
Cемантическая сегментация изображения означает присвоение каждому пикселю определенной метки. В этом заключается главное отличие сегментации от классификации, где всему изображению ставится в соответствие только одна метка. Сегментация работает со множеством объектов одного класса как с единым целым.
Семантическая сегментация позволяет разделить изображение на регионы или объекты, которые имеют схожее смысловое значение.
Инстанс-сегментация обрабатывает несколько объектов одного класса как различные объекты. Обычно инстанс-сегментация сложнее чем семантическая сегментация.
Перед вами перевод статьи A Simple Guide to Semantic Segmentation, автор — Bharath Raj. Ссылка на оригинал — в подвале статьи.

В статье разобраны классические и продвинутые методы семантической сегментации, основанные на глубоком обучении, варианты выбора функции потерь и применение алгоритмов сегментации в реальной жизни.
Классические методы семантической сегментации
До наступления эпохи глубокого обучения для сегментации применялись самые разнообразные техники обработки изображений в зависимости от области интересов. Некоторые популярные методы того времени представлены здесь.
Сегментация на основе градации серого
Наиболее простой способ семантической сегментации заключается в ручном кодировании правил или свойств, которым должна удовлетворять область, чтобы ей можно было приписать определенную метку. Эти правила могут быть оформлены как свойства пикселей, например, интенсивность серого цвета. Один из методов, использующих такую технику, называется алгоритмом разделения и объединения (Split and Merge). Этот алгоритм рекурсивно разделяет изображения на подобласти до тех пор, пока им не припишется определенная метка, затем смежные подобласти с одинаковыми метками объединяются.
Проблема, сопряженная с этим методом, заключается в том, что правила должны быть прописаны в коде вручную. Однако порой бывает невероятно сложно описать сложные классы, такие как «человек», с помощью лишь информации об интенсивности серого цвета. Следовательно, в работе с такими сложными объектами для правильного обучения представлениям необходимы методы извлечения признаков и оптимизации.
Условные случайные поля
Рассмотрим сегментацию изображения через обучение модели приписывать класс каждому пикселю. В случае, если модель не идеальна, можно получить результаты с зашумленной сегментацией, что зачастую невозможно в природе (например, пиксели котиков смешиваются с пикселями собак, как показано на изображении).
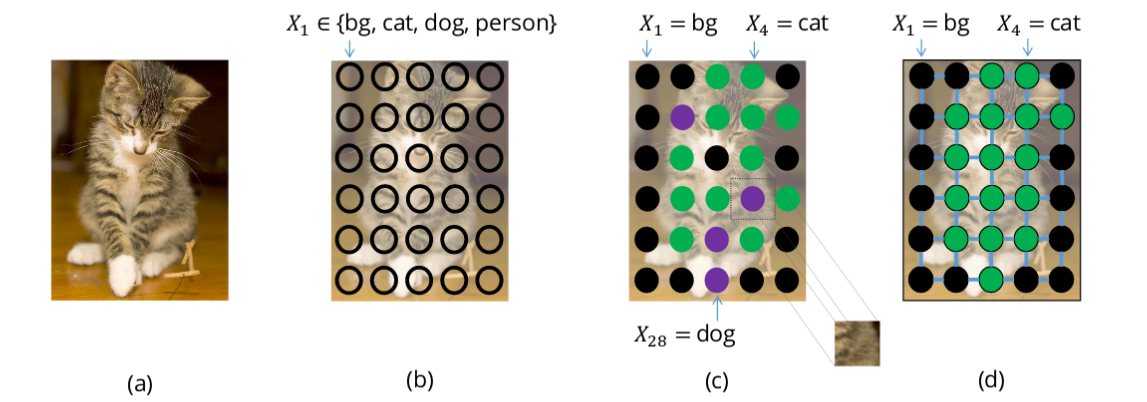
Этого можно избежать, если рассмотреть предыдущие взаимосвязи между пикселями. Идея состоит в том, что объекты непрерывны и, следовательно, близлежащие пиксели должны иметь одни и те же метки. Для моделирования такой взаимосвязи используют условные случайные поля (УСП).
УСП относятся к классу методов статистического моделирования, используемых для структурированных предсказаний. В отличие от классификаторов, перед предсказанием УСП принимают во внимание контекст, то есть взаимосвязь между пикселями. Из-за этого модель считается идеальным кандидатом для семантической сегментации изображения. В этом разделе рассматривается использование УСП для семантической сегментации.
