9 Writing Tools and Techniques for More Natural English in Multilingual Teams
29 July 2026

9 Writing Tools and Techniques for More Natural English in Multilingual Teams
Natural English is not the same as “native-sounding” English Global teams increasingly use generative AI to draft emails, reports, proposals, support replies, and marketing copy. For professionals writing in a…
Bonsai 27B: 1-Bit Weights Put a 27B-Parameter Model on a Smartphone for the First Time
15 July 2026

Bonsai 27B: 1-Bit Weights Put a 27B-Parameter Model on a Smartphone for the First Time
PrismML, a startup founded by Caltech researchers, has announced Bonsai 27B — binary and ternary versions of the Qwen3.6-27B model that retain 90–95% of the original model’s quality while compressing…
MIRA: A World Model Fully Simulates Rocket League Without Requiring You to Install the Game Itself
8 July 2026

MIRA: A World Model Fully Simulates Rocket League Without Requiring You to Install the Game Itself
Teams from General Intuition, Kyutai, and Epic Games introduced MIRA — a world model that fully simulates the Rocket League game environment for four players at once and draws each…
Claude Sonnet 5: A Strong Agentic Upgrade, but No Clear Opus Replacement
1 July 2026

Claude Sonnet 5: A Strong Agentic Upgrade, but No Clear Opus Replacement
Anthropic has introduced Claude Sonnet 5, a new model in the Claude family that is also available to users on the free tier. It is designed for agentic tasks, programming,…
LFM2.5-230M: An Ultra-Compact Model Runs on a Raspberry Pi and Almost Any Modern Phone
29 June 2026

LFM2.5-230M: An Ultra-Compact Model Runs on a Raspberry Pi and Almost Any Modern Phone
Liquid AI released LFM2.5-230M — one of the smallest language models out there today, at just 230 million parameters. It’s compact enough to run on a small device without trouble:…
DreamX-World-5B: An Open-Source World Model with Camera Control, Text-Based Control, and Location Memory
17 June 2026

DreamX-World-5B: An Open-Source World Model with Camera Control, Text-Based Control, and Location Memory
The AMAP-ML team has published DreamX-World 1.0, an interactive generative world model that turns text or an image into a controllable video with precise camera control, memory of previously visited…
VibeThinker: 3B model reasons and codes at the level of flagship models
16 June 2026

VibeThinker: 3B model reasons and codes at the level of flagship models
Sina Weibo AI published VibeThinker-3B — a compact language model with just 3 billion parameters that matches flagship models DeepSeek V3.2 (671B), GLM-5 (744B), and Gemini 3 Pro on verifiable…
8 Best Gamma Alternatives for Creating Presentations Faster
8 Best Gamma Alternatives for Creating Presentations Faster
What Is Gamma? Gamma is an AI-powered tool that helps users create presentations, documents, and web-style content from prompts. It is known for its clean visual style, fast generation, and…
ESM Cambrian: protein language model outperformed Google’s AlphaFold3 and built the largest atlas of the protein world
4 June 2026

ESM Cambrian: protein language model outperformed Google’s AlphaFold3 and built the largest atlas of the protein world
A team of researchers from Biohub published ESM Cambrian (ESMC) — a language model for protein structure prediction and design that outperformed AlphaFold3 by Google on structure prediction accuracy, designed…
How to Use AI Motion Control for Professional Video Results
29 May 2026
How to Use AI Motion Control for Professional Video Results
Video production has always demanded a careful balance between creative vision and technical execution. For years, achieving smooth, realistic motion in AI-generated video meant wrestling with inconsistent outputs, repeated generation…
LLaVA-OneVision-2: Multimodal Model Analyzes Compressed Video Stream Through a Codec Instead of Frame Sampling
28 May 2026

LLaVA-OneVision-2: Multimodal Model Analyzes Compressed Video Stream Through a Codec Instead of Frame Sampling
Researchers from Glint Lab, AIM for Health Lab, and MVP Lab published LLaVA-OneVision-2 (LLaVA-OV-2) — a next-generation multimodal model that rethinks how a neural network “watches” video. Instead of slicing…
LongLive-2.0 — 5B Model Generates Long Video at 720p in Real Time
20 May 2026

