
Команда исследователей из CUHK MMLab опубликовала OpenGame — первый агентный фреймворк для создания браузерных 2D-игр по текстовому описания. Проект полностью открытый: код фреймворка, веса модели GameCoder-27B и датасеты доступны на GitHub, а подробности — на странице проекта. Пользователь пишет что-то вроде «хочу платформер про ниндзя с двойным прыжком», а агент самостоятельно генерирует код, ресурсы и музыку. Звучит просто, но за этим стоит довольно сложная инженерная конструкция.

Почему это сложно — создать игру
Это кажется очевидным, но стоит это проговорить. Создание игры принципиально отличается от написания обычного кода. Игра — это не один файл, а взаимосвязанная многофайловая структура, где движок, физика, ассеты и логика должны работать строго согласованно. Авторы выделяют три основные причины, по которым обычные языковые модели с этим не справляются.
Первая — логическая несвязность: модель теряет общее состояние игрового цикла, и проект зависает или не запускается вовсе. Вторая — незнание движка: модели игнорируют готовые абстракции фреймворка Phaser и пишут всё с нуля, получая нерабочий код. Третья — рассогласованность файлов: даже если каждый файл выглядит правильно, проект ломается из-за несовпадающих ключей ассетов, неправильной инициализации сцен или пропущенных полей конфигурации. Именно с этим набором проблем и призван справиться OpenGame.
Как устроена архитектура OpenGame
Фреймворк состоит из трёх взаимосвязанных компонентов:
- специализированной языковой модели GameCoder-27B;
- агентного пайплайна из шести фаз;
- механизма накопления опыта через Game Skill.
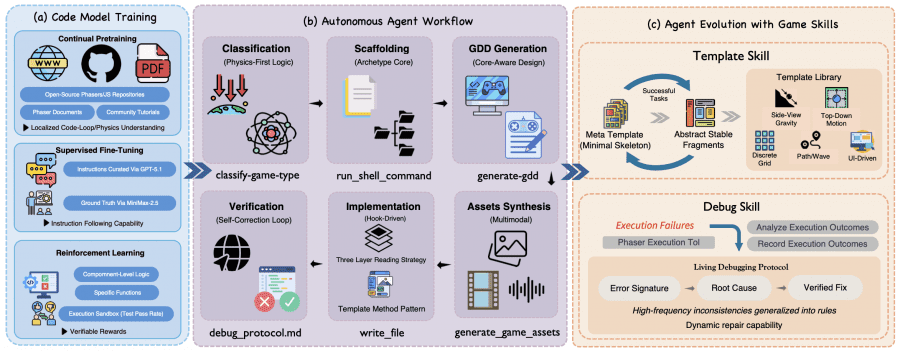
GameCoder-27B обучалась в три этапа поверх базовой модели Qwen3.5-27B. На этапе continual pre-training — дообучение на большом корпусе без разметки — модель получала данные из открытых репозиториев Phaser/JavaScript на GitHub и официальной документации. Это сформировало понимание игровых циклов, физики и управления состоянием. Затем в ходе supervised fine-tuning (обучение с учителем) авторы использовали синтетические пары вопрос-ответ: задания генерировал GPT-5.1, а эталонные решения создавал MiniMax-2.5. Наконец, на этапе обучения с подкреплением модель обучалась на исполнении кода. Она генерировала отдельные игровые модули: определение столкновений, конечные автоматы, а вознаграждение вычислялось на основе реального запуска тестов.
Агентный процесс состоит из шести последовательных фаз:
- классификация типа игры;
- построение каркаса проекта;
- генерация технического дизайн-документа (GDD);
- создание мультимодальных ассетов (изображения, музыка);
- написание кода;
- ревью кода с правками.
Классификация идёт не по жанру, а по физике — например, вопрос «падает ли персонаж без опоры?» определяет платформер, а «движется ли персонаж в любую сторону без прыжка?» — top-down игру. Это снижает количество ошибок при выборе шаблона.
Game Skill: как ИИ-агент учится на своих ошибках
Ключевое отличие OpenGame от простого промптинга — механизм Game Skill, который накапливает опыт между задачами. Он состоит из двух частей.
Template Skill начинается с одного базового шаблона M0 (минимальный каркас игры без жанровых допущений) и постепенно пополняет библиотеку L специализированными шаблонами. По мере решения задач агент выделяет стабильные, переиспользуемые фрагменты и добавляет их в библиотеку. В результате экспериментов стабильно возникали пять семейств: платформер с гравитацией, top-down с непрерывным движением, дискретная сетка, tower defense с волнами врагов и UI-ориентированные игры. Важно, что эти пять типов не задавались вручную — они проявились сами из повторяющихся паттернов.
Debug Skill ведёт «живой» протокол отладки P: каждый раз, когда что-то ломается, агент записывает сигнатуру ошибки, корневую причина, проверенное исправление. В следующий раз, встретив похожую проблему, агент не изобретает решение заново, а обращается к накопленному знанию. Кроме реакции на ошибки, пайплайн включает лёгкие предварительные проверки до компиляции, например, совпадают ли ключи ассетов в конфигурации с реальными файлами.
OpenGame-Bench: как оценивать играбельность
Обычные бенчмарки для кода проверяют статические входы-выходы, но игру так не оценить. Авторы создали OpenGame-Bench — пайплайн оценки на 150 задачах с уникальными промптами, охватывающими пять жанров. Оценка идёт через «безголовый» браузер (headless browser), который реально запускает сгенерированную игру. Код бенчмарка на момент написания текста не опубликован.