Каждый пиксель изображения ассоциируется с конечным набором возможных состояний. В нашем случае целевые метки и будут набором возможных состояний. Затраты на присвоение состояния (метки u) единственному пикселю (х) носят название унарных затрат. Чтобы моделировать взаимосвязи между пикселями, мы также рассматриваем затраты, известные как попарные, на присвоение пары меток (u,v) паре пикселей (x,y). Мы можем рассматривать пары пикселей, которые являются непосредственными соседями (сеточная УСП), или же все работать со всеми парами пикселей изображения (плотные УСП).
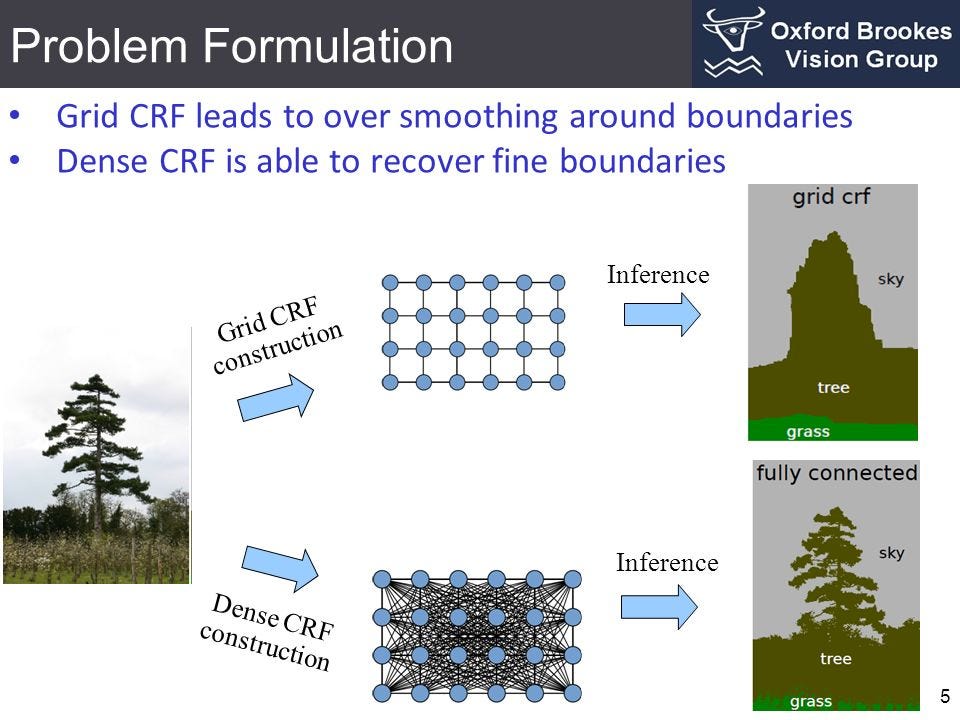
Сумма унарных и попарных затрат на все пиксели носит название энергии (или затрат/потерь) УСП. Чтобы получить хороший результат, это значение энергию УСП необходимо минимизировать.
Методы глубокого обучения
Глубокое обучение во многом упростило пайплайн выполнения семантической сегментации, одновременно показав впечатляющее качество. В этом разделе мы обсудим популярные архитектуры моделей и функции потерь, используемые для обучения этих моделей глубокого обучения.
Одна из самых простых и популярных архитектур, используемых для семантической сегментации, это полносверточная сеть (Fully Convolutional Network, FCN) . В статье “FCN для семантической сегментации” авторы используют FCN для первоначального преобразования входного изображения до меньшего размера (одновременно с этим увеличивая количество каналов) через серию сверток. Такой набор сверточных операций обычно называется кодировщик. Затем выход декодируется или через билинейную интерполяцию, или через серию транспонированных сверток, который носит название декодер.
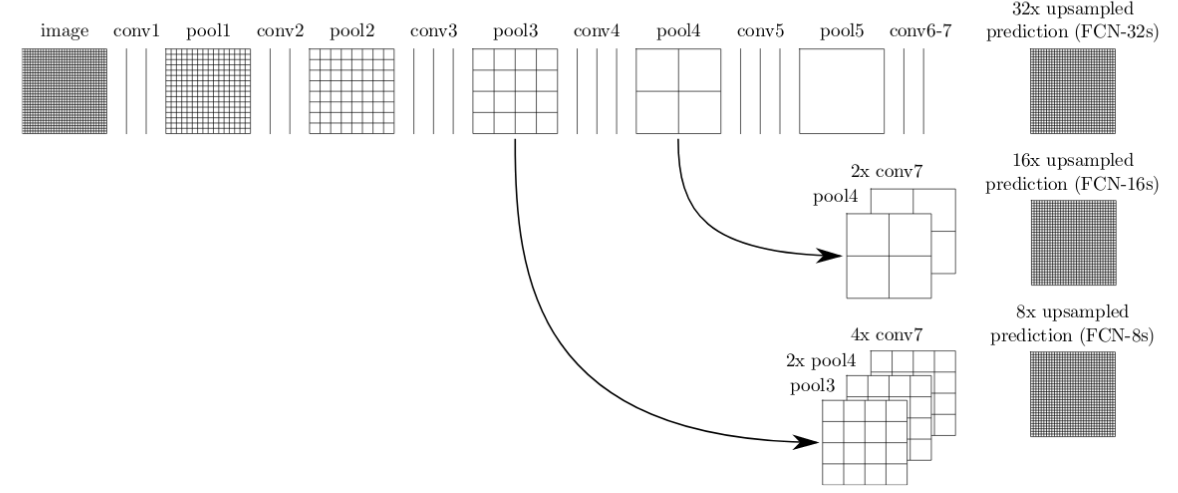
Такая базовая архитектура, несмотря на её эффективность, имеет ряд недостатков. Один из которых — наличие артефактов, расположенных в шахматном порядке, связанных с неравномерным перекрытием выходов в операции транспонированной свертки.
