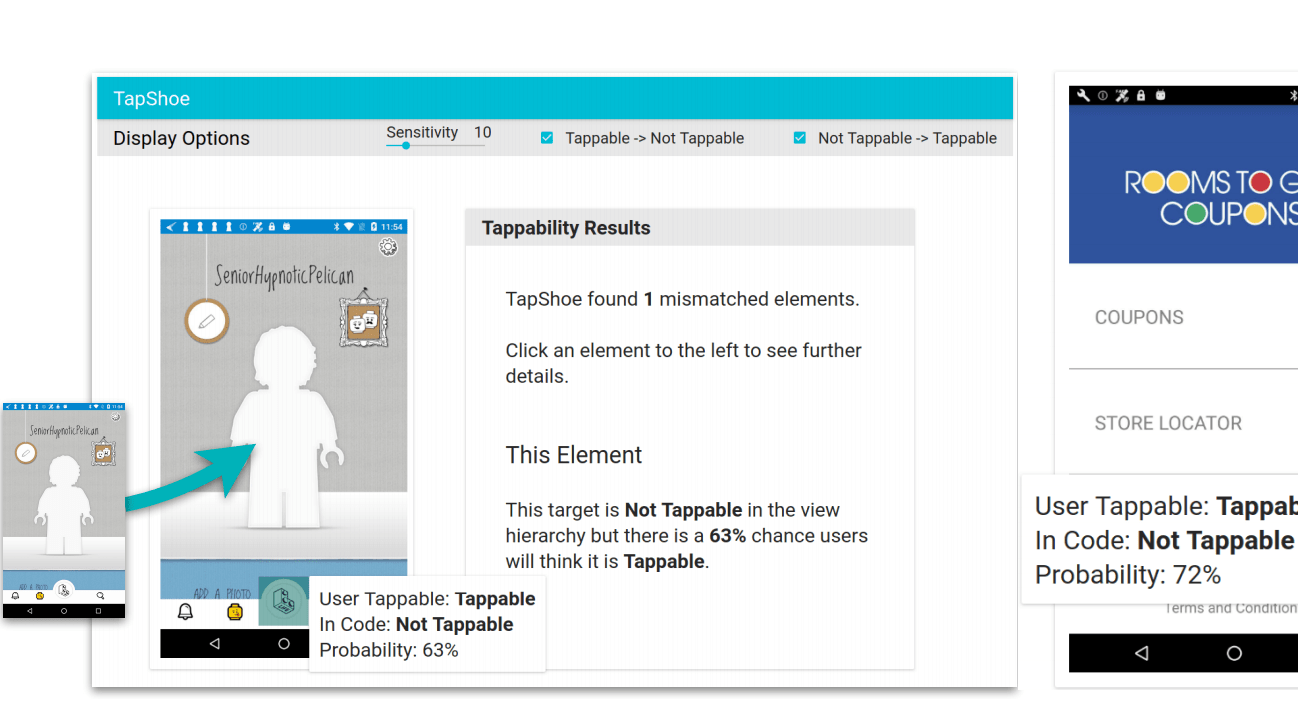
Нажатие на экран является наиболее популярным действием в мобильных интерфейсах. Оно инициирует разные команды: от открытия приложения до набора текста. Важной задачей в дизайне мобильных интерфейсов является выделение кликабельных элементов (например, кнопок). Неверный дизайн таких элементов негативно влияет на пользовательский опыт и может вызвать фрустрацию у пользователя.
Ранее задачу создания интерфейса решали качественными методами, с помощью пользовательского тестирования. Подобные исследования имеют ограничения, в том числе из-за временных и материальных затрат на их реализацию. Исследователи в Google предложили оптимизировать процесс тестирования с помощью нейросетей. Они разработали нейросеть, моделирующую человеческое мнение о кликабельности элемента — нажмет ли пользователь на элемент или не нажмет.
Описание проблемы
UX-дизайнеры часто используют визуальные детали, чтобы обозначить кликабельность элемента: синий цвет кнопки, подчеркивание для ссылки и т.п. Однако нет четких рамок, когда их уместно использовать и каким образом удобнее располагать кликабельные и некликабельные элементы, чтобы максимизировать удобство в использовании приложения.
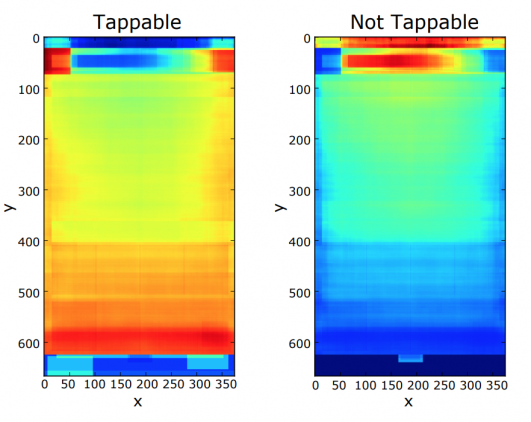
Исследователи проанализировали потенциальные характеристики, указывающие на удобство нажатия на элемент. Среди них расположение элемента, тип (поле для ввода текста, выпадающий список и т.п.), подпись, размер и цвет. Волонтеры разметили 20,000 элементов из 3,500 приложений на то, кликабельные они или нет.
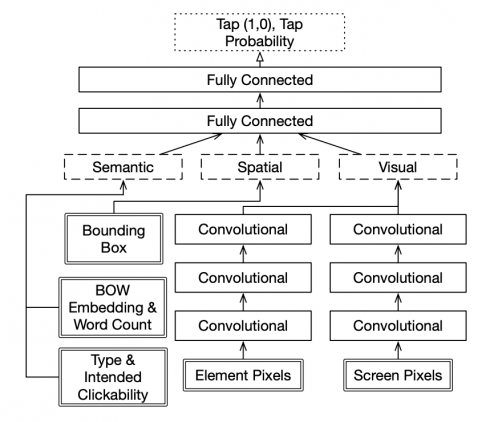
Архитектура решения
Процесс обучения сети делится на следующие шаги:
-
- На вход модели поступают пиксельные данные об элементе, об экране и описательные данные об элементе (эмбеддинг подписи, количество слов в подписи, тип элемента, фактическая кликабельность);
-
- Данные проходят через три конволюционных слоя с ReLU активацией и два полносвязных;
- На выходе модели элемент классифицируется как кликабельный или некликабельный в понимании пользователя.
Модель была реализована на Tensorflow и обучена на Tesla V100 GPU.
Результаты
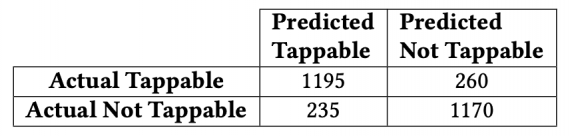
Модель была протестирована на 10-фолдовой кросс-валидации. Точность и recall модели составили 90.2% (стандартное отклонение: 0.3%) и 87.0% (стандартное отклонение: 1.6%) соответственно.
Подобный подход может способствовать сокращению затрат на проведение тестирований приложений и на их разработку. Подробности реализации модели и проверки ее эффективности освещены в статье.