LongLive-2.0 — 5B Model Generates Long Video at 720p in Real Time
Researchers from NVIDIA have published LongLive-2.0 — an infrastructure for training and running long video generation models using NVFP4 4-bit precision quantization. Quantization is the compression of model weights by…
How to Build a Video Content System Around a Single AI Avatar
20 May 2026
How to Build a Video Content System Around a Single AI Avatar
Performance marketers and content creators face a persistent bottleneck: the production treadmill. To stay relevant on platforms like TikTok, Instagram, and YouTube, you need a constant stream of high-quality video.…
OpenAI Codex Beginner’s Guide: Setup, Workflows, and Pricing
18 May 2026

OpenAI Codex Beginner’s Guide: Setup, Workflows, and Pricing
AI coding tools have changed dramatically over the past two years. Early assistants like GitHub Copilot mostly worked as advanced autocomplete systems — useful for speeding up repetitive coding, but…
SenseNova-U1: NEO-unify multimodal architecture works directly with pixels without VAE
14 May 2026

SenseNova-U1: NEO-unify multimodal architecture works directly with pixels without VAE
SenseNova introduced a new multimodal architecture, SenseNova-U1, which combines image understanding, generation, and editing inside a single transformer without a separate visual encoder or variational autoencoder. This approach removes the…
Claude Code: Complete Guide to Installation and Getting Started
8 May 2026

Claude Code: Complete Guide to Installation and Getting Started
Claude Code is an AI coding agent from Anthropic that works directly in your terminal or desktop app. Unlike autocomplete tools, it operates at the project level: reads files, edits…
OpenSeeker-v2: Best-in-Class Deep Research Agent Built by an Academic Team on Just 10,600 Samples
7 May 2026

OpenSeeker-v2: Best-in-Class Deep Research Agent Built by an Academic Team on Just 10,600 Samples
Researchers from Shanghai Jiao Tong University have proven that building a best-in-class deep research agent doesn’t require hundreds of billions of pre-training tokens or expensive reinforcement learning. Just 10,600 carefully…
OpenGame: AI Agent Generates Full Browser Games from Text Description
22 April 2026

OpenGame: AI Agent Generates Full Browser Games from Text Description
A team of researchers from CUHK MMLab published OpenGame — the first agentic framework for creating browser-based 2D games from natural language descriptions. The project is fully open: the framework…
ChatGPT Images 2.0: OpenAI Launches Image Generation Model With Reasoning, 2K Resolution, and Multilingual Text
22 April 2026

ChatGPT Images 2.0: OpenAI Launches Image Generation Model With Reasoning, 2K Resolution, and Multilingual Text
April 21, 2026, OpenAI released ChatGPT Images 2.0 powered by the gpt-image-2 model. According to LM Arena, the new model immediately took first place across all image generation categories with…
ClawGUI: the first open-source end-to-end framework for GUI agents — from training to real device
15 April 2026

ClawGUI: the first open-source end-to-end framework for GUI agents — from training to real device
Researchers from Zhejiang University have published ClawGUI — a fully open-source framework for building GUI agents that control applications through their visual interface, just like a human would: taps, swipes,…
ClawBench: The Best AI Agent Completed Only 33% of Real Everyday Online Tasks
13 April 2026
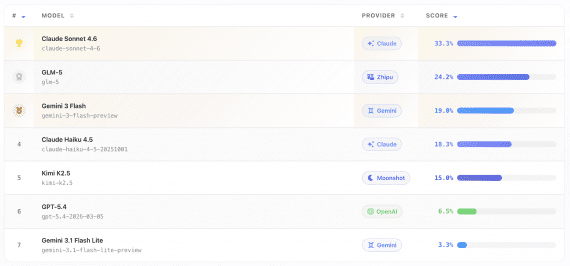
ClawBench: The Best AI Agent Completed Only 33% of Real Everyday Online Tasks
ClawBench — a benchmark testing whether AI agents can complete real everyday online tasks: booking a flight, applying for a job, placing an order. Results showed that even the strongest…