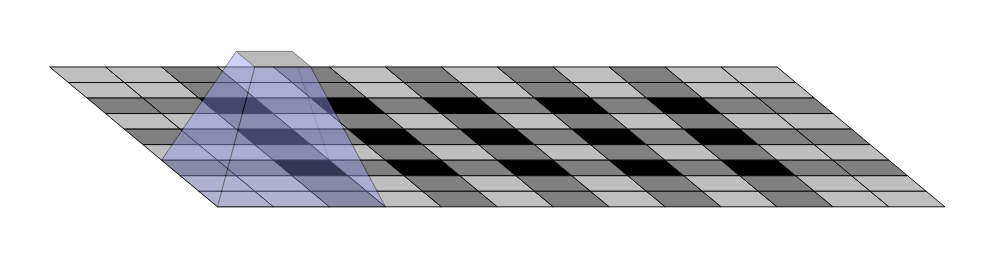
Другой недостаток связан с низкой разрешающей способностью по краям из-за потерь информации в процессе кодирования.
Для увеличения качества базовой FCN модели было предложено несколько решений. Ниже представлены некоторые из решений, которые доказали свою эффективность:
U-Net
Сеть U-Net представляет из себя улучшение простой FCN архитектуры. Сеть skip-связи между выходами с блоков свертки и соответствующими им входами блока транспонированной свертки на том же уровне.
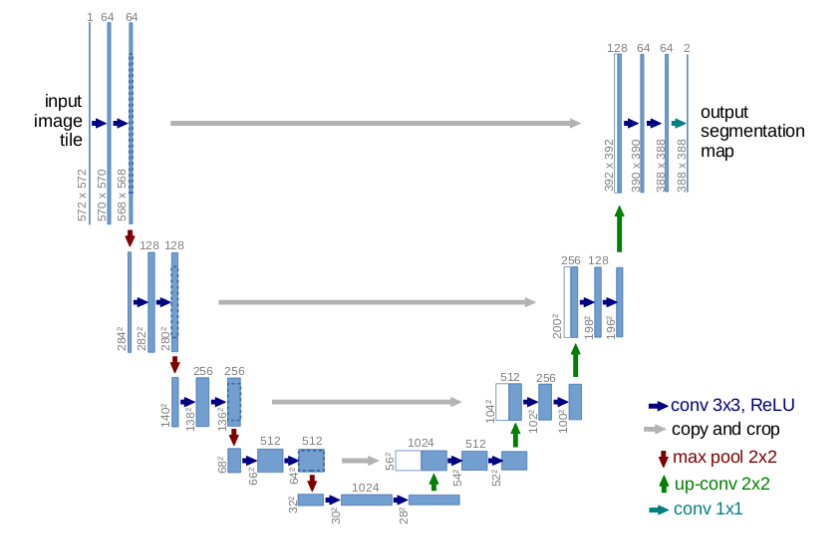
Skip-связи позволяют градиентам лучше распространяться и предоставлять информацию с различных масштабов размера изображения. Информация с больших масштабов (верхние слои) может помочь модели лучше классифицировать. В то время как информация с меньших масштабов (глубокие слои) помогает модели лучше сегментировать.
Модель тирамису
Эта модель похожа на U-Net за исключением того, что для прямой и транспонированной свертки здесь используются плотные блоки, как показано в работе DenseNet. Плотные блоки состоят из нескольких сверточных слоев, где в качестве входов на последующие слои используются отображения признаков со всех предыдущих слоев. Результирующая сеть чрезвычайно эффективна в смысле параметров и может лучше работать с признаками из старых слоев.
