Разработчики Google AI представили новый алгоритм для разделения звуковых потоков на видео. Модель разделяет аудио на сегменты и определяет, кто из участников диалога говорит в данный момент. Алгоритм работает лучше, чем подходы, основанные на кластеризации, и распознает говорящего с точностью 92,4%. Технология может применяться, например, для создания субтитров к видеозаписям в реальном времени.
Контролируемое обучение RNN
Процесс разделения аудиопотока на сегменты называется диаризацией. Другие современые подходы к диаризации используют метод k—средних или спектральную кластеризацию и обычно обучаются неконтролируемо. Ключевое отличие разработки Google в использовании обучения с учителем. Все компоненты системы, включая распознавание спикеров и работу с метками времени, обучаются контролируемо, поэтому извлекают больше пользы из размеченных данных.
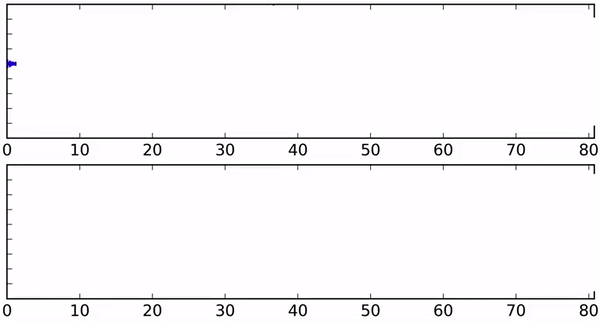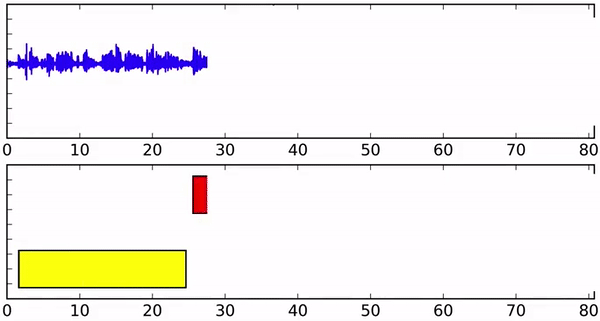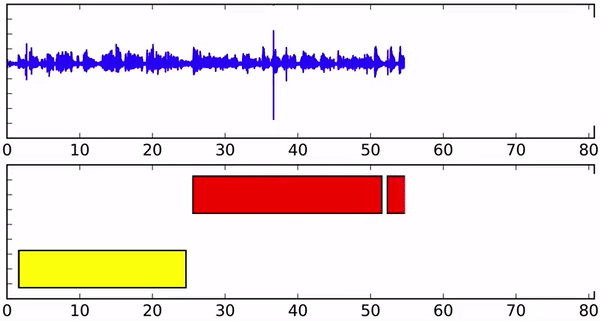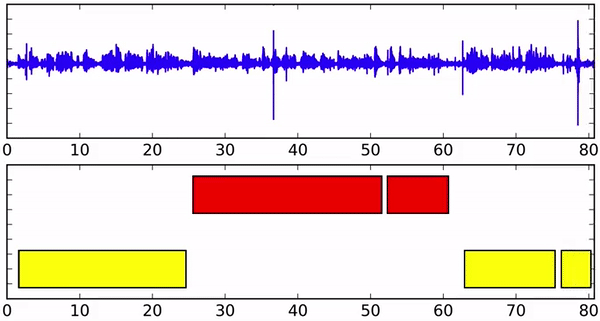
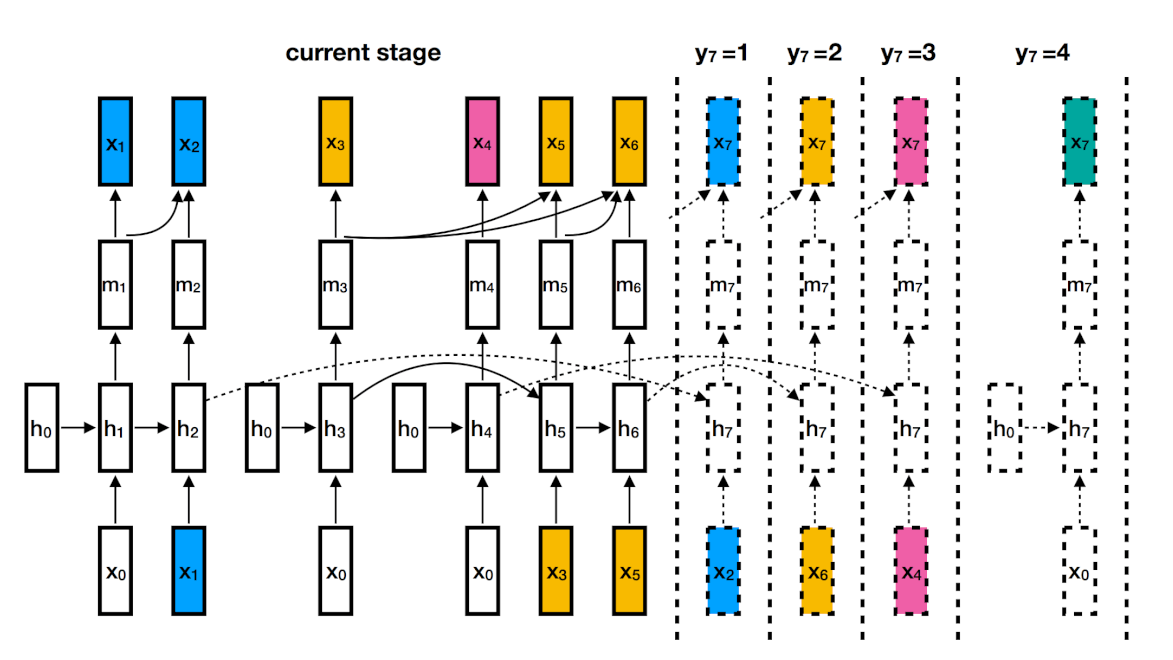
Исследователи создали алгоритм на базе рекуррентной нейронной сети. Для каждого говорящего используется отдельная RNN. Рекуррентная нейросеть моделирует математические представления слов и фраз и постоянно обновляет данные при этом сохраняя состояние, полученное при обработке предыдущих элементов. Это позволяет модели изучать высокоуровневые признаки для каждого говорящего.
Результат
Работу алгоритма проверили с помощью тестирования NIST. Частота ошибок составила 7,6 %. Предыдущие подходы, использующие кластеризацию и глубокие нейронные сети, показали погрешность 8,8 % и 9,9%. Код модели доступен на GitHub.