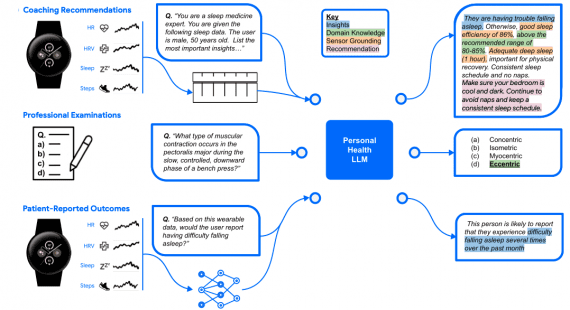
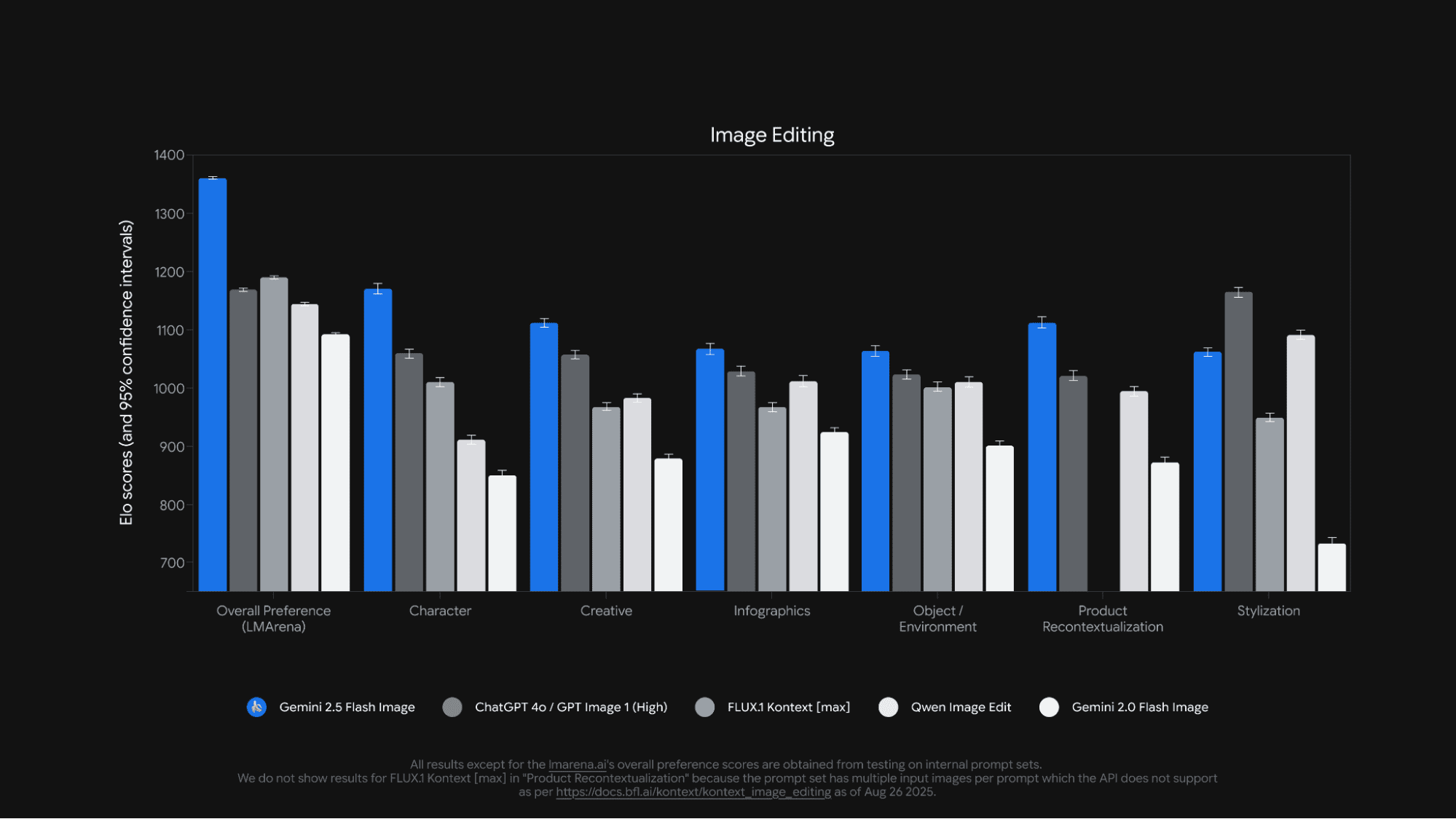
Google представила Gemini 2.5 Flash Image (с внутренним кодовым названием nano-banana) — модель для генерации и редактирования изображений. Модель поддерживает комбинирование нескольких изображений в одно, сохраняет консистентность персонажей между генерациями, поддерживает редактирование по текстовому описанию и использует знания Gemini для генерации контента.
Модель доступна через Google AI Studio, Gemini API и Vertex AI для корпоративных клиентов. Стоимость составляет $30.00 за 1 миллион output токенов, при этом каждое изображение считается как 1290 токенов ($0.039 за изображение).
Основные возможности
Консистентность персонажей

Ключевая проблема генерации изображений — сохранение внешнего вида персонажа или объекта в разных генерациях и сценах. Gemini 2.5 Flash Image позволяет помещать одного персонажа в разные окружения, демонстрировать продукт с других ракурсов в новых условиях или создавать единообразные брендовые материалы с сохранением идентичности объекта.
Google создала демо-приложение в Google AI Studio, показывающее возможности модели по поддержанию консистентности персонажей.
Редактирование по текстовым промптам
Модель умеет редактировать изображения по текстовому запросу. Gemini 2.5 Flash Image может размыть фон изображения, удалить пятно с футболки, убрать человека из фотографии, изменить позу субъекта, добавить цвет к черно-белой фотографии или реализовать другие изменения по текстовому описанию.
Для демонстрации этих возможностей Google разработала приложение для редактирования фотографий в AI Studio с элементами управления через интерфейс и промпты.

Использование знаний о мире
Традиционные модели генерации изображений создавали эстетически привлекательные результаты, но не обладали глубоким семантическим пониманием реального мира. Gemini 2.5 Flash Image использует знания Gemini о мире, что открывает новые сценарии применения.
Google создала демо-приложение в Google AI Studio, превращающее простое полотно в интерактивного репетитора. Приложение показывает способность модели читать и понимать рукописные диаграммы, помогать решать задачи и следовать сложным инструкциям редактирования за одно действие.
Слияние множественных изображений
Gemini 2.5 Flash Image понимает и объединяет несколько входных изображений. Модель может поместить объект в сцену, изменить стиль помещения с помощью цветовой схемы или текстуры, объединить изображения по единому промпту.
Для демонстрации слияния изображений Google разработала приложение в Google AI Studio, позволяющее перетаскивать объекты в новые сцены для быстрого создания фотореалистичных объединенных изображений.
Техническая реализация
Разработчики могут начать работу с моделью через документацию API. Модель находится в preview-режиме через Gemini API и Google AI Studio, стабильная версии ожидается в ближайшие недели.
Все изображения, созданные или отредактированные с помощью Gemini 2.5 Flash Image, содержат невидимый цифровой водяной знак SynthID для идентификации AI-generated или отредактированного контента.
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the gemini constellation"
image = Image.open('/path/to/image.png')
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")
Google активно работает над улучшением рендеринга длинных текстов, еще более надежной консистентности персонажей и фактуального представления мелких деталей в изображениях. Команда призывает пользователей оставлять обратную связь на форуме разработчиков или в X.