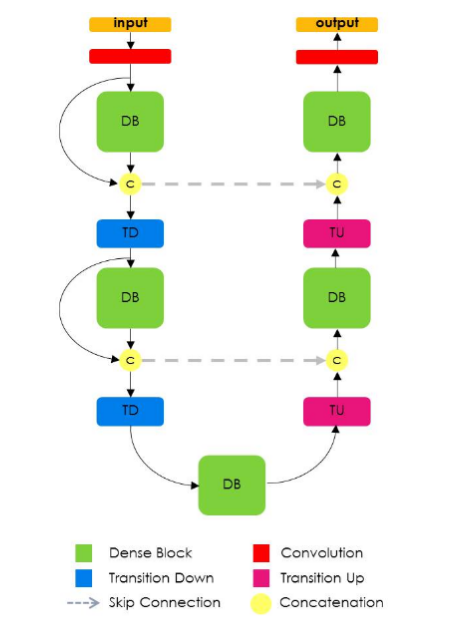
Недостаток такого метода, который является следствием самой природы операций объединения в нескольких фреймворках машинного обучений, заключается в низкой эффективности работы с памятью. Поэтому для работы с такой архитектурой требуются мощные кластеры GPU.
Многомасштабный метод
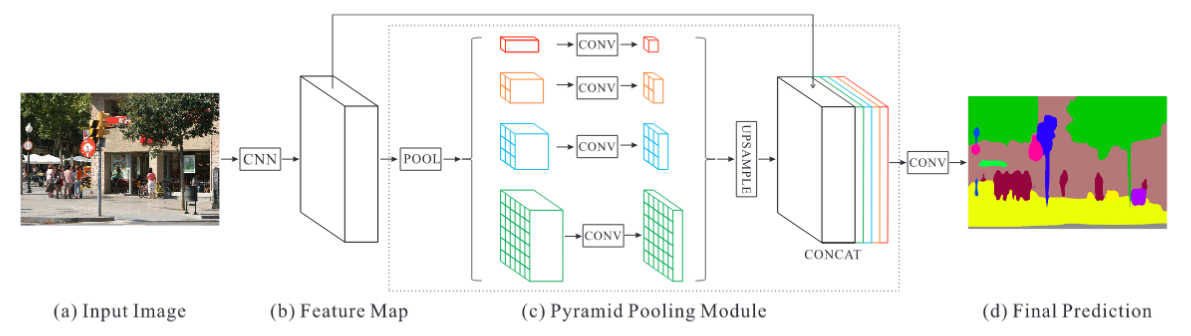
Некоторые модели глубокого обучения явным образом представляют методы работы с информацией из разных масштабов. Например, сеть Pyramid Scene Parsing (PSPNet) выполняет операцию объединения (через функцию max или average) при помощи кернелов различного размера и с различными шагами, примененных к выходным отображениям признаков с сверточной нейронной сети (например, ResNet). Далее при помощи билинейной интерполяции происходит пересчет размера всех выходов с pooling слоя и выходного отображения признаков с CNN; затем модель объединяет вдоль оси канала все новые выходы. Для генерации предсказания финальная свертка выполняется уже на объединенном выходе.
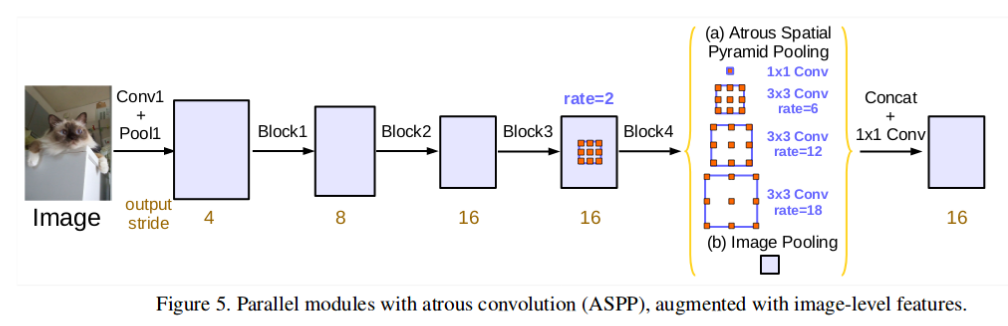
Модель расширенных сверток (Atrous Convolutions) представляет эффективный способ комбинировать признаки с нескольких масштабов без значительного увеличения количества параметров. Регулируя показатель расширения, один и тот же фильтр распределяет значение веса дальше в пространстве. Это позволяет изучать более общий контекст.
