Команда Google Brain представила оптимайзер LAMB, способный сократить время предобучения языковой модели BERT с 3-х дней до 76 минут (вычисления проводились на TPU).
Transfer learning и проблема BERT
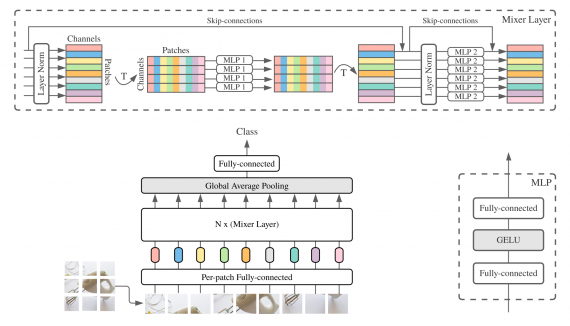
BERT (Bidirectional Encoder Representations from Transformers) — алгоритм для решения задачи transfer learning в обработке естественного языка. Задача transfer learning сводится к тому, что для предсказания следующего слова необходимо хранить информацию о контексте предыдущих слов (память). BERT был представлен в 2018 году исследователями из Google.
BERT изначально показывал лучшие результаты в экспериментах в сравнении с конкурирующими архитектурами, однако, полная версия модели обучается за 1 миллион итераций. Это делает модель высоко ресурсозатратной и вводит ограничение на ее самостоятельное предобучение. Чтобы частично решить проблему масштабирования модели, исследователи предлагают заменить AdamW оптимайзер, используемый для обучения BERT, на LAMB (Layer-wise Adaptive Moments optimizer for Batch training).
Общая задача нейронной сети сводится к поиску глобального минимума на плоскости. Оптимайзер нужен нейронной сети, чтобы решать, в какую сторону делать шаг на каждой из итераций обучения нейросети.
LAMB оптимайзер
Значительное преимущество LAMB в том, что единственный гиперпараметр, который он принимает на вход — это learning rate. Использование LAMB помогает уменьшить размер батчей до 65536, не теряя в точности модели. Псевдокод, описывающий алгоритм работы LAMB представлен на картинке ниже.

C помощью LAMB исследователи смогли сократить количество требуемых для обучения итераций с 1 миллиона до 8599 (с размером батчей равным 65536/32768).
Результаты работы BERT с LAMB оптимайзером
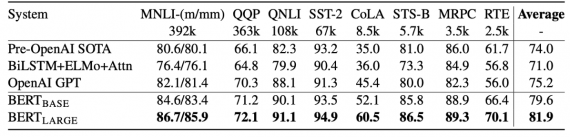
В экспериментах, проведенных для тестирования работы оптимизированной модели, использовался TPUv3 Pod с 1024 чипами. Это необходимо учитывать, чтобы адекватно оценивать масштабы ресурсозатратности обучения BERT.
В качестве бейзлайна исследователи использовали F1 меру полной модели (BERT-Large). В экспериментах были использованы те же сеты данных, что и для опубликованной изначально модели: Wikipedia, содержащий 2.5 миллиарда слов, и BooksCorpus, содержащий 800 миллионов слов.
Предобучение BERT состоит из двух этапов:
- На первых 90% эпохах размер последовательностей слов составляет 128;
- На последних 10% эпох размер последовательностей слов увеличивается до 512.
Обучение масштабированной версии BERT закончилось в 8599 итераций с размером батча равным 64 тыс. (для этапа 1) и 32 тыс. (для этапа 2).
В результате обучение завершилось за 76 минут. Так, исследователям получилось оптимизировать эффективность модели на 101.8%.