MLP-Mixer — архитектура от Google Brain, которая показала высокие результаты в компьютерном зрении, используя только линейные слои. Является сопоставимой альтернативой свёрточным нейросетям и трансформерам. Код доступен на Github.
Зачем это нужно
Сверточные нейронные сети (CNN), как и модели Vision Transformer (ViT), основанные на внимании, являются передовиками компьютерного зрения. Однако исследователи всё чаще задаются вопросом, в чём причина их эффективности.
Авторы показали, что ни свёртка, ни внимание не является обязательными для достижения высоких показателей в компьютерном зрении. Они разработали MLP-Mixer, архитектуру, основанную исключительно на многослойных перцептронах (multilayer perceptron, MLP).
Как это работает
В первом приближении, нейронные сети состоят из «слоёв», последовательно обрабатывающих выходные данные. Выход каждого слоя является входом для другого. CNN и ViT включают в себя слои, выполняющие различные операции, но основными для данных архитектур являются операции свёртки и внимания соответственно.
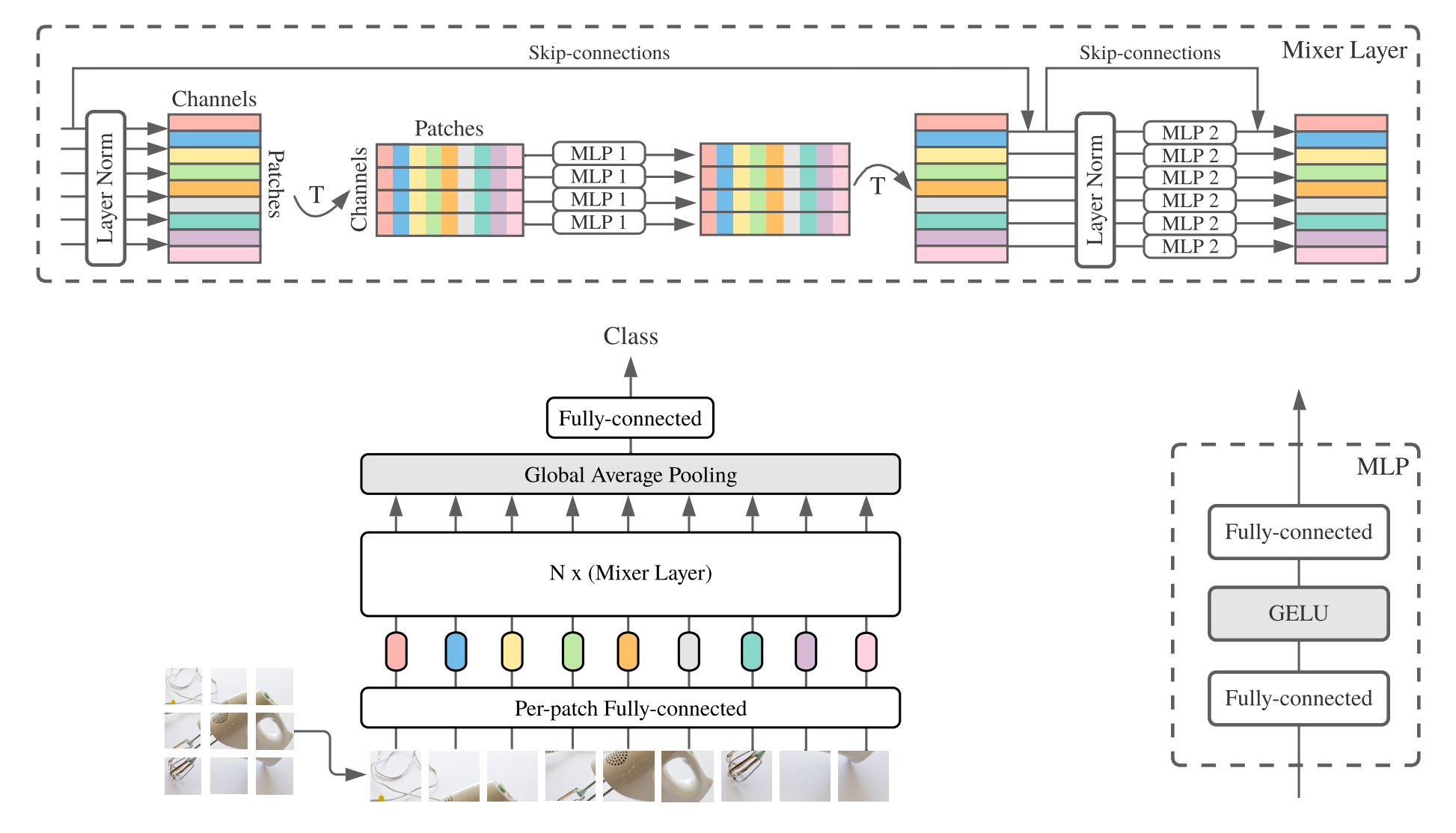
MLP-Mixer принимает на вход последовательность фрагментов изображения в формате «фрагменты × каналы» и поддерживает такую размерность данных в процессе обработки. MLP-Mixer содержит лишь два типа слоев:
- MLP, применяемый вдоль признаков изображения («смешивание» признаков);
- MLP, применяемый вдоль фрагментов изображения («смешивание» пространственной информации между фрагментами).
Это, в целом, напоминает архитектуру из уже упомянутого исследования: сеть применяет последовательность линейных слоёв, разделённых операцией транспонирования.
Результаты
В классификации изображений MLP-Mixer показал результаты, сопоставимые с современными архитектурами, при соблюдении двух условий:
- обучение на большом наборе данных;
- применение современных схем регуляризации (это ограничение также справедливо для ViT).
Например, по сравнению с архитектурой ViT, MLP-Mixer уступил 0.5% по точности на датасете ImageNet, но показал в 2.5 раза большую производительность. Причина такой высокой скорости довольно проста: использование линейных MLP-слоёв значительно быстрее, чем слоёв внимания.
Подробнее об исследовании можно прочитать в статье на arXiv.
Код с предобученными моделями и блокноты Google Colab также доступны в репозитории Github. Обратите внимание, на момент публикации MLP-Mixer находится в отдельной ветви репозитория «Vision Transformer».