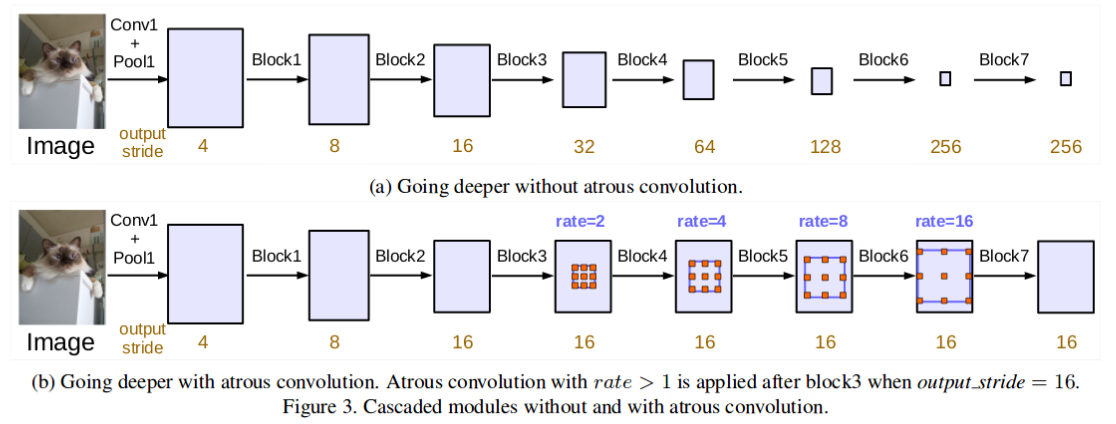
В работе DeepLabv3 используется модель расширенных сверток с различными показателями расширения, чтобы использовать информацию с разных масштабов без существенных потерь в размере изображения. Авторы проводили эксперименты с Atrous convolutions в режиме каскада (это показано на рисунке сверху), а также параллельном режиме в форме Atrous Spatial Pyramid Pooling (как показано ниже).
Гибридные методы
Некоторые методы используют сверточную нейросеть, чтобы извлекать признаки, которые потом используются как входы унарных затрат в плотные УСП. Такой гибридный метод показывает хорошие результаты из-за способности УСП моделировать связи между пикселями.
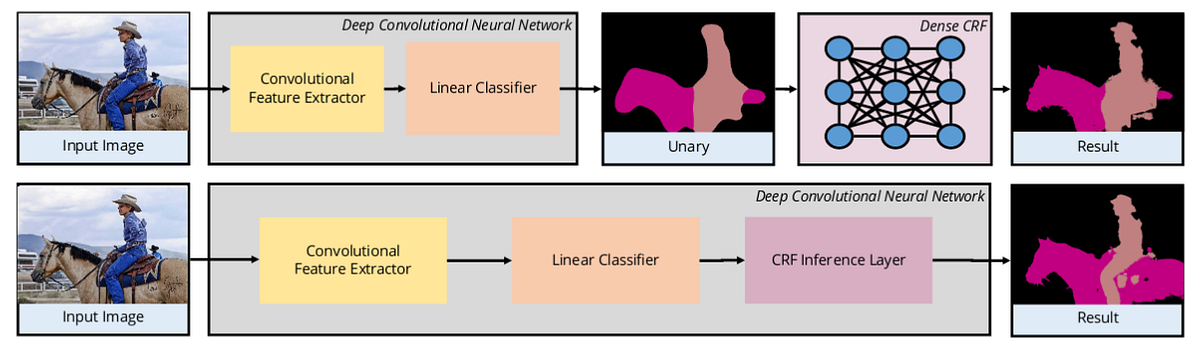
Некоторые методы используют УСП в самой нейронной сети, как это сделано в работе “CRF-as-RNN”, где плотные УСП (CRF) моделируются как рекуррентные нейронные сети (RNN). Это позволяет осуществлять обучение от начала до конца, как показано на рисунке сверху.
2. Функции потерь
В отличие от обычных классификаторов, для задач семантической сегментации могут быть использованы различные функции потерь, ниже представлены некоторые из них:
Перекрестная энтропия и метод softmax на пикселях
Метки для семантической сегментации имеют тот же размер, что и исходное изображение. Метка может быть представлена в one-hot форме, как представлено на рисунке:
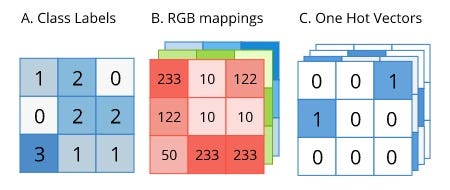
Так как метка уже находится в удобной one-hot форме, её можно сразу использовать для вычисления кросс-энтропии. Однако перед расчетом кросс-энтропии метод softmax должен быть применен к выходным предсказаниям, так как каждый пиксель может принадлежать к любому из классов.
