Transfer Learning — одно из направлений исследований в машинном обучении, которое изучает возможность применения знаний, полученных при решении одной задачи, к другой.
Для большинства задач компьютерного зрения не существует больших датасетов (от 50 000 изображений). Даже при экстремальных стратегиях аугментации данных трудно добиться высокой точности. Обучение таких сетей с миллионами параметров обычно имеет тенденцию перегружать модель. В этом случае Transfer learning готов прийти на помощь.
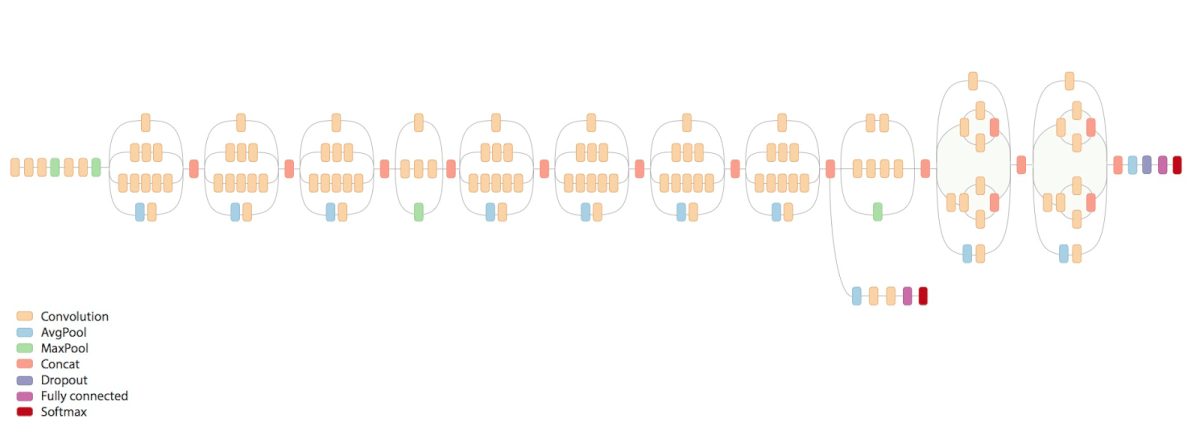
Что такое Transfer learning
- Лишь немногие обучают сверточные сети с нуля (с помощью случайной инициализации), потому что зачастую нужные датасеты отсутствуют. Таким образом, использование предварительно обученных весовых коэффициентов или фиксированного экстрактора свойств помогает разрешить большинство проблем.
- Сети с большим количеством слоев обучать дорого и долго. Самые сложные модели требуют нескольких недель для обучения с использованием сотен дорогостоящих графических процессоров.
- Определение структуры сети, методов и параметров обучения — настоящее искусство, так как соответствующей теории, которая поможет разобраться с этими проблемами, просто не существует.
Как может помочь Trasfer learning?
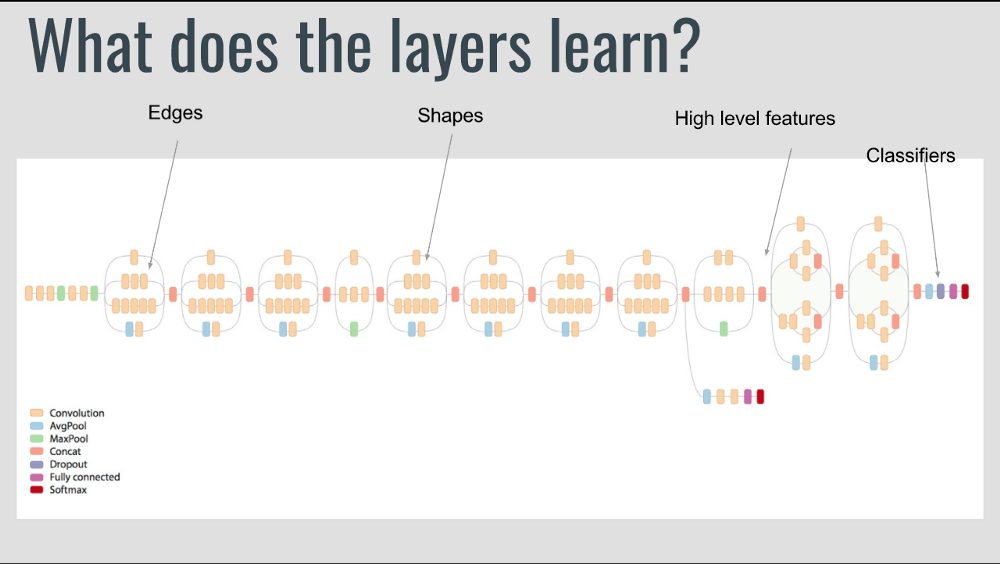
Если внимательно изучить процесс глубокого обучения, то станет понятно следующее: на первых слоях сети пытаются уловить самые простые закономерности, на средних слоях — наиболее важные, и на последних слоях — специфические детали. Такие обученные сети, как правило, полезны при решении других задач компьютерного зрения. Давайте посмотрим, как реализовать Transfer learning с использованием Keras для решения различных задач.
Простая реализация Transfer learning с помощью Keras
Помня, что свойства СonvNet являются более примитивными на первых слоях и усложняются с каждым последующим слоем, рассмотрим четыре типичных сценария.
1. Новый датасет небольшой и аналогичен исходному датасету
Если мы пытаемся обучить всю сеть сразу, возникает проблема перегрузки модели. Поскольку данные аналогичны исходным, мы ожидаем, что свойства более высокого уровня в ConvNet также будут иметь отношение к этому датасету. Следовательно, лучшей стратегией может быть обучение линейного классификатора по кодам CNN.
Таким образом, давайте отбросим все слои VGG19 и обучим только классификатор:
for layer in model.layers: layer.trainable = False
#Now we will be training only the classifiers (FC layers)
2. Новый датасет большой и аналогичен исходному
Так как у нас есть больше данных, есть большая уверенность в том, что мы не перегрузим модель, если попробуем выполнить точную настройку всей сети сразу:
for layer in model.layers: layer.trainable = True
#The default is already set to True. I have mentioned it here to make things clear.
Если вы хотите отбросить несколько первых слоев, формирующих самые примитивные свойства, это можно сделать с помощью следующего кода:
for layer in model.layers[:5]: layer.trainable = False.
# Here I am freezing the first 5 layers
3. Новый датасет небольшой и сильно отличается от исходного
Так как датасет небольшой, можно экспортировать свойства из более ранних слоев и обучить классификатор поверх них. Для этого требуются некоторые знания h5py:
Этот код должен помочь. Он будет извлекать свойства «block2_pool». Обычно это не очень полезно, поскольку слой имеет 64х64х128 свойств и обучение классификатора поверх них может и не помочь. Можно добавить несколько полносвязных слоев и обучить нейронную сеть поверх них. Это нужно делать в следующем порядке:
- Добавьте несколько FC слоев и выходной слой.
- Задайте весовые коэффициенты для более ранних слоев и отбросьте их.
- Обучите сеть.
4. Новый датасет большой и сильно отличается от исходного
Поскольку датасет большой, можно создать свою собственную сеть или использовать существующие. В этом случае надо действовать следующим образом.
- Обучайте сеть с использованием случайных инициализаций или используйте предварительно подготовленные весовые коэффициенты для начала. Второй вариант обычно является предпочтительным.
- Если вы используете другую сеть или немного модифицируете собственную в разных ее частях, следите за тем, чтобы имена переменных везде были одинаковыми.