Метрики три:
- Build Health (BH) — компилируется ли проект и запускается без критических ошибок;
- Visual Usability (VU) — комбинация пиксельной эвристики (энтропия кадра, детекция движения) и оценки мультимодальной модели-судьи;
- Intent Alignment (IA) — насколько реализованы требования из исходного промпта, тоже через VLM-судью.
Все три метрики нормированы от 0 до 100.
Результаты: OpenGame против других подходов
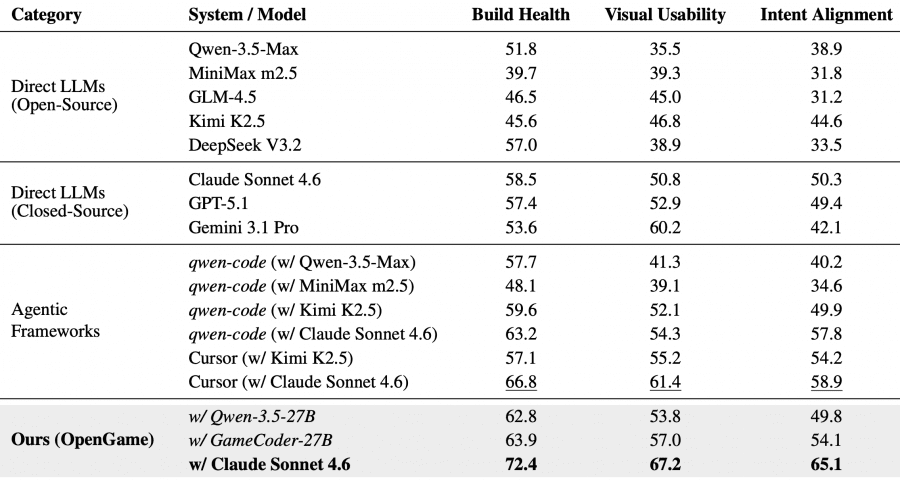
OpenGame с Claude Sonnet 4.6 в качестве движка для рассуждений достигает BH = 72.4, VU = 67.2, IA = 65.1 — это новый state-of-the-art. Ближайший конкурент Cursor с тем же бэкендом отстаёт на 5.6, 5.8 и 6.2 пункта соответственно. Наибольший отрыв именно по Intent Alignment (+6.2) — структурированное планирование и шаблонный скаффолдинг лучше сохраняют заявленную механику, чем свободная генерация.
Собственная модель GameCoder-27B в составе OpenGame показывает BH = 63.9, VU = 57.0, IA = 54.1 — это превосходит все прямые открытые и закрытые модели по метрикам Build Health и Intent Alignment, при этом модель значительно меньше проприетарных аналогов.
Тем не менее даже лучшая конфигурация оставляет около 34.9% механических требований частично или полностью невыполненными. Это говорит о реальной сложности задачи: перевести неоднозначный текстовый промпт в самосогласованную многофайловую структуру пока не удаётся надёжно ни одной модели.
Что важнее: модель или фреймворк?
Ablation study — анализ вклада каждого компонента — показывает, что основной прирост качества даёт именно архитектура фреймворка, а не более сильная базовая модель. Добавление continual pre-training к Qwen3.5-27B даёт небольшой прирост по Build Health. SFT добавляет +1.9 к Intent Alignment. RL с исполнением кода улучшает Visual Usability и Intent Alignment ещё немного. Но общий вклад трёх этапов обучения скромнее, чем вклад правильно выстроенного агентного процесса.
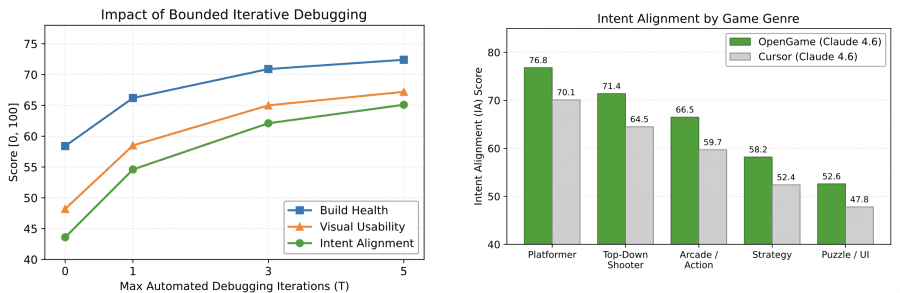
Интересен эффект итеративной отладки: при нулевой итерации (zero-shot generation) Build Health составляет всего 58.4. К третьей итерации большинство межфайловых несоответствий устранено, после пятой прирост выравнивается. Это значит, что самоисправление за несколько шагов — не опциональная фича, а необходимое условие работоспособности генерируемых проектов.
По жанрам лучше всего агент справляется с платформерами (IA = 76.8) и top-down шутерами (71.4) — там физика явно задаёт структуру, и специализированные шаблоны хорошо работают. Хуже всего обстоит дело со стратегиями (58.2) и головоломками/UI (52.6): логические ошибки в них часто не вызывают ни краша компилятора, ни runtime-ошибки, поэтому агент просто не получает сигнала об их наличии.
Вывод
OpenGame показывает, что надёжная генерация игр требует не просто более мощной языковой модели, а сочетания трёх вещей: доменно-специализированного обучения, структурированного агентного процесса и накапливаемых инженерных знаний об ошибках. Авторы надеются, что OpenGame станет открытой основой для исследований в области агентной разработки ПО — задач, где результат разворачивается во времени и требует реального исполнения, а не только статической проверки кода.