Функция локальных потерь
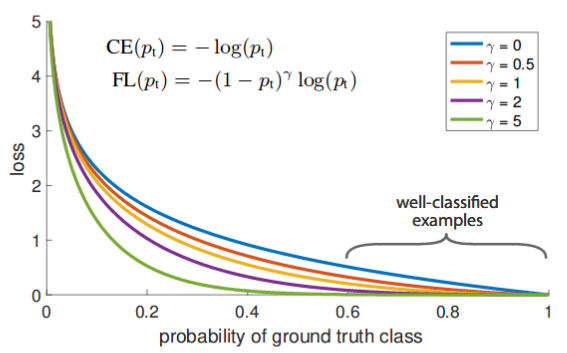
Функция локальных потерь, представленная в статье RetinaNet, является улучшением стандартной кросс-энтропийной функции для случаев с чрезвычайно сильной несбалансированностью классов.
Рассмотрим график уравнения стандартной функции потерь перекрестной энтропии, который представлен ниже (синий цвет). Даже в том случае, когда модель уверена в классе пикселя (скажем, на 80%), значение потерь примерно равно 0.3. С другой стороны, когда модель уверена в классе (потери почти равны нулю для 80%-ой уверенности), функция локальных потерь (фиолетовый цвет, параметр гамма равен 2) не штрафует её в такой степени.
Давайте на простом интуитивном примере рассмотрим, почему это важно. Предположим, что мы работаем с изображением, содержащим 10000 пикселей, для которого доступны только два класса: фоновый класс (0 в форме one-hot) и целевой (1 в форме one-hot). Предположим также, что 97% изображения занято фоном, и только 3% являются целевым классом. Теперь скажем, что модель на 80% уверена в пикселях, к которым приписан класс 0, а уверенность в целевом классе составляет лишь 30%.
Используя перекрестную энтропию, потери на пикселях фонового класса равны (97% от 10000) * 0.3, то есть 2850, а потери на пикселях целевого класса составляют (3% от 10000), то есть 360. Очевидно, что здесь доминируют потери, в которых модель наиболее уверена, а изучать целевой класс стимула нет. В сравнении с этим функция локальных потерь из-за фоновых пикселей (97% от 10000) * 0 равна 0. Это позволяет модели лучше учить целевой класс.
Функция потери Дайса
Это еще одна популярная функция потерь, используемая для решения задач семантической сегментации с чрезвычайной несбалансированностью классов. Впервые представленная в статье V-Net, функция Дайса используется для вычисления перекрытия между предсказанным и реальным классами. Коэффициент Дайса (D) считается по формуле:
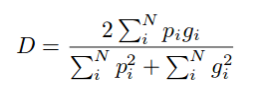
Наша цель заключается в максимизации перекрытия между предсказываемым классом и истинным (иначе говоря, мы хотим максимизировать коэффициент Дайса). Вместо этого мы будем заниматься более привычной минимизацией (1-D), так как большинство библиотек машинного обучения предоставляют широкие возможности только для минимизации.
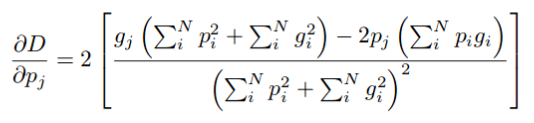
Даже несмотря на то, что функция потерь Дайса хорошо работает для выборок с несбалансированными классами, в формуле для вычисления производной в знаменателе находится квадратичный член. Поэтому, когда в знаменателе стоит маленькое число, получаются очень большие значения потерь, что ведет к неустойчивому обучению.
Семантическая сегментация: применение
Семантическая сегментация находит применения в самых разных областях реальной жизни. Ниже представлены некоторые известные кейсы использования такой сегментации.
Автономное вождение
Здесь семантическая сегментация используется для обнаружения дорожных разметок, других транспортных средств, людей, а также любых представляющих интерес объектов. Результат сегментации затем используется для принятия решений по правильному управлению транспортного средства.
