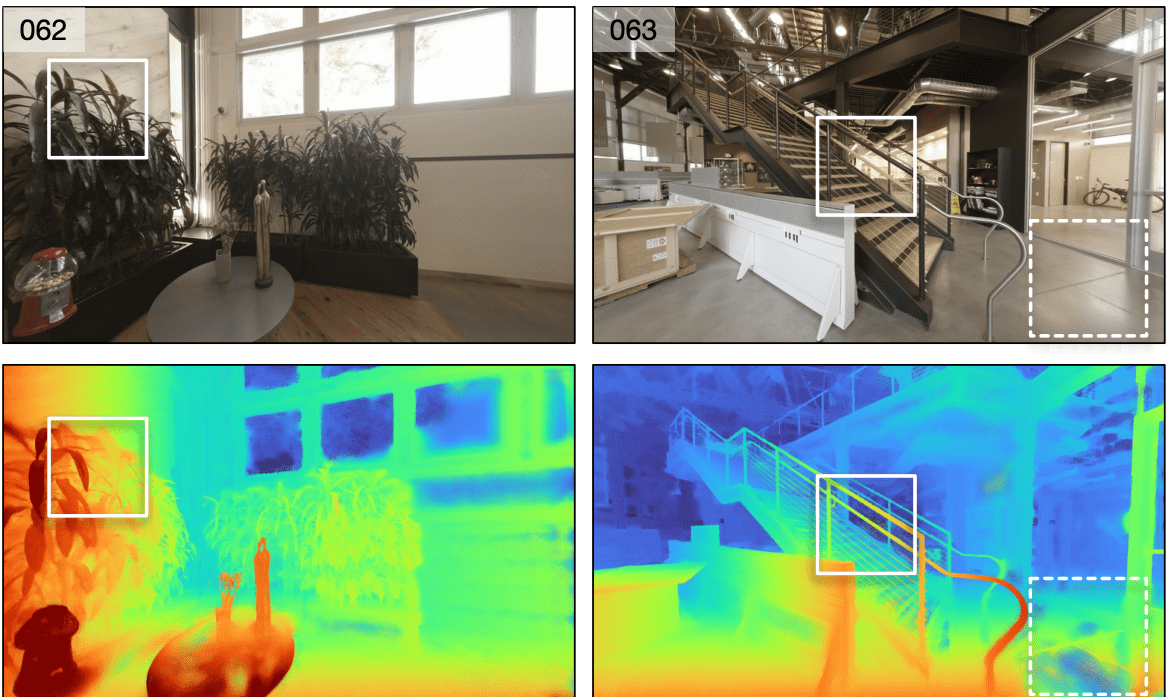
Оценка работы модели
Исследователи провели два эксперимента: на готовом датасете от Kalantari et al. (Lytro) и на собственном датасете Spaces, который также был опубликован. Lytro часто используется для генерации сцен, но изображения там ограничены маленьким диаметром линзы. Задача синтезирования видов на основе изображений с разных ракурсов более комплексная. Spaces исследователи собрали именно поэтому.
Ниже видно, что результаты DeepView сравнимы с state-of-the-art методом Soft3D.