В Google AI обучили Translatotron — нейросеть, которая принимает на вход аудиозапись с речью и на выходе отдает аудиозапись с той же фразой, переведенной на другой язык. Translatotron может как реплицировать голос человека на входной аудиозаписи, так и использовать стандартный голос. Примеры сгенерированных аудиозаписей можно послушать на странице статьи.
Разработки по переводу из речи в речь ведутся последние несколько десятков лет. Обычно такие системы делятся на три этапа: автоматическое распознавание речи (перевод из аудиозаписи в текст), машинный перевод (перевод текста на одном языке в текст на другом языке) и синтезирование аудиозаписи из текста. Именно таким образом работает Google Translate.
В своей работе исследователи из Google предлагают новый подход к speech-to-speech переводу. Модель напрямую переводит из аудиозаписи в аудиозапись и основывается на одной sequence-to-sequence модели с использованием механизма внимания. Такая архитектура имеет несколько преимуществ в сравнении с трехступенчатой — более быстрый инференс модели, нет накопления ошибок между разными моделями, возможность напрямую натренировать модель реплицировать голос на входной аудиозаписи.
Читайте также: Нейросеть переводит видео на 65 языков
Архитектура Translatotron
Translatotron принимает на вход спектограммы (визуальное представление аудиоволн) аудиозаписи и на выходе генерирует спектограммы. Два компонента Translatotron обучаются отдельно:
- vocoder (конвертирует спектограммы в аудиоволны);
- кодировщик речи спикера (опциональный компонент, который отвечает за репликацию голоса на входной аудиозаписи)
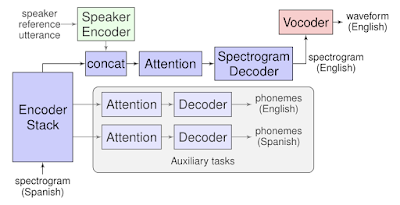
Во время обучения модель использует многозадачную целевую функцию, которая предсказывает транскрипты входной и целевой аудиозаписей одновременно с генерацией спектограмм. Однако во время инференса модели текстовые транскрипты не используются.
Оценка работы модели для перевода аудио
Исследователи для проверки работы модели использовали BLEU метрику. BLEU считалась по текстовым транскриптам, сгенерированным в системе по распознаванию речи. End-to-end подход пока уступает конвенциональному трехступенчатому по эффективности. Однако ценность работы в том, что ранее end-to-end решений в speech-to-speech задаче не было.