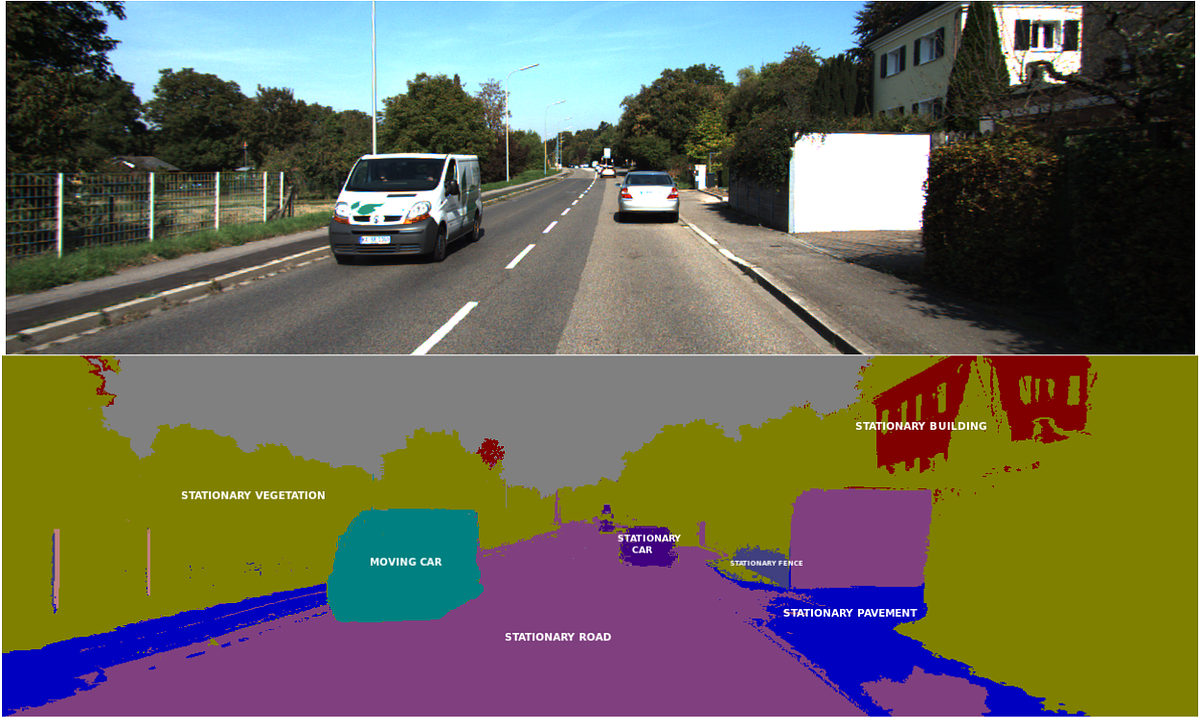
Недостатком такого применения технологии в автономном вождении является необходимость производить сегментацию в реальном времени. Решением может стать локальная интеграция GPU в транспортное средство. Кроме этого, чтобы повысить эффективность работы системы можно использовать более легкие нейронные сети (с меньшим количеством параметров).
Сегментация медицинских изображений
Семантическая сегментация используется для обнаружения скрытых элементов в медицинском снимке. Это особенно актуально для идентификации аномалий, таких как опухоль. Для таких приложений точность и низкая полнота (recall) алгоритмов имеют наибольшее значение.
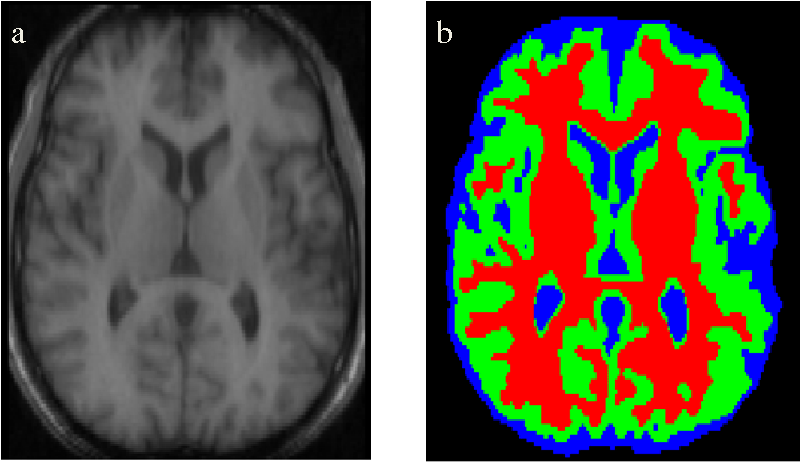
Мы также можем автоматизировать менее важные операции, такие как оценка объема органов с помощью трехмерной семантической сегментации снимков.
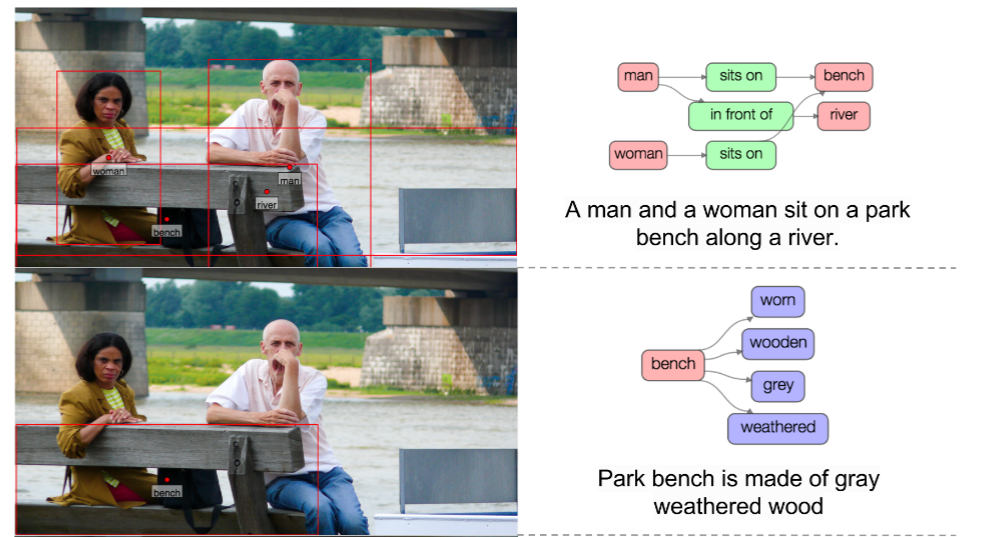
Задача понимания эпизода
Семантическая сегментация обычно используется в качестве базы для более сложных задач, таких как понимание эпизодов (Scene Understanding), а также в визуальных вопросно-ответных системах. Результатом работы алгоритмов понимания являются либо размеченный кадр, либо подпись к кадру или какому-либо объекту в нём. Пример такой сегментации представлен ниже.
Индустрия моды
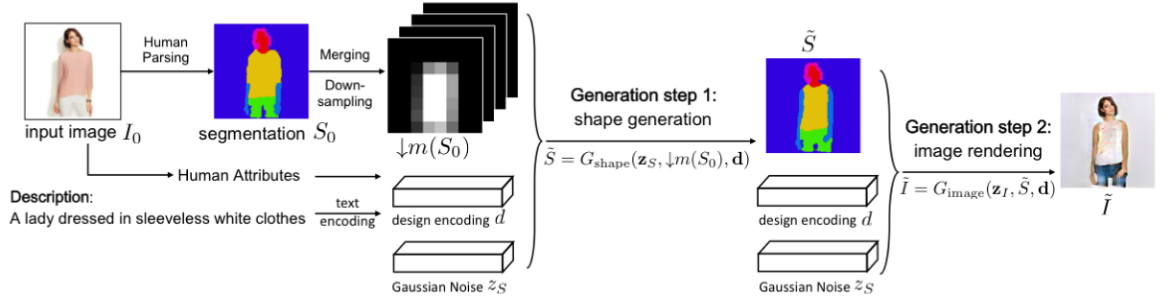
Семантическая сегментация используется в индустрии моды для извлечения с изображения элементов одежды, чтобы предложить похожие товары в магазине. Более продвинутые алгоритмы могут переодевать отдельные вещи прямо на изображении.
Обработка изображений со спутников
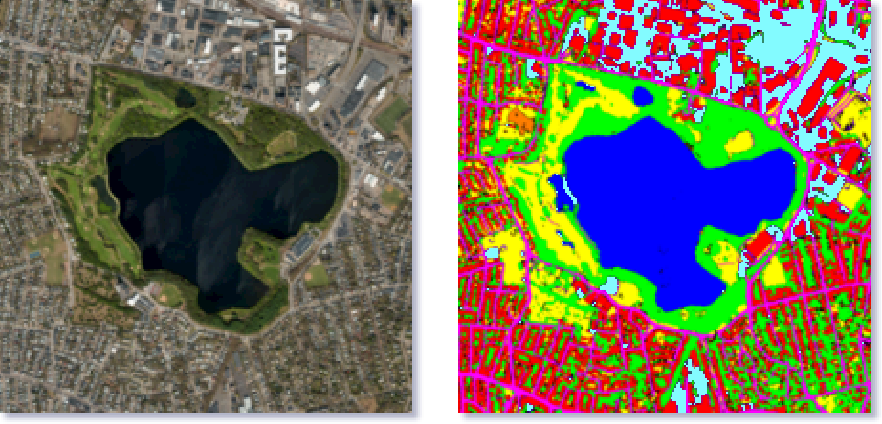
Семантическая сегментация используется для определения типов земной поверхности по спутниковым снимкам. Самый простой вариант использования технологии — определение контуров водоемов для предоставления более точной картографической информации. Продвинутые алгоритмы используются для нанесения на карту дорог, определения типов сельскохозяйственных культур, поиск свободных мест для парковки и так далее.
Заключение
Технологии глубокого обучения существенно улучшили и упростили алгоритмы семантической сегментации, проложив путь для более широкого применения в реальной жизни. Концепты приложений, показанных в статье, не являются исчерпывающими, так как сообщество исследователей постоянно стремится улучшить точность и производительность этих алгоритмов в реальном мире.






